

INTRODUCTION
In my previous article, I measured SQL Server Basic Availability Groups (BAG) performance. This, as it comes from the name, addresses SQL Cluster Failover Cluster Instance (FCI) performance. I expect SQL Server FCI to exhibit two times higher performance than BAG.
Before I start, I’d like to tell you one important thing about this measurement. SQL Server FCI database resides on a StarWind virtual device. Why did I choose StarWind? Because I got their NFR license some time ago and decided to give this software-defined storage solution a shot. Let’s just hope that it won’t limit SQL Server FCI performance.
THE TOOLKIT USED
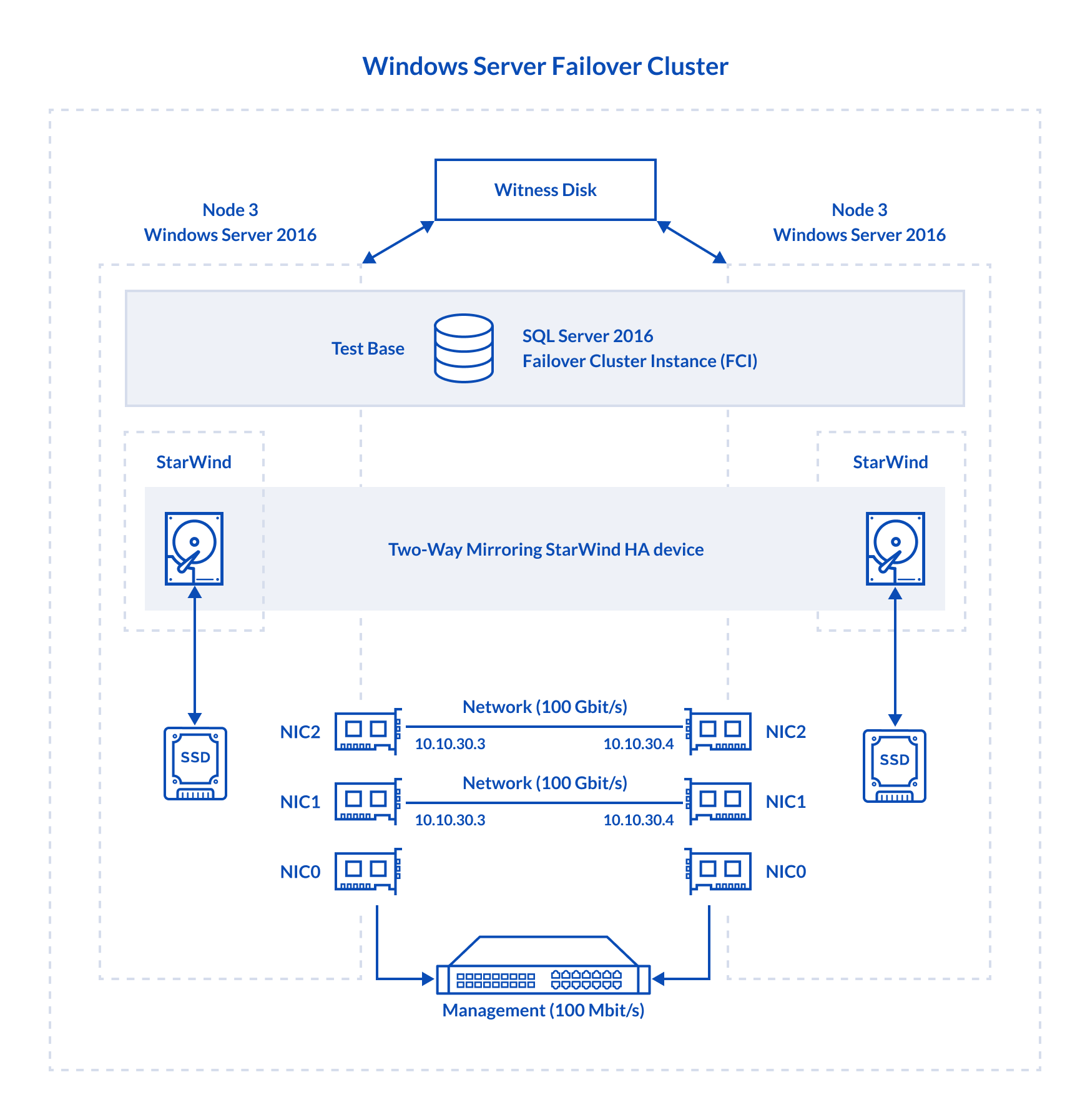
Now, let’s take a closer look at the setup configuration that I used for measuring SQL Server FCI performance:
Node 3, Node 4: Both are identical from the hardware point of view
Dell R730, CPU 2x Intel Xeon E5-2697 v3 @ 2.60 GHz , RAM 128GB
Storage: 1x Intel SSD DC S3500 480GB
LAN: 1x Broadcom NetXtreme Gigabit Ethernet, 2x Mellanox ConnectX-4 100Gbit/s
OS: Windows Server 2016 Datacenter
Database Management System: Microsoft SQL Server 2016
VSAN: StarWind Virtual SAN for Hyper-V (Windows-based) StarWind_8.0-R6U3-release
TESTING SQL SERVER FCI PERFORMANCE
Before you create a database
First, you need to deploy Windows Server Failover cluster and install StarWind Virtual SAN for Hyper-V. Next, create StarWind Virtual Device 1GB intended for the Disk Witness (Cluster Disk1) that is connected to both Hyper-V nodes over iSCSI (1x local iSCSI session, 1x Network iSCSI session).
Create the second StarWind Virtual Device on top of Intel SSD DC S3500. This device is intended for SQL Server FCI database; so, obviously, it should have a larger volume (I set it to 445 GB here). Connect this Virtual Device over iSCSI to both nodes (3x local iSCSI session, 2x Network iSCSI session). Create the Cluster Disk2 on that disk.
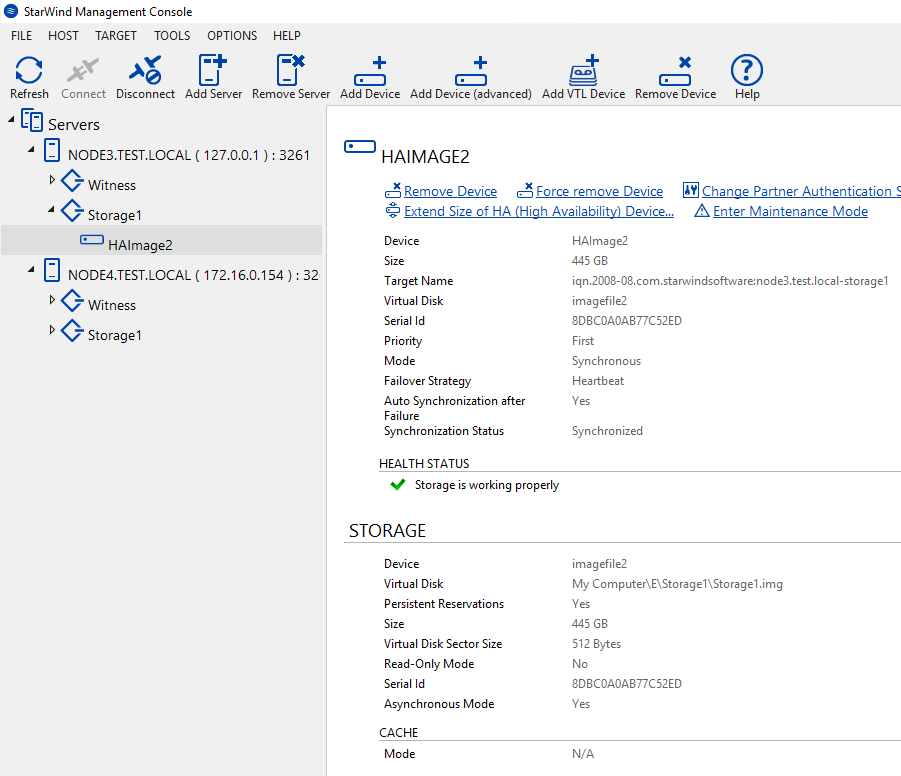
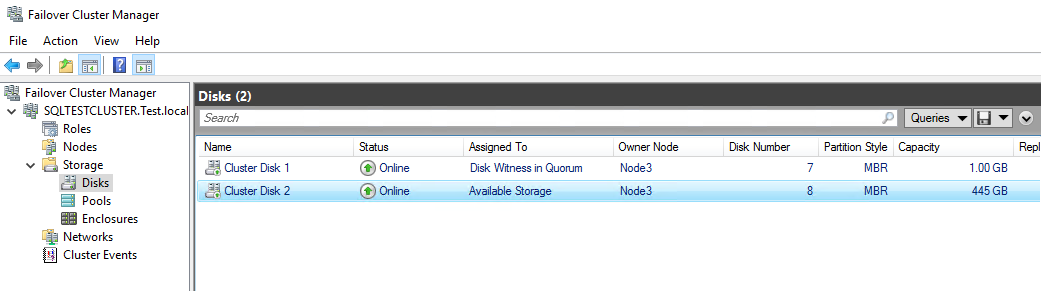
Setting up SQL Server FCI
Now, let’s go through 2-node SQL Server FCI deployment.
Install SQL Server 2016 on Node 3 from the preinstalled image. On the whole, installation and setting up processes are similar to ones for BAG. Anyway, I will describe the whole process to make reproducing my study easier.
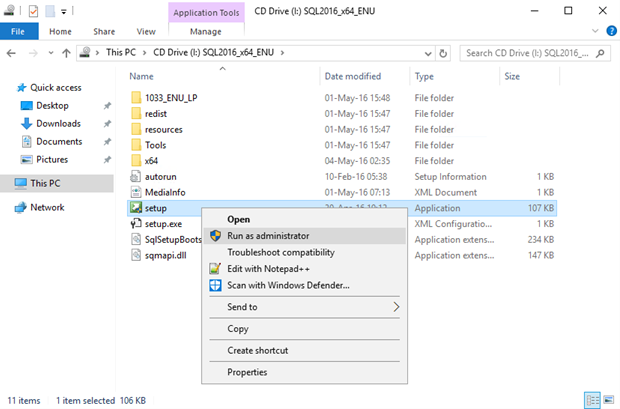
Select the New SQL Server failover cluster installation option.
Press Next after Failover Cluster Rules are successfully installed.
At the next step, when SQL Server 2016 setup wizard asks you to specify the product key, select the Developer free edition from the dropdown list.
Look through the license terms and tick the checkbox to accept them. Press Next afterward.
At the Feature Selection step, specify the path for SQL Server installation and select all features you need. Press Next to proceed.
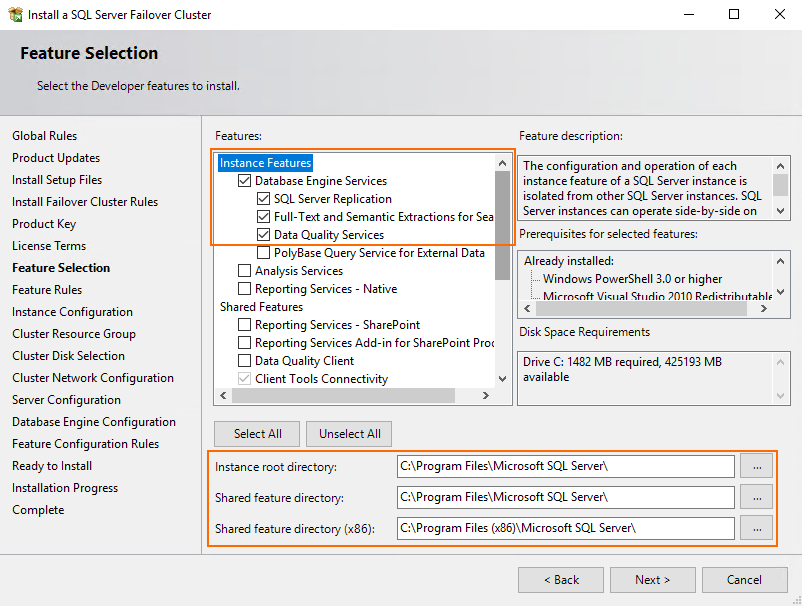
Enter SQL Server Network Name, Name instance, and Instance ID in the self-titled fields.
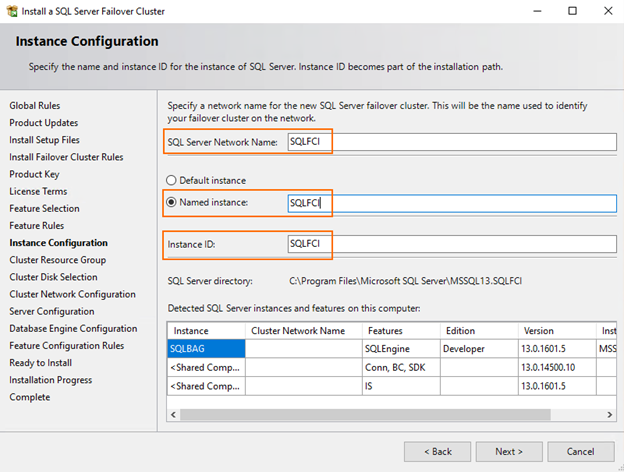
At the next step, select the automatically created cluster resource group and click Next.
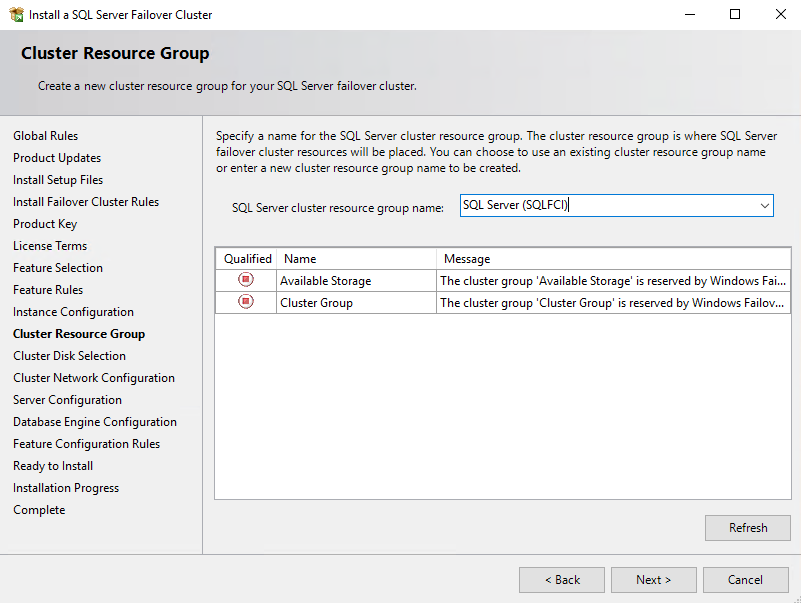
Specify the shared disk that you want to include in the SQL Server resource cluster group for keeping databases.
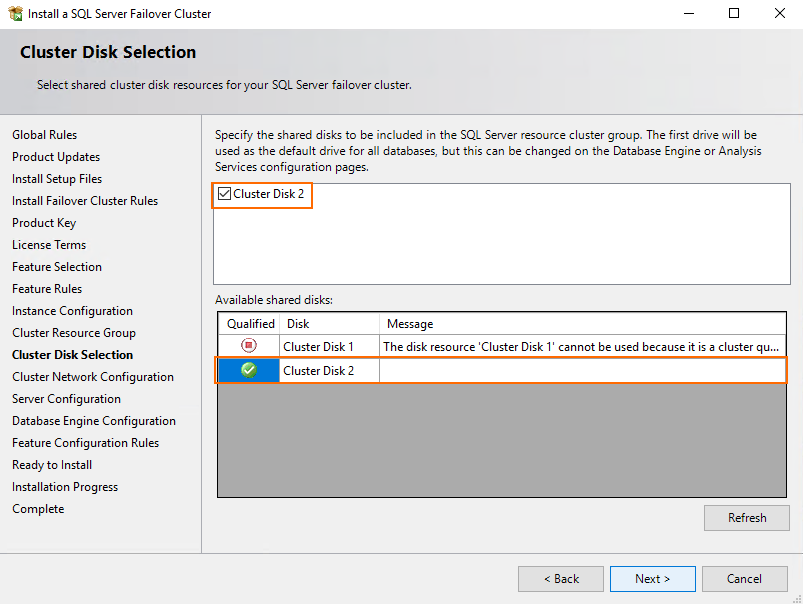
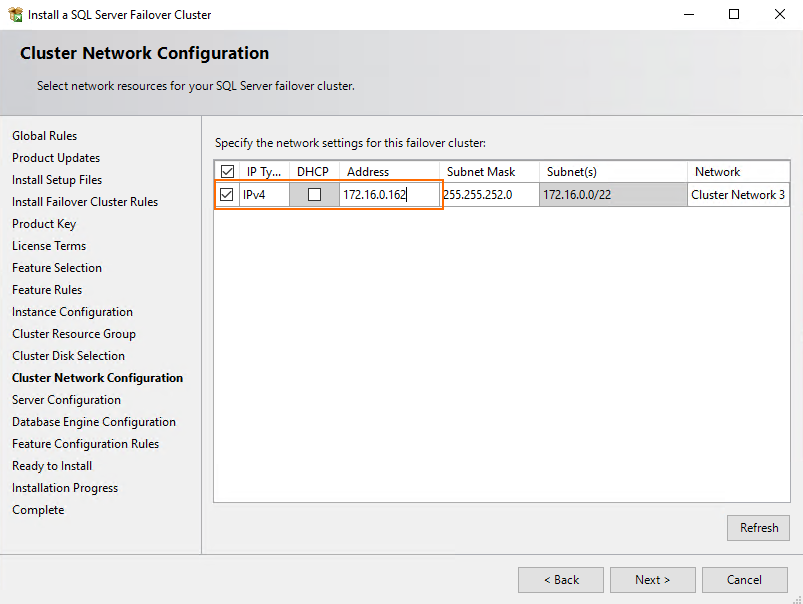
Specify the network settings for this failover cluster. You can use DHCP or just enter SQL Server failover cluster IP.
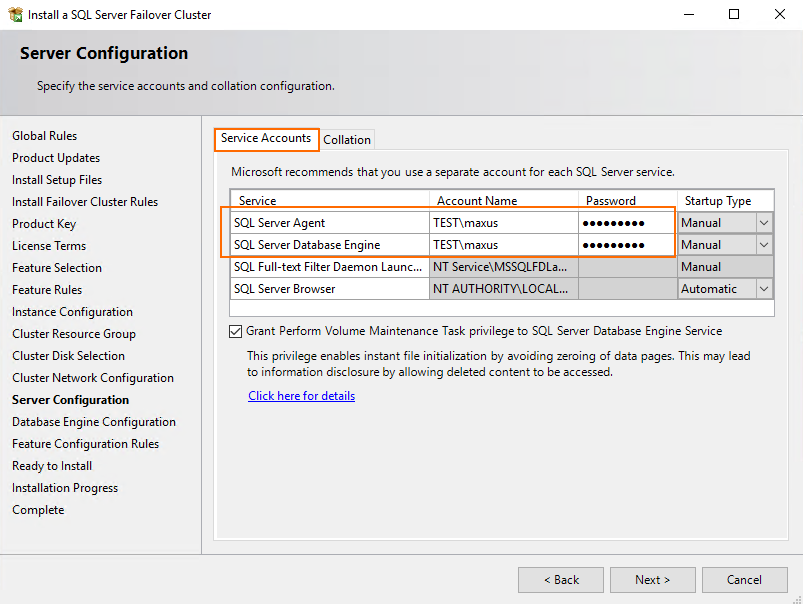
Enter SQL Server Database Engine and SQL Server Agent account details. Here, I use the domain ones.
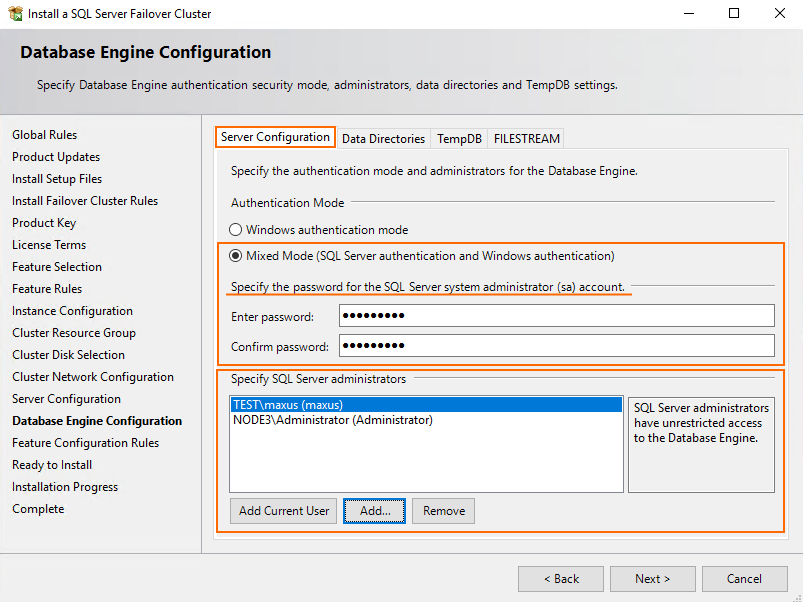
Next, decide on the authentication security mode and specify the password for the SQL Server system administrator account.
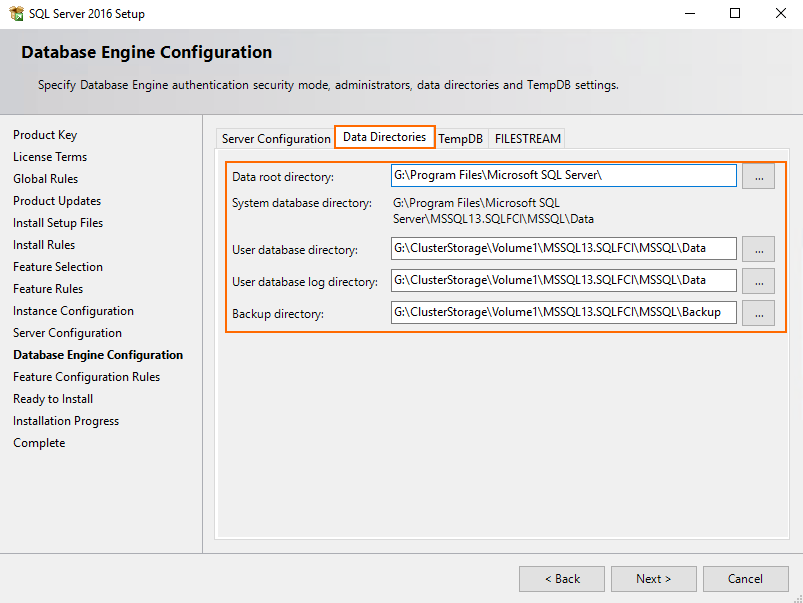
Specify the path for the database. Here I use cluster disk G.
Afterward, go to the TempDB tab and specify TempDB data files and TempDB log files parameters.
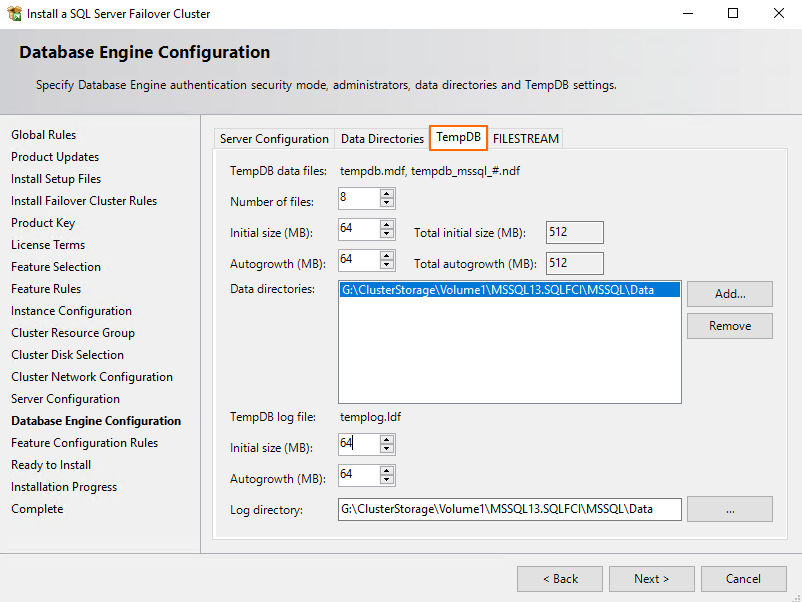
Check the settings and press Install.
Once SQL Server FCI installation is complete, press Close.
Now, let’s install SQL Server FCI on Node 4.
One more time, install the SQL Server preinstalled image as administrator. This time, you need to opt for Add node to a SQL Server failover cluster.
On the whole, there’s nothing new about the installation procedure. Of course, there are several differences, and, to make the long story short, I’d like to discuss only them in the following steps.
At the Cluster Node Configuration step, select the SQL Server instance to which you are going to connect Node 4.
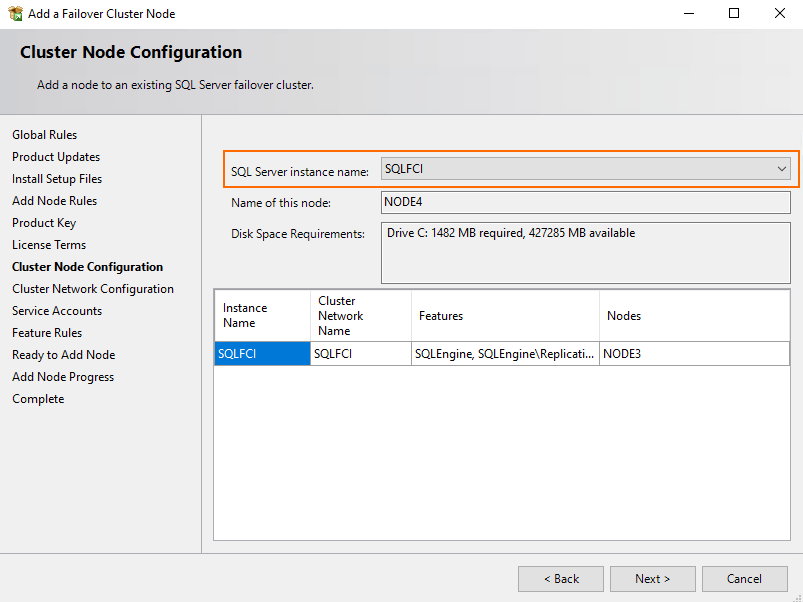
During cluster network configuration you need to select the already existing configuration. Just tick the checkbox and press Next.
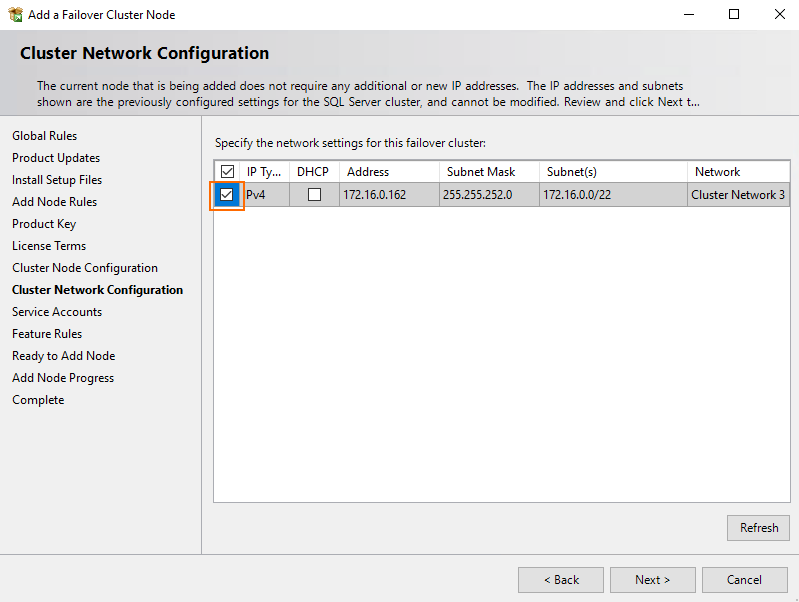
Well, that’s it! The whole procedure, apart from those two steps that I’ve just mentioned above, is identical to what you did for Node 3. So, press Close once SQL Server is installed.
Now, let’s run SQL server and check whether Failover Cluster role is there.

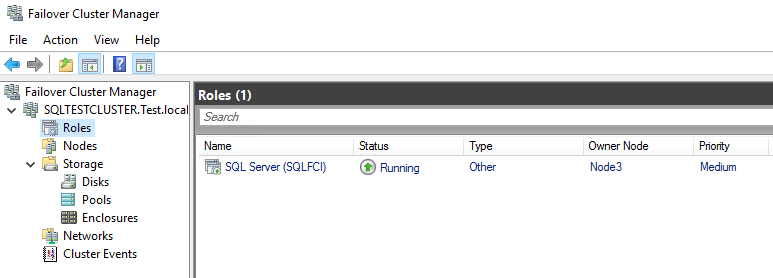
Everything is fine, let’s create a database now.
Creating a database
Install Microsoft SQL Server Management Studio on Node 3 and connect to SQL Server FCI.
Create an empty database (TestBase) next.
Flooding database
Fill the database with data using HammerDB. Once this process is over, you’ll get the output with database writing performance.
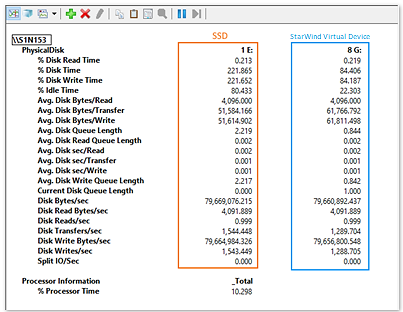
Obviously, I do not want the cache to alter SQL Server FCI performance test. That’s why I reduced the overall amount of RAM available for each SQL server to 512MB.
Challenging SQL Server FCI performance
Everything is installed and fine-tuned, so I finally can run some performance tests.
First, let’s see how fast reading can be done. In Microsoft SQL Server Management Studio request reading 1M rows from the dbo.customer table. It took SQL Server FCI 19 sec to cope with this task. Well, the same number as for SQL Server BAG!
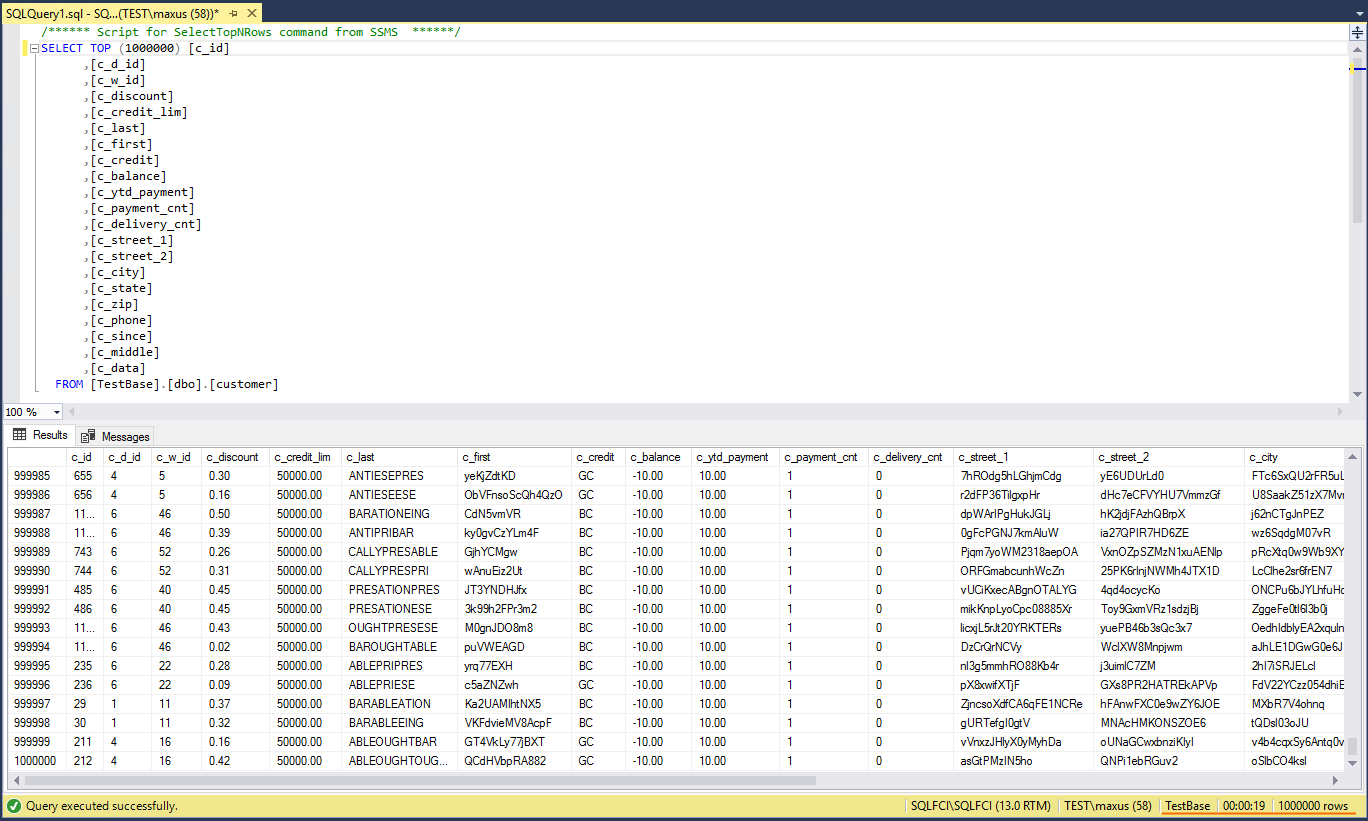
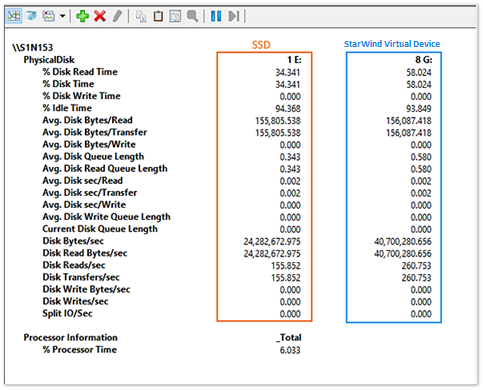
Let’s take a look at reading performance of the disk that keeps the database.
Let’s do some more tests! Let’s see how database reading bandwidth and request execution time depend on the number of threads (Number of Threads = 1,2,4,8,10,12). Just like for SQL Server BAG, I used SQLQueryStress for these measurements.
| SQL FCI | ||||
|---|---|---|---|---|
| test run time,
sec |
HA IMG,
MB/s |
SSD (Node 3),
MB/s |
SSD (Node 4),
MB/s |
|
| threads=1 | 2,56 | 346 | 191 | 189 |
| threads=2 | 2,55 | 376 | 193 | 192 |
| threads=4 | 4,10 | 375 | 259 | 246 |
| threads=8 | 9,42 | 348 | 324 | 323 |
| threads=10 | 12,25 | 501 | 347 | 349 |
| threads=12 | 17,69 | 499 | 397 | 398 |
Let’s do one more test using HammerDB (OLTP pattern). Now, let’s see how varying the number of threads impacts the reading speed.
| SQL FCI test run time, min | |
|---|---|
| Virtual User=1 | 9 |
| Virtual User=2 | 8 |
| Virtual User=4 | 9 |
| Virtual User=8 | 8 |
| Virtual User=10 | 10 |
| Virtual User=12 | 12 |
Charts below highlight on how performance changes under a varying number of threads.
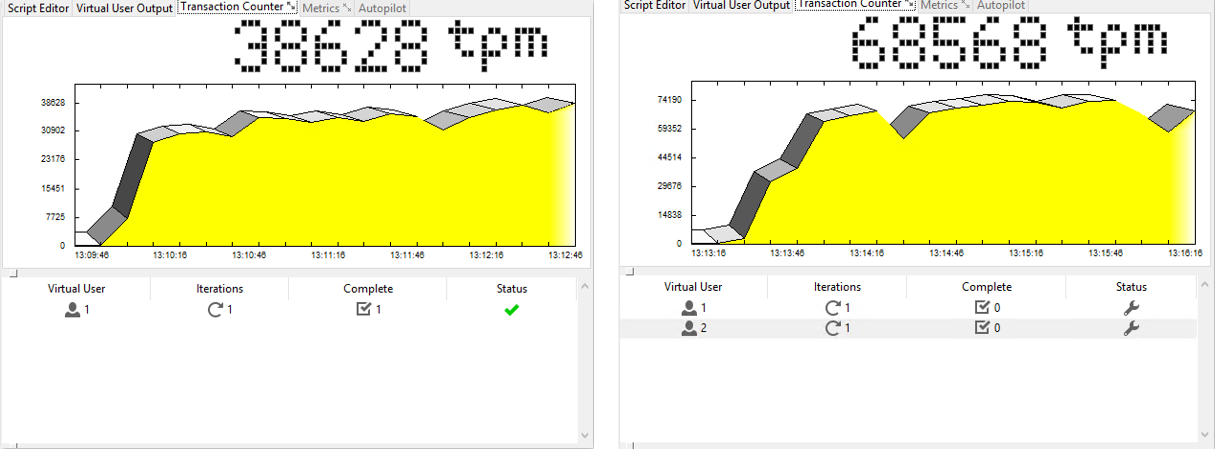
Figure 1: Virtual Users = 1 and Virtual Users = 2
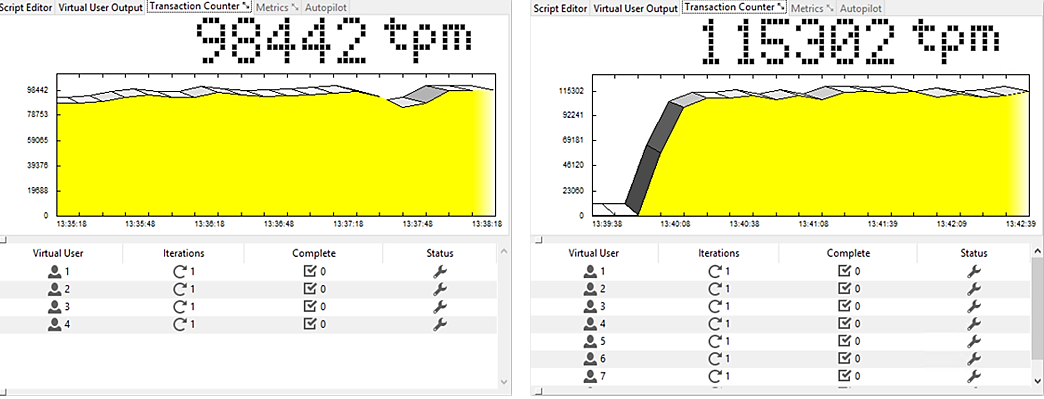
Figure 2: Virtual Users = 4 and Virtual Users = 8
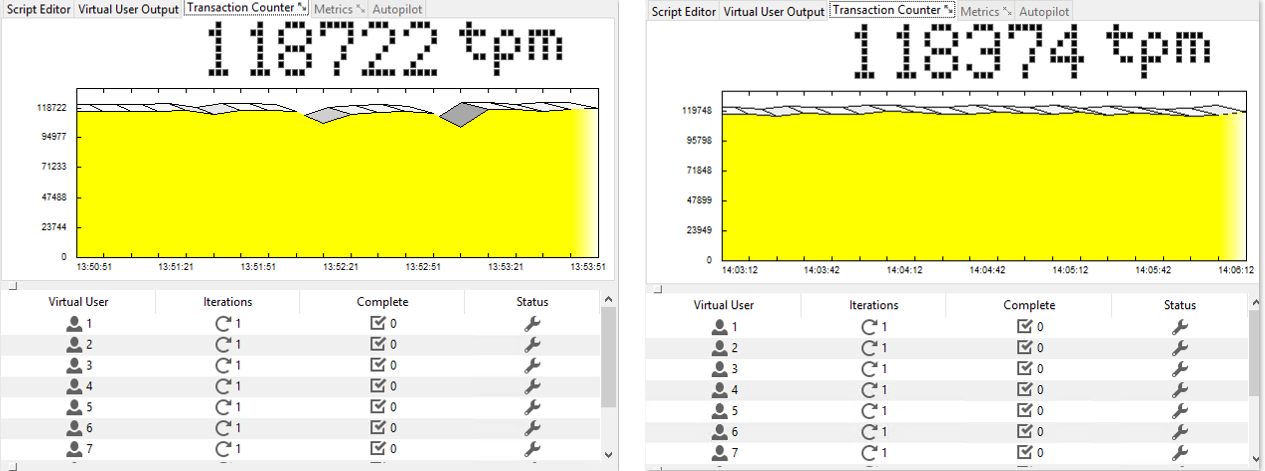
Figure 3: Virtual Users = 10 and Virtual Users = 12
CONCLUSION
In this article, I studied SQL Server Failover Cluster Instance performance. Time to read 1M rows is the same as for BAG. That’s weird. I will think through it, but it seems to me that there may be something wrong with StarWind virtual device performance. I am not 100% sure as I need to carry out extra measurements to find out what’s going on. In my next article, https://www.starwindsoftware.com/blog/hyper-v/can-sql-server-failover-cluster-instance-run-twice-fast-sql-server-basic-availability-groups-2-node-cluster-part-3-comparison-time/, I compared FCI and BAG performance and did some tests to find out what could go wrong with StarWind HA device.
