

This blog is in four parts. It is receiving such a lengthy treatment because it is something that is truly mission critical: the effective management of data. Confronted with a tsunami of new data, between 10 and 60 zettabytes by 2020, data management is nothing less than a survival strategy for organizations going forward. Yet, few IT pros know what data management is or how to implement it in a sustainable way. Hopefully, the next few blogs will help planners to reach a new level of understanding and begin preparing for a cognitive data management practice.
Most presentations one hears at industry trade shows and conferences have to do, fundamentally, with Capacity Allocation Efficiency (CAE). CAE seeks to answer a straightforward question: Given a storage capacity of x petabytes or y exabytes, how will we divvy up space to workload data in a way that reduces the likelihood of a catastrophic “disk full” error?
Essentially, from a CAE perspective, efficiency involves balancing the volume of bits across physical storage repositories in a way that does not leave one container nearly full while another has mostly unused space. The reason is simple. As the volume of data grows and the capacity of media (whether disk or flash) increases, a lot of data – with many users — can find its way into a single repository. In so doing, access to the data can be impaired (a lot of access requests across a few bus connections can introduce latency). This, in turn, shows up in slower application performance, whether the workload is a database or a virtual machine.
Allocation efficiency is also important as a gating factor on infrastructure cost. Storage is not free, and filling available capacity in a carefree unmanaged way is a cost accelerator that few organizations can afford. Today, depending on the analyst you read, storage accounts for between 33 and 70% of every dollar, euro, the drachma, shekel, krona, or pound that organizations are spending on IT hardware. Bending the cost curve in storage requires that pains be taken to eke out the most efficient use of the capacity you have.
The problem is that most organizations do a pretty poor job of allocating storage efficiently. Users ask for more capacity than they need and forget the capacity they aren’t using. Subsequently, unused capacity becomes “dark storage” that the administrator believes he or she has allocated, but that the user has not formatted or added into his or her resource inventory.
Dark storage joins storage occupied by needless copies of data, by orphan data (whose owners or servers no longer exist in the organization), by contraband data (that shouldn’t be stored on company infrastructure at all), and by archival data that belongs in a tape or cloud based archival repository, 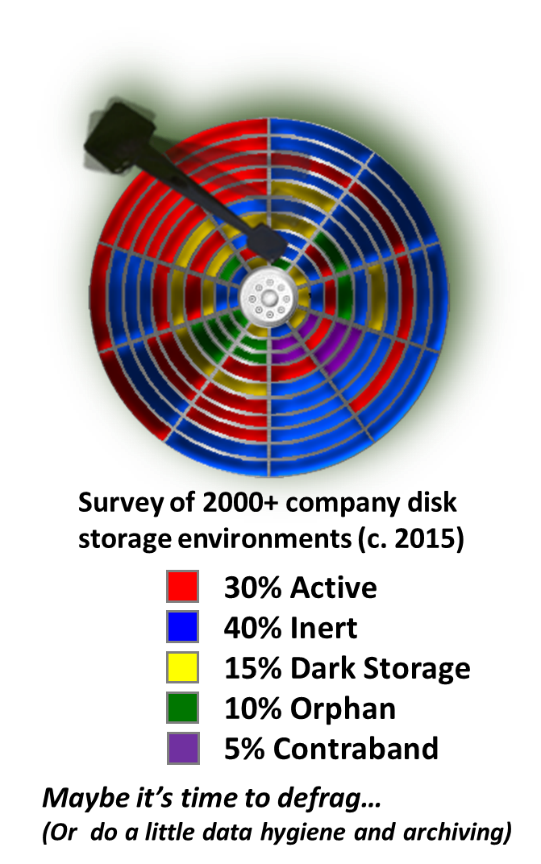 and not on production media. Based on studies conducted by the Data Management Institute, just sorting out the storage “junk drawer” and archiving data that is rarely accessed but nonetheless requires protracted retention would free up nearly 70% of the capacity we already own. That would forestall the need to buy more capacity. Management might just like that.
and not on production media. Based on studies conducted by the Data Management Institute, just sorting out the storage “junk drawer” and archiving data that is rarely accessed but nonetheless requires protracted retention would free up nearly 70% of the capacity we already own. That would forestall the need to buy more capacity. Management might just like that.
But instead of sorting out the junk drawer, which considered by most folks a burdensome and time-consuming task, the storage industry simply recommends buying more junk drawers. This is one way that waste begets more waste and it is the way that most firms have been growing inefficient storage infrastructure for the past several decades.
At the beginning of the new Millennium, the industry began introducing some newer algorithms for space saving: so-called data reduction technologies like de-duplication and compression. Some vendors embedded this functionality on array controllers so they could charge hundreds of thousands of dollars/euros/drachma/etc. for kit whose components were reasonably valued at only a fraction of that price. The claim used to justify this markup was simple: with the value add reduction technology in place, every piece of storage media would behave like 60 or 70 copies of that media. Like the Genie in Disney’s Aladdin, vendors offered “Phenomenal cosmic power. Itty bitty living space.”
Even if these claims proved out (they didn’t), compressing the data in the junk drawer was merely a holding action, a tactical measure. Eventually, even compressed and de-duplicated data would fill the junk drawers of the storage infrastructure. CAE, in other words, was represented as a strategic goal unto itself, but it was, in fact, a tactical measure that should have been used to buy time so that a more sustainable strategy for out-of-control capacity demand could be found.
Real storage strategy focuses on Capacity Utilization Efficiency (CUE). CUE is less about achieving a simple balance in capacity allocation than it is about the deliberate and purposeful placement of data on the storage that best meets its needs. “Needs” may include access speeds (how fast an end user or application can find and retrieve the data when needed) and update requirements (how often stored data is updated by users and apps), but these metrics alone are not sufficient. Today’s data hosting requirements have gone well beyond the speeds and feed issues to include the allocation of storage services. Planners also need to define storage needs in terms of business context: How will the data be protected, preserved and kept private in a manner befitting its importance, criticality, and regulatory or legal mandates?
Capacity Utilization Efficiency is achieved through data management strategy. Data management seeks to manage the hosting of data throughout its useful life based on policies that reflect the hosting requirements for the data, including accessibility, update frequency, the cost to store, business requirements for protection, preservation, and privacy. Doing data management correctly requires a real-time assessment of
- The state of the data itself, which is maintained as metadata in a global namespace or index,
- The status and availability of storage resources (media, controllers, links) that have been inventoried and characterized,
- The status and availability of storage services whether instantiated as software on array controllers (traditional), or as part of a software-defined storage stack on a server (regarded as the new approach) or delivered as a third party application.
In the past, correlating these inputs and interpreting their meaning in the context of a policy for managing a class of data required a human administrator. With the volume of files and objects quickly approaching the zettabyte range in larger firms and clouds, such a manual approach is impossible to sustain. Needed will be a cognitive computing or artificial intelligence component to relate this particular “internet of things” to the pre-defined policy. That is Cognitive Data Management architecture in a nutshell, and that is the focus of the rest of the columns in this series.
NEXT UP: The CDM Policy Framework.
Related materials:
