

Introduction
Personally I have been very successful at providing good backup designs for Hyper-V in both small to larger environments using budgets that range in between “make due” to “well-funded”. How does one achieve this? Two factors. The first factor is knowing the strengths and limitations of the various Hyper-V versions when you design the backup solution. Bar the ever better scalability, performance and capabilities with each new version of Hyper-V, the improvements in back up from 2012 to 2012 R2 for example were a prime motivator to upgrade. The second factor of success is due to the fact that I demand a mandate and control over the infrastructure stack to do so. In many case you are not that lucky and can’t change much in already existing environments. Sometimes not even in new environments when the gear, solutions have already been chosen, purchased and the design is deployed before you get involved.
That’s too bad. It pays to keep a holistic view of the all the needs that a Hyper-V environment has to serve. That includes Hyper-V’s own needs as well and these should not be forgotten. But even with great gear, good designs and excellent deployments there are architectural weaknesses that need to be fixed.
Let’s look at the Hyper-V backup challenges Windows Server 2016 needs to address. There are two major structural issues with Hyper-V backups.
The first is the dependence on host VSS snapshots. This has improved from Windows Server 2012 to Windows Server 2012 R2. Read Ben Armstrong’s blog post on this How Hyper-V Backup Got Better in 2012 R2 (but now requires a SCSI controller). But it’s not good enough yet. These don’t scale well, as the host VSS and the guest VSS actions are tied together at the hip. This causes performance issues along with storage fabric IO overhead. The main reasons for this are the amount of work a Hyper-V snapshot has to do and the time it takes.
The second is the fact that there is a need for more inbox intelligence when it comes to optimizing backup sizes. This issue has been addressed by some great backup vendors like VEEAM with their Backup & Replication software. Their proprietary Change Block Tracking (CBT) mechanism has shown the path for many follow.
The VSS issues however cannot be addressed without Microsoft making changes. It’s been the Achilles heel of Hyper-V for way too long. To anyone involved in large scale Hyper-V deployments it’s been clear for while that this needed to be improved drastically. Just like they improved the capability, scalability & performance of Hyper-V with Windows 2012 (R2) Hyper-V. This made Microsoft a power player in hypervisor market. To make sure that we can protect the workloads this allows us to run on Hyper-V they need do deliver the same improvements in regards to backups. Microsoft has a horse in this race as well as Hyper-V is corner stone of Azure and they need to sever their own needs as much as ours.
With Windows Server 2016 Hyper-V backup Microsoft rises to the challenge. They did so by leveraging and enhancing the native capabilities of Hyper-V. The inbox capabilities allow for agentless backups, remove the dependency on host level VSS infrastructure and by introducing CBT in the product. The manner in which they do so is interesting in the fact that they aim to provide CBT that supports VM mobility and even power loss scenarios or BSOD events. Next to that it aims to deliver the benefits to all sort of deployments whether you have a SAN or not and with or without a hardware VSS provider. All this while still allowing the storage and backup vendors to leverage the benefits using their solutions can give you.
We’ll now take a closer look at why it was necessary for Microsoft to improve its backup story and how they have done so. In future articles we’ll dive in the technology a bit deeper.
Hyper-V backup challenges Windows Server 2016 needs to address
When you have a home lab or even a lab at work that isn’t too big and has decent resources you might wonder what issues we’re talking about. One of the labs I have access to, runs a couple of dozen VMs on SSD (Storage Spaces). I seldom have issues if any at all with the backups as they are not in constant use and the IO resources storage (both source and target) as well as network wise are plentiful.
Now bring in scale, large LUNs, large VMs, heavy IO, large change delta’s, CSVs, SANs, the VSS limitations and perhaps less than optimal backup software for virtualization workloads. Things change fast for the worse in larger more demanding virtualization environments.
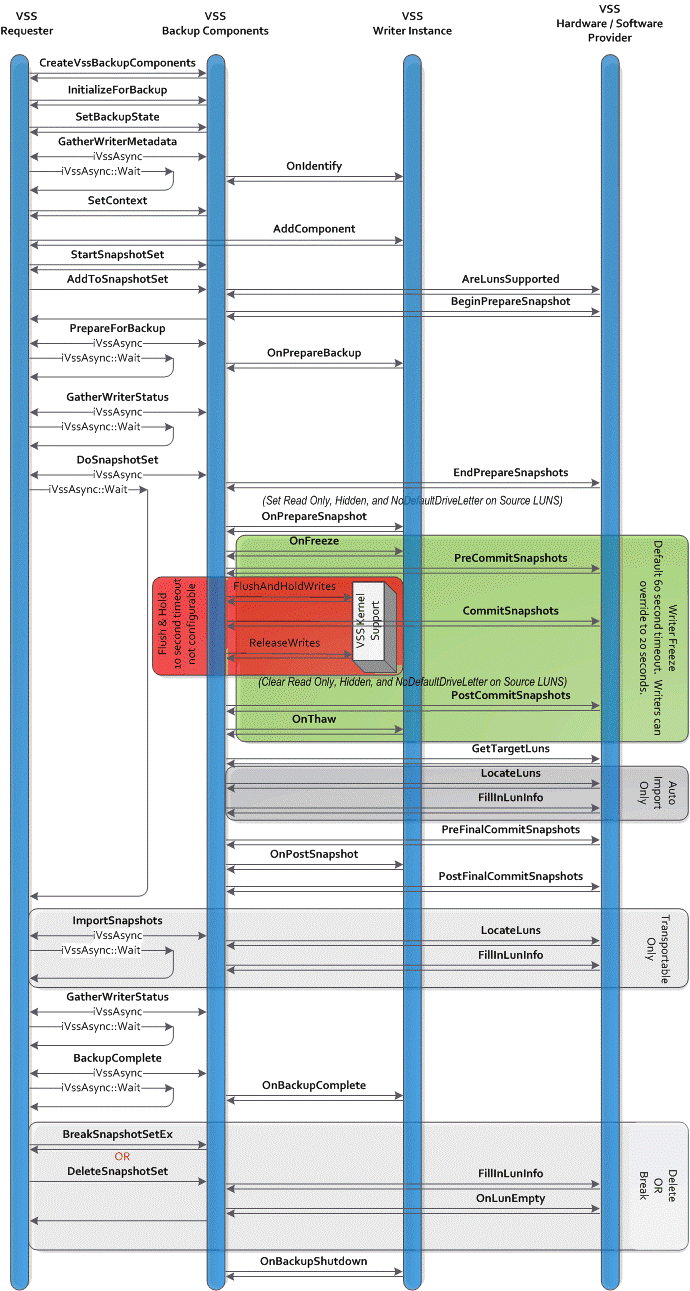
Take a look at this MSDN article to see that the Volume Shadow copy Service is complex game between the VSS requester, the VSS Writers and the VSS provider (software or hardware). One of the critical phases to keep to a minimum is the period between free and thaw were all writes are “frozen”.
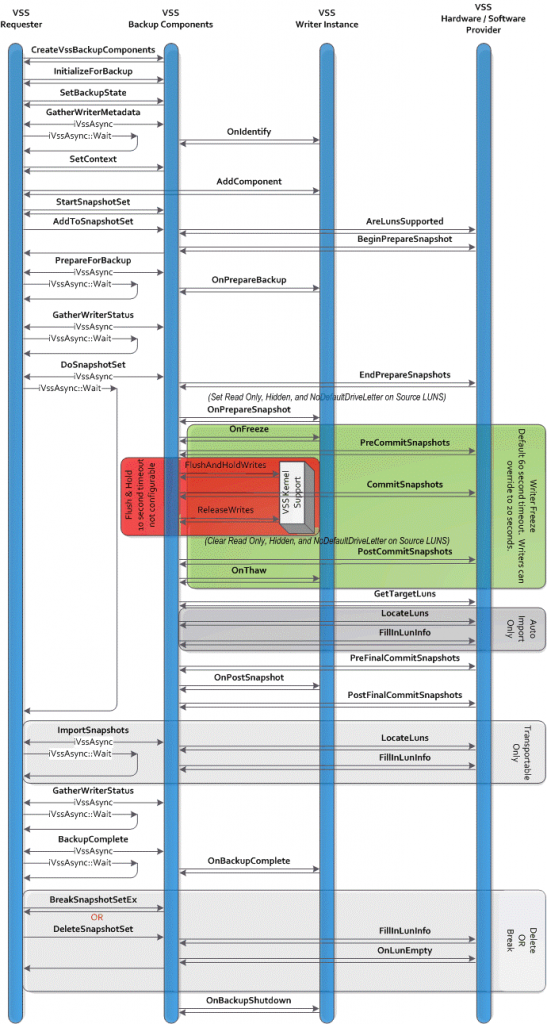
Image courtesy of Microsoft
This works out pretty well and reliable for physical or virtual servers with one or more workloads. But when we do host level backup of a Hyper-V host with lots of virtual machines a truckload of extra work comes into play. It’s a juggling act between VSS on the host and in the guests. Let’s look at the backup process in Window Server 2008, 2008 R2, 2012 and 2012 R2 briefly to see how things have improved and understand why it still needs more work.
The backup process in Window Server 2008, 2008 R2, 2012 and 2012 R2 Hyper-V
Hyper-V in Windows Server 2008, 2008 R2 and 2012 has the ability to backup running virtual machines from the host operating system. So you don’t need to mess around with deploying backup agents to all guests and pretend or act as if they are physical servers. All this is without down time and is based on clever but complex interaction with the Volume Shadow Copy Services in both the guests and the hosts. The process is as follows:
- The backup application requests that Hyper-V backup all virtual machines
- Hyper-V goes through each virtual machine and sends a request to the Hyper-V Backup integration service inside of the virtual machine
- The Hyper-V Backup integration service inside of the virtual machine then asks the guest instance of VSS to create a data-consistent VSS snapshot inside of the virtual machine
- Once all the virtual machines have confirmed that they have taken a VSS snapshot, Hyper-V tells the host instance of VSS that it can take a host VSS snapshot
- Now, at this stage – some time has elapsed between steps 3 and 4. This means that the virtual machines were continuing to write data to their virtual hard disks, and that the virtual hard disks host VSS snapshot are not actually data consistent. To handle this, Hyper-V then:
- Locates the copies of the virtual hard disks that are stored in the newly created host side VSS snapshot.
- Mounts each of these virtual hard disks in the host environment.
- Uses VSS to revert each virtual hard disks state to the VSS snapshot that was taken in step 3.
- Dismounts each virtual hard disk from the host.
- Informs VSS that it is complete – and that it can return the files in the host VSS snapshot to the backup application.
- When the backup application is done, the VSS snapshots can be cleaned up when needed. If it a backup solution integrated with the SAN snapshots (which in this case are application consistent via a VSS Hardware Provider) they’ll stay around until the backups expire.
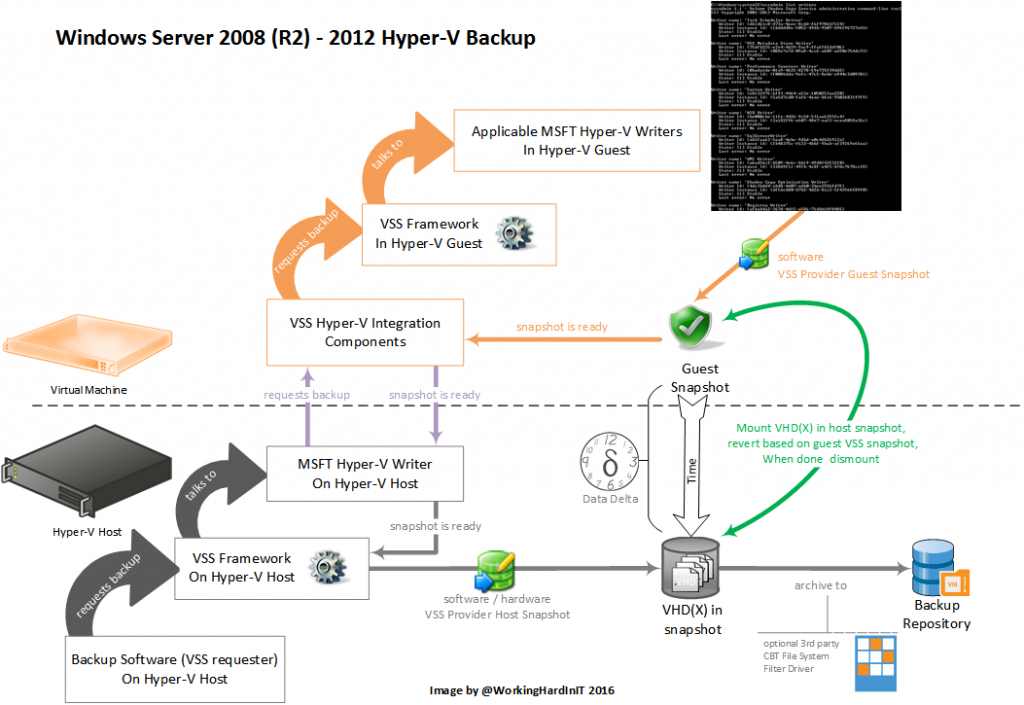
This has a significant overhead associated with it. The copy of every virtual hard disk in the host VSS snapshot is mounted on the host. Then this copy is reverted to the consistent state based on the VSS info captured in the Guest VSS snapshot which is exposed to the host. All this to create a consistent host level backup. After this the disk is dismounted. This causes a lot of overhead and takes time. Try and do this for 300 VMs every hour. Now imagine if we have some bugs come into play and the overhead associated with the CSV owner coordination of IO to a CSV during backups.
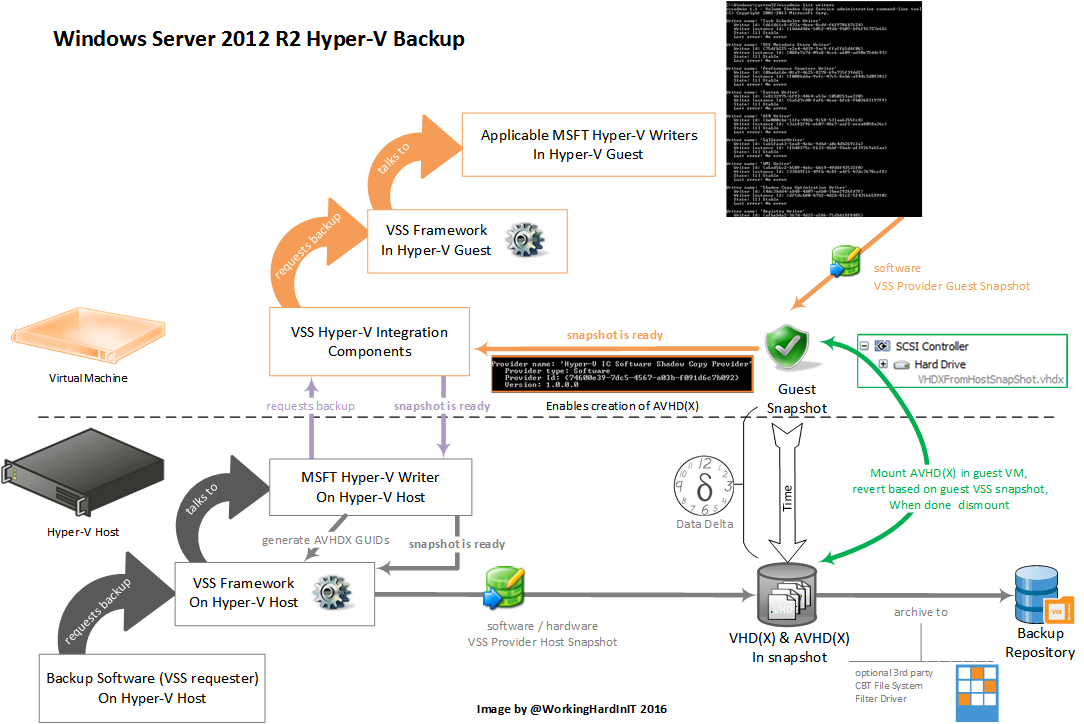
In Windows Server 2012 R2 this process was improved. They added, via the integration components, a “Hyper-V IC Software Shadow Copy Provider” in the guests.
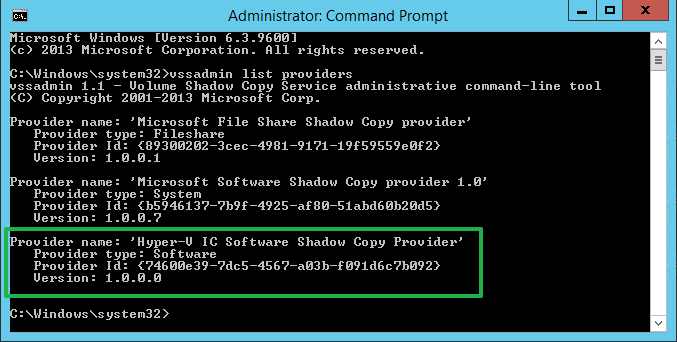
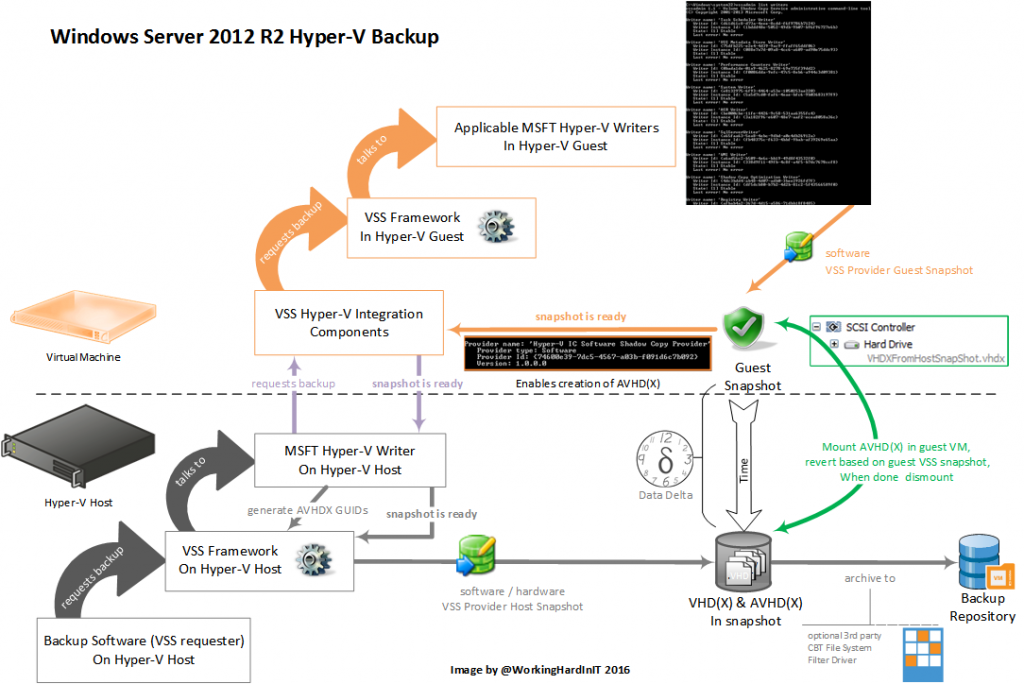
This basically allows the VM to create a snapshot as if it has hardware VSS capabilities. This translates into the creation of an AVHD(X) for every VHD(x). This has some overhead associated with writing to a differential disk. But it allows for a new approach at point 5 in the backup process. The point in time VHDX gets mounted in the VM It’s that data on the disks that’s reverted to the consistent states based on the guest VSS snapshot.
- Locates the copies of the virtual hard disks that are stored in the newly created host side VSS snapshot.
- Connects each virtual hard disk copy to the still running virtual machine that it was copied from. That’s why a VM requires a vSCSI controller with 2012 R2 to do backups.
- Sends a message to the Hyper-V Backup integration service inside the virtual machine that instructs it to revert the virtual hard disk copy to the VSS snapshot that was taken in step 3
- Disconnects each virtual hard disk.
- Informs VSS that it is complete – and that it can return the files in the host VSS snapshot to the backup application.
This avoids the mounting, reverting & dismounting of each and every vhd(x) to the host system. The result is a more scalable and reliable backup process. This also opens up the capability doe backup shielded VMs in Windows Server 2016 Hyper-V by the way.
For more information on this see my blog post Some Insights Into How Windows 2012 R2 Hyper-V Backups Work
Also not that handling everything inside of the VM actually enabled the ability of backing up Shielded VMs in Windows 2016 Hyper-V.
Progress has been made but scalability, reliability and performance still remain big challenges which are tightly interconnected. Problems present themselves in both technical and operational issues which we’ll discuss below in relation to their causes and explain why they need to be addressed.
Issues with the dependency on Host VSS Framework
Next to the VSS integration to get application consistent backups of the guests a Hyper-V backup also relies on a host level VSS snapshot of the LUN that’s used as a source for the backup. Today having more than 20/30 VMs or more per host is not a big deal and that number keeps growing. Creating VSS snapshots on CSV with many VMs still has performance and reliability issues.
It’s paramount a VSS snapshot is taking a fast a possible to keep impact on the storage IO as low as possible. Large volumes with a large number of VMs and a lot of churn can spend a long time and can cause IO overhead. So putting all 100 VMs on your 3 node cluster on a single CSV is not a great idea.
It also causes a lot of overhead to back up a single VM. This is the elephant in the room. A VSS snapshot is based on LUNs. That means that when you take a backup of a single VM it creates a snapshot of the LUN (next to the VSS integration with the guest for application consistent backups). I this is a large LUN with let’s say 15, 25 or even 50 virtual machines the host VSS snapshot impacts the entire LUN and as such every VM on that LUN.
The better way of handling this is having more CSV / LUNs. This keep the number of VMs and/or the size of the LUNs in check. This ultimately reduces the impact of making backups. To the extreme this brings you back to one VM per LUN and we do not want to go there!
Clever software will leverage a single VSS host snapshot to create backup of multiple VMs residing on that LUN but this also has it limits due to performance issues. Sounds easy right? But you can only do this when all the VMs on that single LUN are owned by the same host, otherwise multiple snapshots are needed. Some backup software or SAN based backup solutions even require the VMs to reside on the same host as when the backup job was created or the job fails. All in all, this limits virtual machine mobility in a sense that you have to manage the location of the VMs at backup time and design the LUNs and layout of the VMs in function of backup needs rather than perhaps dynamic optimization, mobility and flexibility. Even when it all works perfectly it adds management overhead and limits you as the needs are often at odds with each other. Especially with CSV we’ve seen a fair number of fixes & updates over the years dealing with CSV ownership & coordination of VSS activity during backups.
Keep thinking about the overhead. There a LUN snapshot for every VM your backup. Ouch. If the VM has multiple virtual hard disks these can be, potentially, on different LUNs. So that means even more snapshots are taken for a single VM. As we stated, good backup software allows for backups of multiple VMs from the same snapshot but that means managing the VM according to backup need & frequency on separate LUNs. That’s management overhead on top of performance and storage use issues.
When you want to do many backups in parallel this means many snapshots, sometime of the same LUNs and that doesn’t always work out well at all to put it mildly.
All these snapshots also have to be mounted somewhere for the data to be copied off, dismounted, cleaned up etc. Day in, day out, many times a day even depending on the needs and requirements.
All the above amounts to a lot of overhead and inefficiencies. Now think about what all the above means when the business requires hourly backups?
For larger VMs, for example SQL Server virtual machines who have an OS, data, log and TempDB vhdx on different partitions, the number of VSS snapshots increased fast per VM being backed up. There’s the challenge of make sure all these VSS snapshots are done simultaneously and are consistent. Now many people said to put all these on the same LUN as virtualization doesn’t require the same approach as hardware based SQL server deployments. But IO contention is IO contention and while VHDX is a very performant format if we need SSD for the data and/or even NVMe for the logs and TempDB for physical deployments, this won’t be much different for a virtual deployment. Naturally you can go all flash or even NVMe fabric solutions in the future, but still, one size can achieve a lot but will not always fit all. The same issue occurs with multi-tiered applications. It leads to the need to create VSS snapshots of multiple LUNs in parallel. Not all LUNs will be owned by the same hosts by default let alone all by a single host owning all of the VMs. In the case of a load balanced web farm or guest clustering you don’t even want that. That’s where you’ll use anti affinity.
Finally, hardware VSS providers are not found in Storage Spaces or Storage Spaces Direct. The ever more variable type of storage solutions used requires a new approach that works for more storage deployments no matter their nature.
Windows VSS Provider
The best thing about the native Windows VSS provider is that it’s inbox and as such is low in maintenance overhead. Updates & bug fixes should come with regular Windows updates or a hotfix. Operationally however, the Windows VSS provider has a long history of issues. Some due to bugs, especially with Clustered Shared Volumes, other due scalability issues. This was even more prevalent under heavy loads. Many of the bug have been ironed out by now by Microsoft, often in combination by bug fixes by backup vendors. The scalability issues and the performance impact remain.
VSS hardware provider
Some of the performance or scalability issues can be mitigated to a certain extend by installing a storage vendor provided hardware VSS provider. Some of these however are lacking in quality themselves. The ones that don’t often still have limitations.
Sometimes this is due to the fact that use one provider to serve all Hyper-V editions which means they fall back to the lowest common denominator in Hyper-V capabilities not allowing to leverage the improvements made over the years. These limitations are often visible the best in the data protection software solutions available from the SAN vendor. Still they have a role to play and I use them when I have tested them for quality and usability. Apart from the helping deal with heavy loads they also allow form transportable snapshot to be leveraged by off host backup proxies.
Do note that they require installing agents and/or services on all the Hyper-V and backup hosts involved and of host proxies require access to the common storage fabric. This, again, like with backup agents introduces the overhead of installing, managing (service accounts/passwords, network configuration) updating them updates etc. So the maintenance is rather high, especially at scale. Automation and tooling help, but there is an effort involved.
Bar performance issues and storage inefficiencies the other problem was that many SANs don’t cope well with multiple concurrent VSS hardware snapshots. It adds to the reliability problem as it becomes necessary to schedule your backups not to run concurrently when the VMs reside on the same LUN or perhaps even on the same host or cluster. How far you need to take this depends on the SAN and the hardware VSS provider.
Backup Vendors & SAN collaboration
When a storage vendor and a backup software vendor collaborate some great results can be achieved. Done right backup and restores can be done fast by integrating the storage VSS hardware provider their application aware snapshot into the backup software for frequent shot term backups and restores. In this use case the SAN snapshots are not discarded but keep around for the retention time of the backup. This shouldn’t be your only backup/restore capability because storage arrays can go down, suffer from firmware bugs, data corruption etc. So this is an augmentation technology, a force multiplier but it’s not a complete solution on its own for many reasons.
Backup agents
Deploying, managing & updating backup agents at scale can become burdensome and add to the operational overhead. Automation & tooling helps, but isn’t perfect in many cases.
Shared VHDX
While shared VHDX was very welcome to make guest clustering enjoy many of the benefits that come with virtual disks it still has some shortcomings in Windows Server 2012 R2. Bar the lack of storage live migration and on line resizing of the shared VHDX we have a major issue with the fact that you cannot do a host level backup of the VM. There’s only in guest backup, which isn’t a great story for virtual machines and potentially causes a lot of redirected CSV IO.
The growing volumes of data in backups
The amount of data inside of VMs as well of the number of VMs is growing. Traditional backup software is hopelessly ill equipped to handle this. These were not designed with this type of workload in mind and they had to adapt and find creative ways of handling this. Some were more successful at this than others.
If they do not, they consume backup storage like there is an infinite amount at zero cost available. We all know that’s not true. But even worse, that large amount of data can only be dealt with via performant storage a lots of bandwidth to copy it over. Turning to deduplication can help but if it’s an appliance is not free, some backup vendors also charge for this option. With free post process deduplication when Windows Server is used as a backup target you very large deltas put you under risk that the dedupe won’t complete between backup windows and will ultimately trail behind so much it won’t do you much good.
Now Windows Server data deduplication can deliver excellent results when implemented well. Outstanding deduplication rates however mean that the intelligence of the backup solution isn’t excellent as you keep dumping duplicate data on the target that has, of cause, a great potential for deduplication. For smaller needs this isn’t an issue and raw performance can handle this and deliver great value. It’s when but it doesn’t scale that well or allow for hourly backups as it just can’t dedupe the incoming data fast enough. On top of this the need for guest VM encryption is causing deduplication to lose it edge. Storage deduplication and compression also have their issues and bugs to deal with.
The backup vendors that really stand out are those designed for backing up virtual machines. Veeam is the poster child when it comes to this and well deserved so. Why? Well, lots of things make a great solution but for this purpose we’ll stick to a single item: Change Block Tracking (CBT). It’s weird to see that some took so long to implement it and get back into the game while others still don’t have it in 2016!
CBT optimizes backup by only needing to copy the changed data delta between backups. It is very efficient at mitigating the effects of the otherwise serious amount of data volumes that have to be moved around and reduce the storage needs on the backup targets. This is often combined with compression and deduplication to reduce the amount of data being transported over the wire even more. On the backup targets people sometime opt for specialty hardware in the form of deduplication appliances or implemented post process deduplication solutions such as Windows Server 2012 R2 data deduplication to help deal with this. This has a certain cost associated to it, adds more or less to the complexity of the solution and also incurs overhead on the backup target as well as the restore process. But none of these are show stoppers or problematic as long as one knows what one is doing.
Smart designs that look at the needs can help reduce cost and complexity but sometimes you need extra tools and budget to make it work in a given environment.
Every backup vendor has to develop its own CBT code and as these are kernel mode it has to be of stellar quality or the results can be devastating (Blue Screens of Death – BSOD). So that’s a reliability concern that comes up. It needs to be tested/certified with every OS release etc. which is a lot of work and not all backup vendors can get this delivered in a timely fashion. When we move to be version of an operating system we don’t want a backup vendor to hold us back. The experience has been that many have taken too long to truely support a new Windows Server Hyper-V release.
Getting that code on the Hyper-V hosts and integrating with the guest VMs is also a challenge to avoid management overhead which some vendors like VEEAM truly shine at solving and others leave it as a chore to the administrators.
CBT has issues with VM Mobility and unplanned failover (power loss, BSOD) if that information is in memory and if it isn’t persisted somewhere. In this case it will need to be dealt with by a full back up or by check summing the existing backup to the current status to synthetically determine what has changed.
Management Overhead
I have already alluded to the fact that it’s smart to keep a holistic view on Hyper-V designs and consider the needs of Hyper-V itself, especially in regards to backups. This almost always leads to overhead associated with designing and managing around the structural limitations of Hyper-V backups right up to Windows Server 2012 R2.
While some backup solutions allow you to define to configure containers that allow any VM that appears in the container to be automatically backed up and which will also automatically be dropped from the backup when it disappears. The latter can mean removed, deleted or migrated. A container can be either an entire cluster, a complete host or a complete LUN / CSV. This is a wonderful concept to reduce management overhead an avoid having to micro manage backup jobs manually.
But mobility and containers mean that VMs can move around and end up on a different host than the one owning the LUN. In order to deal with all the limitations of the VSS framework and VSS providers we can’t do this without endangering the reliability or scalability. Remember that when you have to take simultaneous SAN snapshots of multiple LUNs or even all LUNs on a cluster most or even all (hardware) VSS providers fall apart. That’s the reliability issue. There’s also a serious impact on the storage performance. This is due to multiple parallel snapshot on a single LUN and over multiple LUNS. Also while the reading all of the data form those snapshots you cause a serious performance hit on the storage array (IO, latency). Some solutions are better at this than other, but many struggle. Raw performance (all flash, 10Gbps or better networking) helps a lot and is a good idea. But by itself it’s too blunt of an instrument to deal with all this as the environments grow ever larger.
In a future article we’ll take a look at how Windows Server 2016 Hyper-V Backup Rises to the challenges.

{kind=link}
{kind=link}
{kind=link}