

A number of improvements that have been introduced in vSphere HA and DRS in the last several years are impressive. vSphere 6.5 continues this tradition by bringing new features into HA Admission Control, by adding flexibility with HA Orchestrated Restart and by enabling DRS to make more intelligent balancing.
I will be trying a new format today. First, I will be explaining the challenges you might have had in previous vSphere releases and then I will show you how the new vSphere 6.5 HA & DRS features address those challenges.
Challenge: Default Admission Control settings do not ensure the same level of performance in the event of host failure
Description
“Admission Control is more than likely the most misunderstood concept… and because of this it is often disabled” – that’s my favorite phrase from the “vSphere HA and DRS technical deepdive” book by Duncan Epping and Frank Denneman. Based on my personal experience I would add that often people enable Admission Control (AC) using default settings without understanding how each of the AC modes fits into their environment. Moreover, admins rarely review these settings as the infrastructure grows.
Before explaining what vSphere 6.5 brings to HA & DRS let’s just quickly refresh what Admission Control is and what types of AC there are.
According to vSphere Documentation, “vCenter Server uses admission control to ensure that sufficient resources are available in a cluster to provide failover protection and to ensure that virtual machine resource reservations are respected.”
Do you see a problem here? Many admins don’t recognize a potential issue as well. Admission Control doesn’t care about virtual machines’ performance after failing them over to other hosts. All AC requires is that there are just enough resources to be able to power on VMs and to provide corresponding CPU and RAM reservations. If there is not enough compute power after a host failure to ensure the same level of VM performance Admission Control wouldn’t bother to tell you about it. Therefore, you either have to assign sufficient reservations to all VMs (ugh, nasty practice) or to use dedicated failover host. The former results in resource micromanagement and huge operational overhead. The latter means you will be wasting your compute resources on a hot-standby host.
There are three AC policies in vSphere 6.5:
- Slot policy
As policy name states it uses slot size to calculate an amount of available resources for a failed host scenario. The slot size can be either defined automatically by using the largest reservations for RAM and vCPU. Alternatively, you can define a custom slot size. The problem with this policy is that it is not flexible and one VM with large reservations may skew calculations, which in turn will prevent an admin from powering on VMs when there are still plenty of resources.
- Cluster Resource Percentage
This is the most recommended policy and more flexible than slot based policy. However, it still uses VMs’ reservations and overhead for its calculations. It doesn’t take into consideration the amount of Active RAM. Imagine you have a virtual machine with 4 x vCPU and 16GB of RAM. If you are not using reservations Admission Control will only reserve 4 x 32MHz for vCPU and 125MB for RAM. That is all Admission Control needs to power on the VM. Therefore, AC will use these numbers only in its calculations. But why would you need to power on VMs if you cannot be sure VMs have enough resources to provide services? What’s the point of running VM if it cannot get resources to run the applications?
So, if you want to be sure the VMs can still deliver the services after the host failure you can’t rely on default Admission Control settings. The vSphere admin will need to figure out the vCPU /RAM reservations for all VMs, assign them and then update these values as needed. That’s not something you can easily automate and it could be easily overlooked.
Another problem with this policy was the requirement to adjust reserved percentage has to be adjusted every time the number of hosts in the cluster change. For instance, with 5 hosts you want to reserve 20% of CPU and RAM to cover 1 host failure. With 10 hosts in the cluster, you will need only 10% of resources reserved for the same scenario.
- Dedicated Failover host
That was my personal choice for AC mode in pre-vSphere 6.5 when you have a cluster of 10 hosts and more. This policy ensures VMs can be restarted during the host failure and that VMs will get the same performance, provided that dedicated failover host has the same specs as other hosts in the cluster.
If you want to have a bit more details on AC policies and their corresponding drawbacks have a look at my blog post Why I prefer to disable vSphere HA Admission Control
I also strongly recommend reading “vSphere HA and DRS technical deepdive” book by Duncan and Frank.
Solution
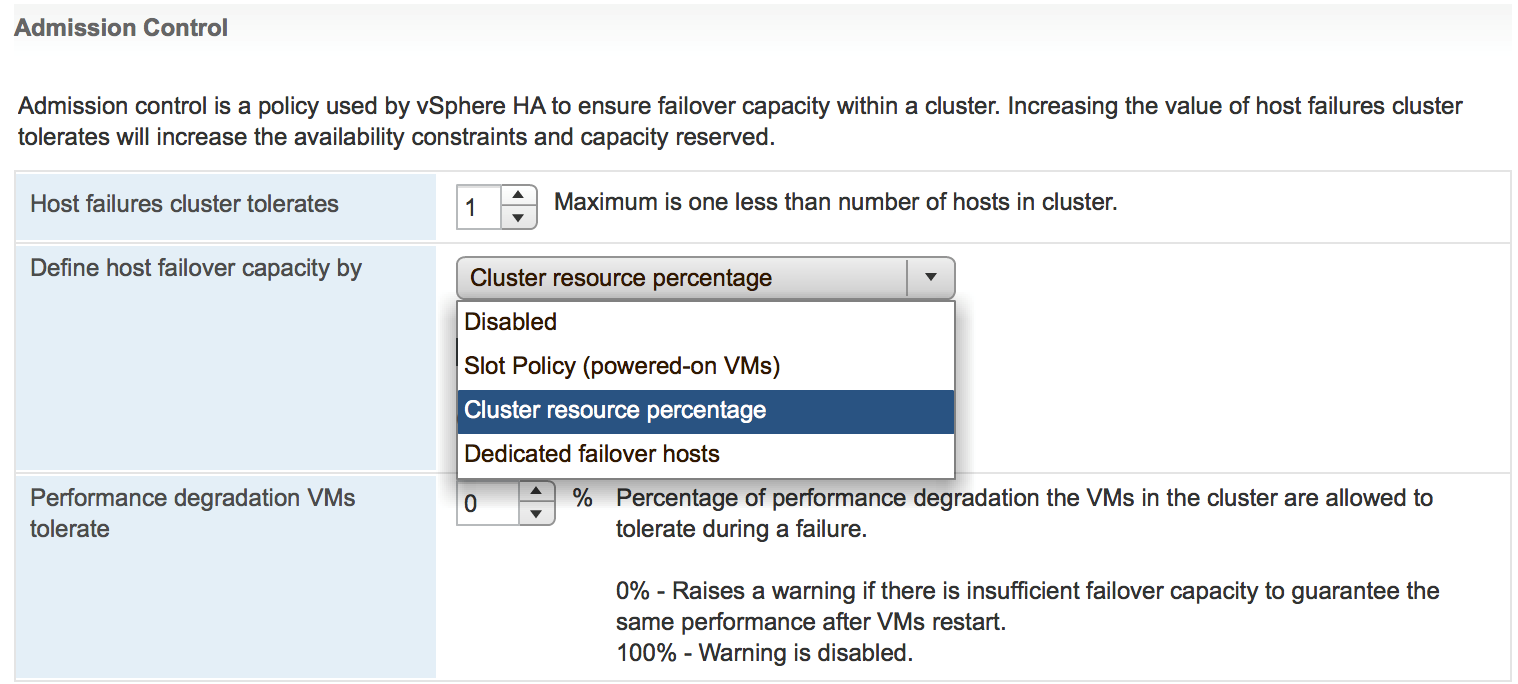
Here is what VMware came up with to address these issues. There is a new setting now in HA Admission Control called ‘Performance Degradation VMs tolerate’.
The default value for this setting is 100% which means Admission Control will ignore any possible performance impact of the host failure.
Setting it to 0% will generate a warning if AC thinks there is insufficient failover capacity to ensure the same performance after VMs are failed over. This is achieved through monitoring of actual usage of CPU and RAM resources.
Here is a quick example. Let’s say your 4 x node cluster has 100GHz and 100GB of RAM. The ‘Performance Degradation VMs tolerate’ is set to 10%. ‘Host failures cluster tolerate’ is set to 1.
The actual usage is 60% of CPU and 90% of RAM resources.
AC assumes that after the host failure it will only have 75% of resources available. The cluster will have enough CPU resources to cover the current CPU usage, but actively used RAM will be 15GB higher than available RAM. 15GB is more than 10% of used RAM = 9GB. So, that will make AC trigger a warning.
In pre-vSphere 6.5 this won’t be brought up as an issue for the simple reason that AC only monitored VMs’ overhead and reservations.
Just to make Admission Control even better VMware made percentage recalculations automatic. Whenever you add or remove the host from the cluster AC will adjust the percentage of reserved failover capacity.
Note – Reading documentation it is not clear at the moment whether Admission Control uses Active memory metric + Overhead to calculate actually used memory or Dynamic DRS memory entitlement which consists of Active Memory + 25% of (Consumed memory – Active memory) + Overhead. I personally hope it uses Dynamic DRS memory entitlement as it seems to me as a more realistic value. I will update this article once I get this information confirmed.
Challenge: HA mechanism is reactive only
Description
vSphere HA has proven to be a very simple and at the same time reliable technique to protect virtual machines against the failure of the hardware. When the ESXi host becomes irresponsive, isolated, partitioned or simply experiences power outage all the virtual machines residing on this server can be restarted on other hosts in the cluster. As you can see HA used to be a reactive mechanism. It helps to cope with catastrophic health events and obviously improves the availability of the virtual machines, but it still results in short interruption of the services running in this VM.
Solution
In vSphere 6.5 VMware improved clusters’ high availability with proactive logic. The funny fact is that even though this new feature is called Proactive HA it is actually more an extension of DRS functionality.
The main new component of Proactive HA is a web client plugin provided by server vendor, e.g. HPE or Dell, which passes component health data to DRS. The plugin covers the following components of the servers:
- Networking
- Power
- Memory
- Local Storage
- Fans
Based on the type of the failure there could be two types of the failure – Moderate and Severe. One thing to note here – the conditions for each of the failure type are actually defined by vendors, not by VMware.
Proactive HA also introduces new state for the ESXi server – Quarantine Mode (QM). When the host is placed in QM mode the DRS will try to evacuate all VMs off this host provided that there is no performance impact on the cluster workload. For instance, if the migrated VMs don’t cause any compute resource contention in the cluster that all VMs will be migrated. Otherwise, if there are not enough resources DRS will keep some of the VMs on the affected host but will try to keep the load on the ESXi server at the minimum. You can consider QM as a “soft” maintenance mode.
There are three Proactive HA responses HA:
- Quarantine mode for all failures
No matter what type of failure the ESXi server is experiencing the vCenter will put this host in QM which will make DRS migrate all VMs off the degraded server as long as there is no contention
- Quarantine mode for moderate and Maintenance mode for severe failures
The name is self-explanatory. This mixed response ensures that the performance of other VMs is not impacted, but may put some VMs at risk by keeping them running on the degraded host if there are not enough resources in the cluster.
- Maintenance mode for all failures
This response will ensure that no VMs run on a degraded ESXi server.
There are just 2 requirements for Proactive HA:
- You should have hardware monitor plugin installed in your environment. So far 3 vendors released this software for their servers – Dell, Cisco and HPE, but other vendors are working on it as well
- DRS has to be enabled on the cluster
When vendor’s health plugin recognizes partial failure, which leads to a loss of redundancy, e.g. one NIC reports disconnected or one PSU fails it will make an API call to vCenter to inform about Proactive HA failure. Based on that information vCenter will trigger one of the responses you chose to configure.
You can also use Proactive HA in Manual mode, which will produce DRS recommendations but will not vMotion any of the VMs.
Since it is DRS feature which is a part of vCenter functionality, Proactive HA is supported on all versions of ESXi servers supported by vCenter 6.5. So, you don’t have to rush upgrading your hosts to get Proactive HA.
A couple of things to keep in mind when using Proactive HA:
- If the root cause of the problem is resolved host will be taken from the quarantine mode automatically. However, If the host is placed into maintenance mode it won’t be taken out of MM automatically after the issues are fixed. This was done on purpose as you would very probably want to test the host before putting VMs back on it
- It is supported with vSAN, but currently, vSAN doesn’t take much advantage of Proactive HA. For instance, when the host is placed in QM it won’t trigger data evacuation. However, if vCenter puts the host into maintenance mode the vSAN will use default maintenance mode – Ensure Accessibility. This behavior can be changed using advanced setting DefaultHostDecommissionMode.
In vSphere 6.5 – HA & DRS improvements – Part II I will talk about HA Orchestrated Restarts, new DRS balancing options and Predictive DRS with vRealize Operations Manager 6.4.
