

INTRODUCTION
Finally, I got the hands-on experience with StarWind NVMe-oF Initiator. I read that StarWind did a lot of work to bring NVMe-oF to Windows (it’s basically the first solution of its kind), so it’s quite interesting for me to see how their initiator works! In today’s post, I measure the performance of NVMe drive presented over Linux SPDK NVMe-oF Target while talking to it over StarWind NVMe-oF Initiator.

TOOLKIT USED
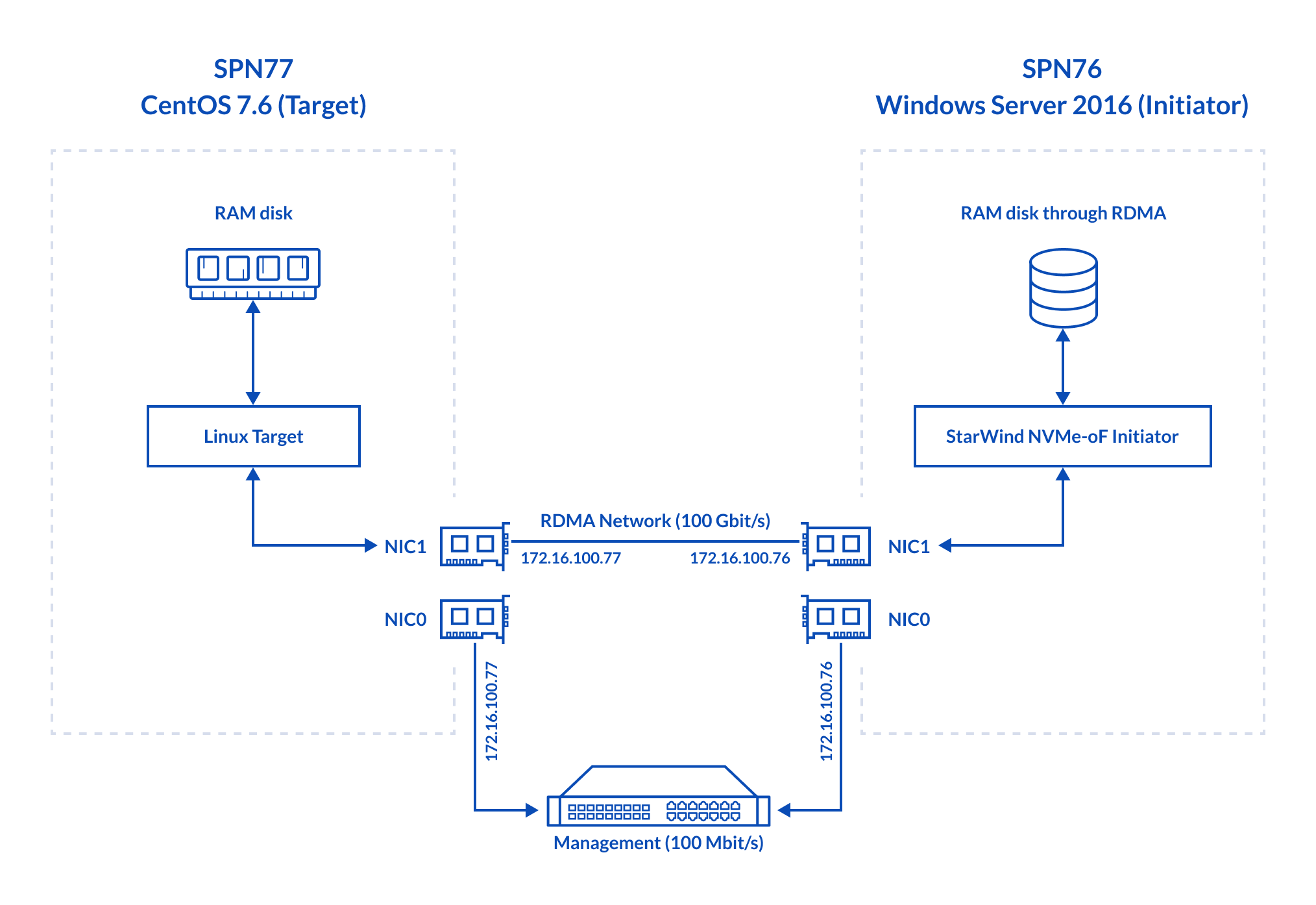
Linux SPDK RAM disk NVMe-oF Target ↔ StarWind NVMe-oF Initiator
Linux SPDK Optane NVMe-oF Target ↔ StarWind NVME-oF Initiator
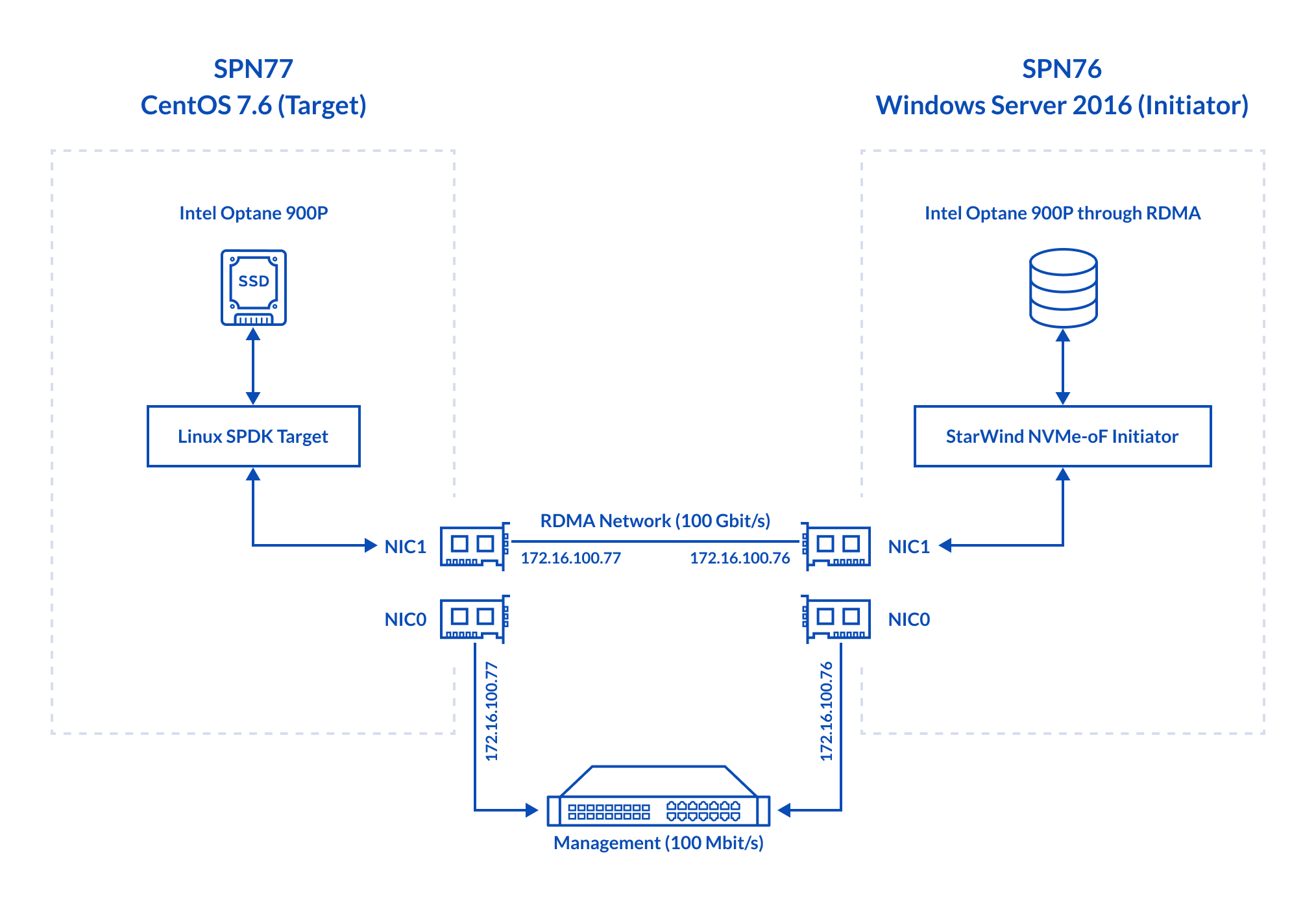
Now, let’s talk more about the hardware configuration of my test environment. Here’s the hardware on the Target side (SPN77):
- Dell PowerEdge R730, CPU 2x Intel Xeon E5-2683 v3 CPU @ 2.00GHz, 128 GB
- Network: Mellanox Connect x4 100 Gbps
- Storage: Intel Optane 900P
- OS: CentOS 7.6 (Kernel 4.19.34) (Target)
Here’s what was inside the Initiator host (SPN76):
- Dell PowerEdge R730, CPU 2x Intel Xeon E5-2683 v3 @ 2.00GHz, 128 GB
- Network: Mellanox Connect x4 100 Gbps
- OS: Windows Server 2016
Today I measure how efficiently the storage of the Target host (SPN76) can be presented over RDMA by means of StarWind NVMe-oF Initiator+ Linux SPDK NVMe-oF Target. The latter was installed on the Target side, SPN77. Network throughput between hosts was measured with rPerf (RDMA) and iPerf (TCP).
MEASURING NETWORK BANDWIDTH
Before starting the actual tests, let’s see whether Mellanox ConnectX-4 can provide decent network throughput.
NOTE: CentOS starting with Kernel 4.19.34 comes with Mellanox drivers installed (i.e., there’s no need to install them manually). Here’s how to load Mellanox ConnectX-4 drivers.
##### Load Mellanox ConnectX-4 drivers.
modprobe mlx5_core
##### Check whether the drivers were loaded with the command below.
lsmod | grep mlx
##### The output below shows that InfiniBand (mlx5_ib) and mlx5_core drivers were successfully loaded.
mlx5_ib 167936 0
ib_core 208896 14 ib_iser,ib_cm,rdma_cm,ib_umad,ib_srp,ib_isert,ib_uverbs,rpcrdma,ib_ipoib,iw_cm,mlx5_ib,ib_srpt,ib_ucm,rdma_ucm
mlx5_core 188416 1 mlx5_ib
######Now, install Mellanox OFED for Windows (http://www.mellanox.com/page/products_dyn?product_family=32&mtag=windows_sw_drivers) on SPN76.
Next, I checked whether NIC-s in my setup support RDMA. I used the rPerf (https://www.starwindsoftware.com/resource-library/starwind-rperf-rdma-performance-benchmarking-tool) utility kit consisting of two utilities: rperf and iperf. In rPerf for Windows, they are called nd_rping and rd_rperf respectively. The former is a qualitative tool allowing to see whether hosts can talk over RDMA while the latter allows for the qualitative analysis of host connectivity.
Install rPerf on both servers and see whether hosts can talk over RDMA.
On the Initiator host, start the utility with the –s flag (i.e., server mode).
nd_rping -s -a 172.16.100.76 –vRun rping on Target (SPN77) in the client mode (-c flag) next.
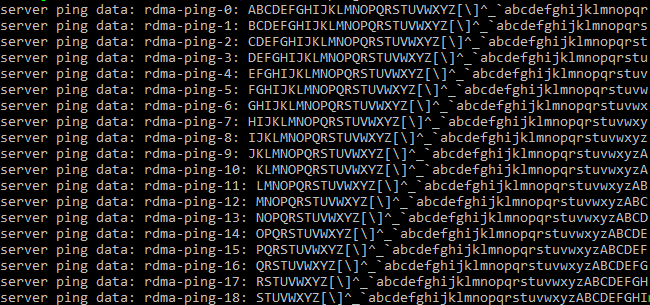
rping -c -a 172.16.100.77 -vBeing set like that, SPN77 starts talking to SPN76 over RDMA. Although it looks that I have assigned the roles wrong (in my case, Target talks to Initiator), rping will still work fine as it just doesn’t care about Target and Initiator; NIC’s ability to talk over RDMA is the only thing that matters for this piece of software.
Here’s the output proving that there’s RDMA connection between the servers.
Now, let’s benchmark Mellanox ConnectX-4 throughput over TCP with iPerf. You can download this utility here: https://iperf.fr/iperf-download.php#windows.
Here’s the command for installing iPerf.
yum install iperfiPerf has to be installed on both hosts. One of them has to be run in client mode while another is started as a server. Here’s how to label one host as a client.
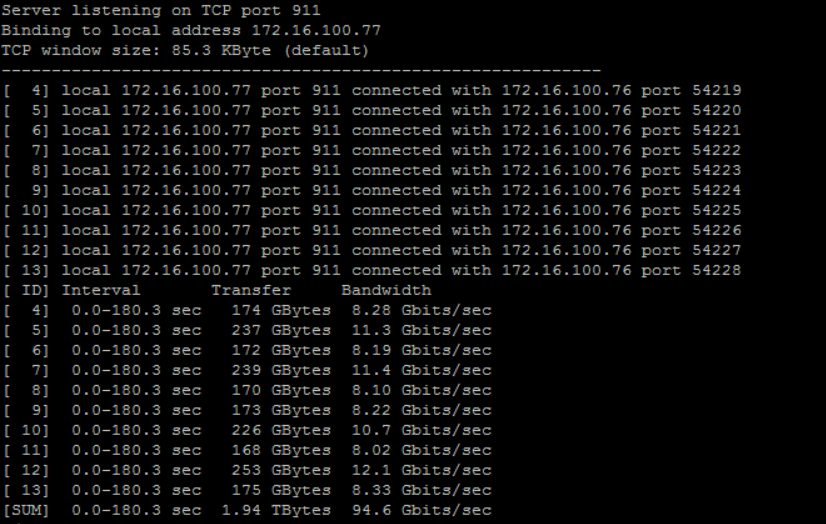
iperf -c 172.16.100.77 -p 911 -P 8 -w 512K -l 2048K -t 180 -i10Find the command to run the utility in the server mode below.
iperf -s -p 911Here’s the output showing what TCP throughput was like.
Next, RDMA connection was checked with rPerf. Below, find the output showing what network throughput was like when measured in 64k blocks.

(9845.82*8)/1024=76.9 Gbps
Let’s measure RDMA connection throughput in 4k blocks now.

(4265.90*8)/1024=33.32 Gbps
Discussion
The network won’t be a bottleneck. The observed RDMA and TCP network throughputs (77 Gbps and 94.6 Gbps respectively) were close enough to Mellanox ConnectX-4 network bandwidth, meaning that network doesn’t limit the underlying storage performance.
CONFIGURING THE TARGET AND INITIATOR
Install nvmecli
Install nvmecli on both servers using this command.
git clone https://github.com/linux-nvme/nvme-cli.git
cd nvme-cli
make
make installStart the Initiator on SPN77 and SPN76
modprobe nvme-rdma
modprobe nvmeAfterward, you can move to configuring a RAM disk.
Setting up a RAM disk
You need targetcli (http://linux-iscsi.org/wiki/Targetcli) to create a RAM disk. Find the command to install it below:
yum install targetcli –yNext, run these commands to make sure that targetcli will be running even after a host reboot.
systemctl start target
systemctl enable targetCreate a 1 GB RAM disk with targetcli and present it as a block device.
##### Create the RAM disk.
targetcli /backstores/ramdisk create 1 1G
##### Create a loopback mount point (naa.5001*****).
targetcli /loopback/ create naa.500140591cac7a64
##### Connect the RAM disk to the loopback mount point.
targetcli /loopback/naa.500140591cac7a64/luns create /backstores/ramdisk/1Now, check whether the disk was created with Lsblk. Here’s the output after the disk has been successfully created.
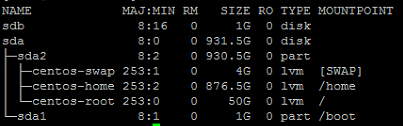
RAM disk is listed as the /dev/sdb directory.
Setting up the Target
To start with, download SPDK (https://spdk.io/doc/about.html).
git clone https://github.com/spdk/spdk
cd spdk
git submodule update –init
##### Install the package automatically using the command below.
sudo scripts/pkgdep.sh
##### Set up SPDK and enable RDMA.
./configure --with-rdma
Make
##### Now, run setup.sh to start working with SPDK.
sudo scripts/setup.shHere’s how a configuration retrieved from nvmf.conf looks like (find this file in spdk/etc/spdk/).
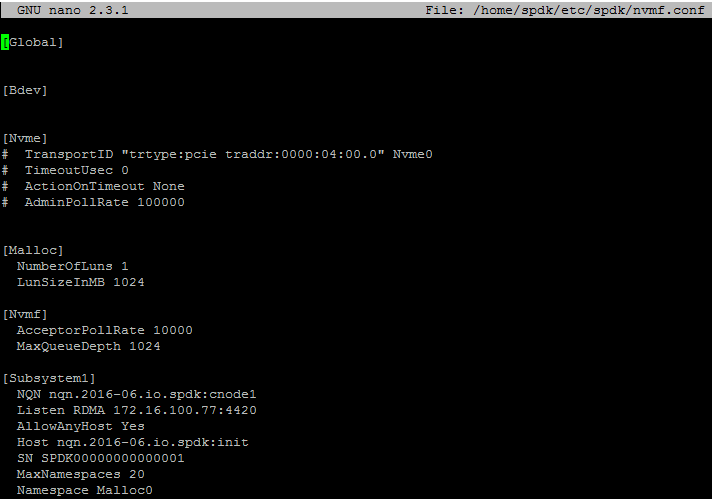
Now, take a look at the config file for Intel Optane 900P benchmarking.
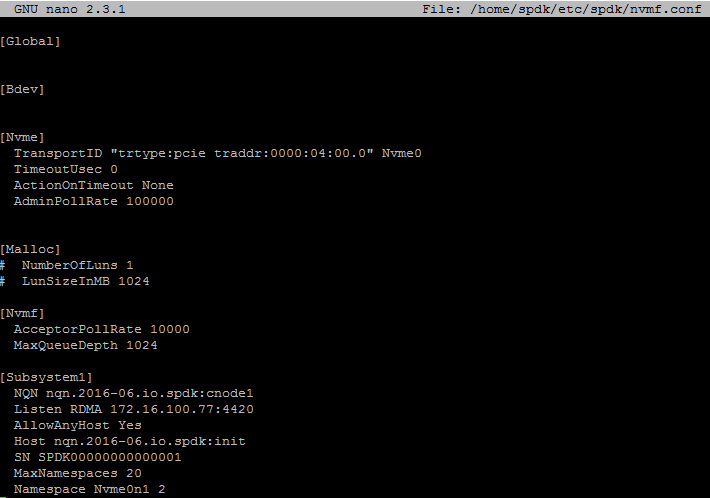
Here’s the command to start the target:
cd spdk/app/nvmf_tgt
./nvmf_tgt -c ../../etc/spdk/nvmf.confSetting up the Initiator
Before you start the initiator, it is necessary to deploy the prepare_test_machine.cmd script. It installs certificates and sets the server into Test mode. Note that the host reboots shortly after running the script. You also need to disable integrity check to be able to install self-signed certificates.
Here’s the prepare_test_machine.cmd listing.
@echo off
REM Prepares client machine for using test build of the driver
certutil -enterprise -addstore "Root" "%~dp0StarNVMeoF.cer"
bcdedit.exe /set TESTSIGNING ON
bcdedit.exe /set loadoptions DDISABLE_INTEGRITY_CHECKS
echo.
echo.
echo Machine will be restarted now.
pause
shutdown /rNow, you need to install the Initiator driver. You can do that only manually. See how that can be done below.
1. Go to Device Manager and press Add legacy hardware.
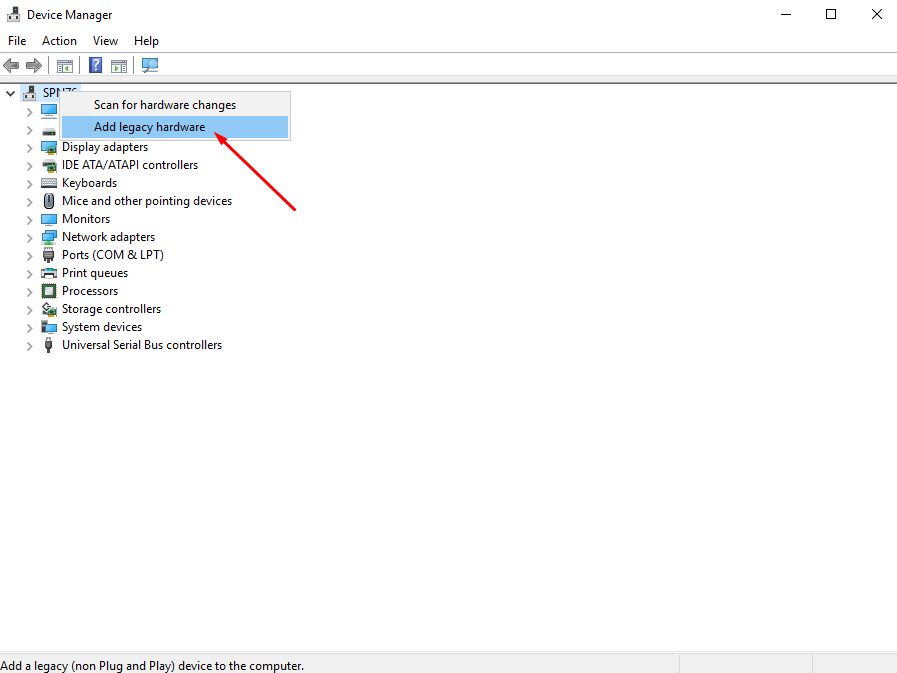
2. Next, tick the Install the hardware that I manually select from a list option.
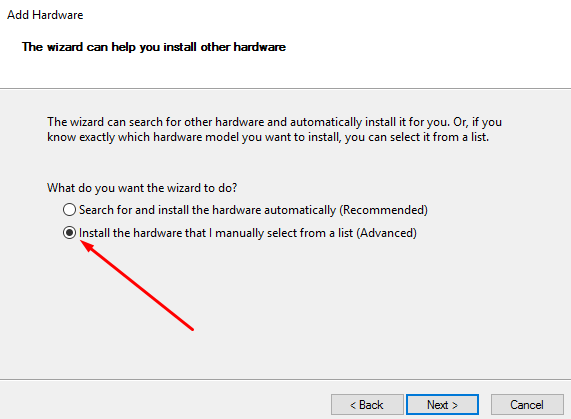
3. Press Show All Devices afterward.
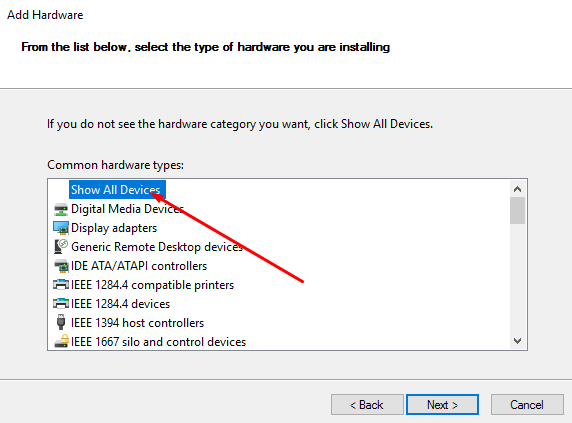
4. Open the Have Disk menu.
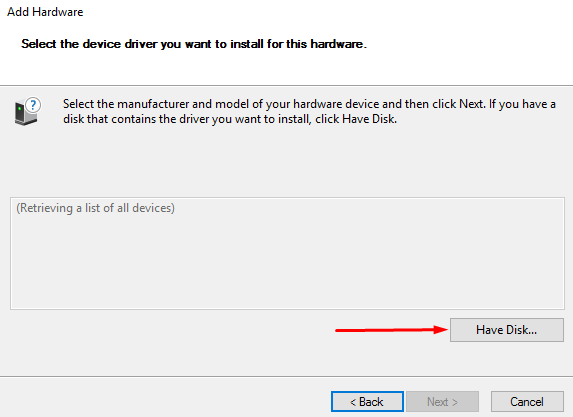
5. Specify the path to StarNVMeoF.inf.
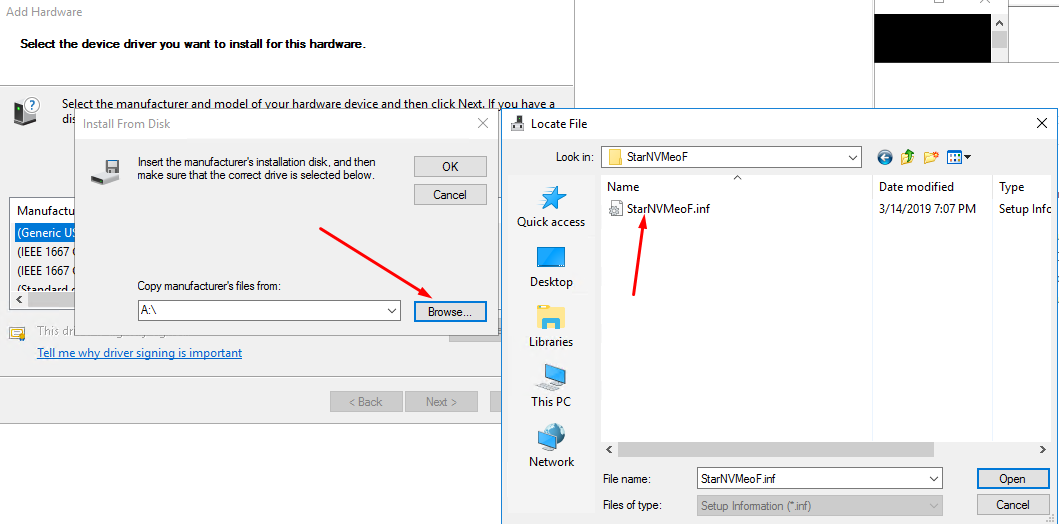
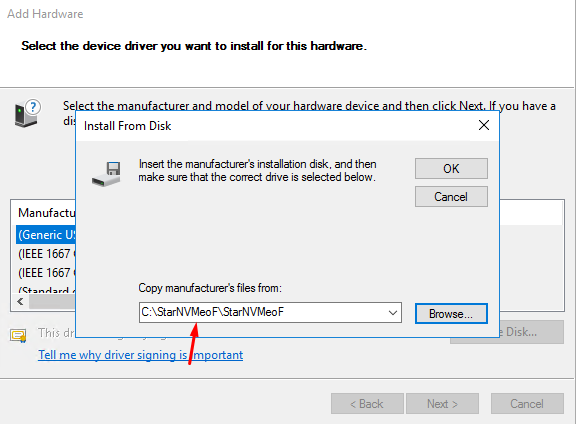
6. If everything was done right, StarWind NVMe over Fabrics Storage Controller would be listed in the Model field.
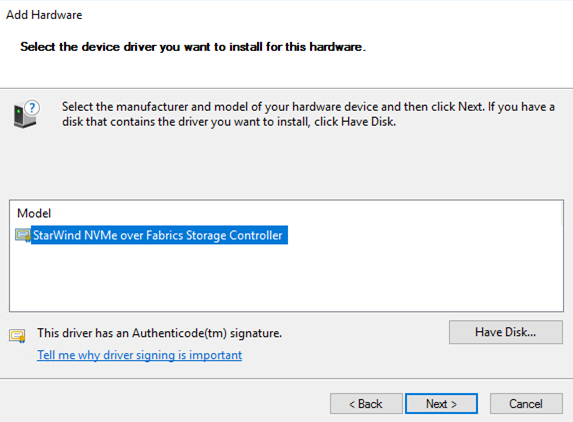
7. Press Next.
8. Wait until the Add Hardware wizard finishes.
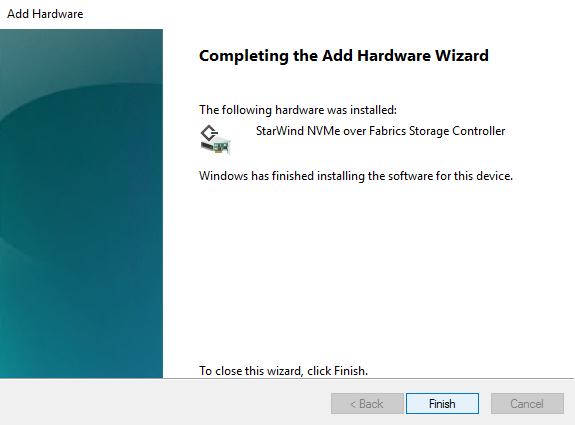
9. StarWind NVMe over Fabrics Storage Controller is now on the Storage controllers list.
Now, let’s start fine-tuning StarWind NVMe-oF Initiator.
1. Open StarNVMeoF_Ctrl.exe via CLI as administrator.
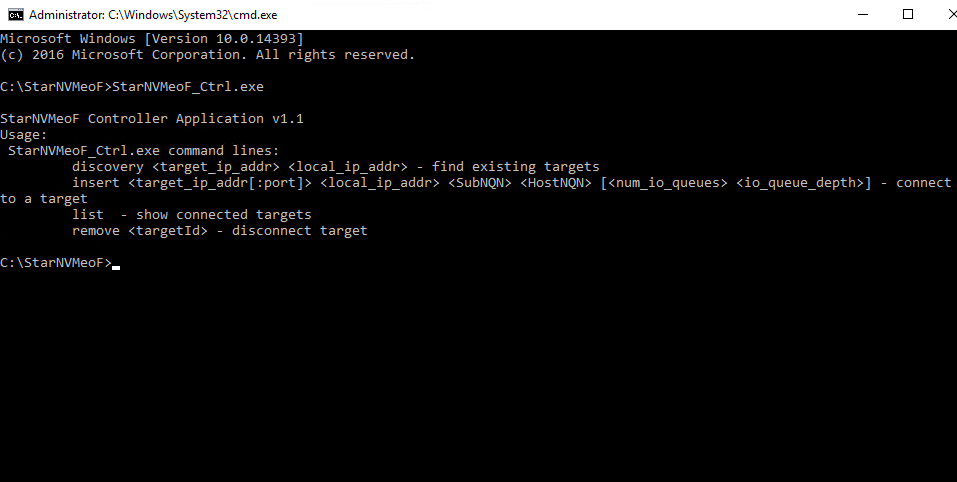
2. If you start StarNVMeoF_Ctrl.exe without any parameters, you’ll get the list of available commands.
StarNVMeoF Controller Application v1.1
Usage:
StarNVMeoF_Ctrl.exe command lines:
discovery <target_ip_addr> <local_ip_addr> - find existing targets
insert <target_ip_addr[:port]> <local_ip_addr> <SubNQN> <HostNQN> [<num_io_queues> <io_queue_depth>] - connect to a target
list - show connected targets
remove <targetId> - disconnect target3. Once target and initiator IP-s are specified, StarNVMeoF_Ctrl.exe discovery lists all available devices. Use the command below to enter the IP-s.
StarNVMeoF_Ctrl.exe discovery 172.16.100.77 172.16.100.764. Next, specify target and initiator NQN (initiator NQN in my case is nqn.2008-08.com.starwindsoftware). Here’s the command allowing to do that:
StarNVMeoF_Ctrl.exe insert 172.16.100.77:4420 172.16.100.76 nqn.2016-06.io.spdk:cnode1 nqn.2008-08.com.starwindsoftwareHere are 2 more commands that may be interesting for you to know:
StarNVMeoF_Ctrl.exe list this command shows all the connected devices.
StarNVMeoF_Ctrl.exe remove disconnects the specific device from the initiator.
HOW I MEASURED EVERYTHING HERE
I think that it is a good idea to discuss how I carried out the measurements before moving to them.
Create a RAM disk with targetcli. Connect this disk as a local block device and benchmark its performance with FIO. RAM disk performance is going to be used as a reference only for the second step. Note that it is the maximum performance that can be observed for RAM disk in my setup.
Create an SPDK NVMe-oF target on the RAM disk (it is called Malloc in SPDK) on the Target host (SPN77). Connect the disk to Linux NVMe-oF Initiator located on the same host over loopback. Measure disk performance; that’s the new reference, i.e., the highest possible performance when the disk is presented to an initiator.
Create an SPDK NVMe-oF target on the RAM disk that resides on the Target side (SPN77). Present it over RDMA to the Initiator host (SPN76). Measure RAM disk performance over RDMA and compare it to the performance observed for a local RAM disk connected over loopback to the Initiator on the same host.
Connect Intel Optane 900P to SPN77 and benchmark it with FIO. This is the local drive performance that should be close to the value which one may find in vendor’s datasheet; no wonders that I use it as the ultimate reference.
On SPN77, present Intel Optane 900P to the local Linux NVMe-oF initiator by means of Linux SPDK NVMe-oF Target. That’s the reference that I use here to judge on StarWind NVMe-oF Initiator performance.
Measure NVMe drive performance while it is presented over the network. To do that, present Intel Optane 900P on SPN77 over RDMA to the Initiator on SPN76.
Herein, I used FIO (https://github.com/axboe/fio) for storage performance measurements.
Here are two ways of how you can install it. You can install it as a software package. Just use the command below.
sudo yum install fio –yOr, you can install it from the source using this set of commands:
git clone https://github.com/axboe/fio.git
cd fio/
./configure
make && make installBENCHMARKING THE RAM DISK
Picking the optimal test utility parameters
Before I start the real measurements, I’d like to find the optimal test utility parameters, i.e., such numjobs (number of treads) and iodepth (queue depth) values that ensure the best possible disk performance. To find these parameters, I measured 4k random reading performance. In my tests, I had the numjobs parameter fixed while varying iodepth. I run these measurements for various numbers of threads (1, 2, 4, 8). Below, find how the FIO listing looked like for varying queue depth under numjobs=1.
[global]
numjobs=1
loops=1
time_based
ioengine=libaio
direct=1
runtime=60
filename=/dev/sdb
[4k-rnd-read-o1]
bs=4k
iodepth=1
rw=randread
stonewall
[4k-rnd-read-o2]
bs=4k
iodepth=2
rw=randread
stonewall
[4k-rnd-read-o4]
bs=4k
iodepth=4
rw=randread
stonewall
[4k-rnd-read-o8]
bs=4k
iodepth=8
rw=randread
stonewall
[4k-rnd-read-o16]
bs=4k
iodepth=16
rw=randread
stonewall
[4k-rnd-read-o32]
bs=4k
iodepth=32
rw=randread
stonewall
[4k-rnd-read-o64]
bs=4k
iodepth=64
rw=randread
stonewall
[4k-rnd-read-o128]
bs=4k
iodepth=128
rw=randread
stonewallHere are the numbers I got.
| Pre-test RAM disk local | ||||
|---|---|---|---|---|
| 1 Thread | 2 Threads | 4 Threads | 8 Threads | |
| Job name | Total IOPS | Total IOPS | Total IOPS | Total IOPS |
| 4k rnd read 1 Oio | 76643 | 143603 | 252945 | 422235 |
| 4k rnd read 2 Oio | 137375 | 250713 | 370232 | 642717 |
| 4k rnd read 4 Oio | 237949 | 361120 | 626944 | 760285 |
| 4k rnd read 8 Oio | 266837 | 304866 | 654640 | 675861 |
| 4k rnd read 16 Oio | 275301 | 359231 | 635906 | 736538 |
| 4k rnd read 32 Oio | 173942 | 303148 | 652155 | 707239 |
| 4k rnd read 64 Oio | 262701 | 359237 | 653462 | 723969 |
| 4k rnd read 128 Oio | 173718 | 363937 | 655095 | 733124 |
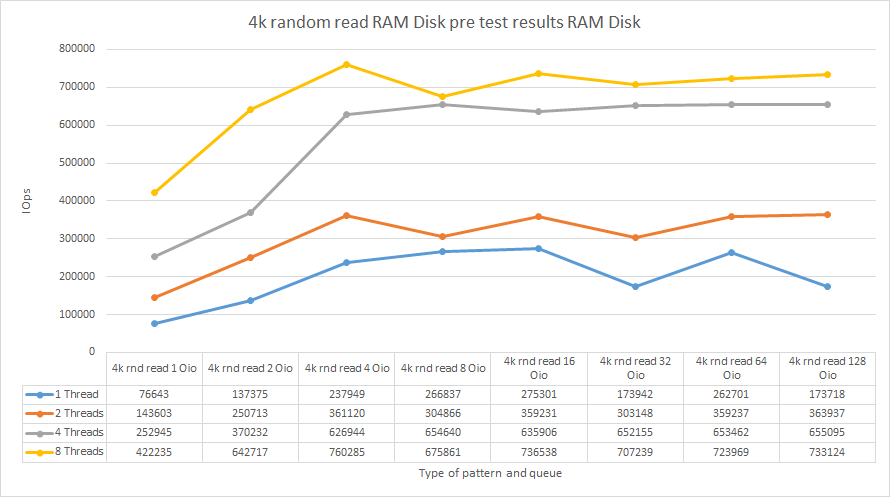
Discussion
According to the plot above, numjobs = 8 iodepth = 4 are the optimal FIO parameters for testing RAM disk performance. Below, find the test utility listing.
[global]
numjobs=8
iodepth=4
loops=1
time_based
ioengine=libaio
direct=1
runtime=60
filename=/dev/sdb
[4k sequential write]
rw=write
bs=4k
stonewall
[4k random write]
rw=randwrite
bs=4k
stonewall
[64k sequential write]
rw=write
bs=64k
stonewall
[64k random write]
rw=randwrite
bs=64k
stonewall
[4k sequential read]
rw=read
bs=4k
stonewall
[4k random read]
rw=randread
bs=4k
stonewall
[64k sequential read]
rw=read
bs=64k
stonewall
[64k random read]
rw=randread
bs=64k
stonewall
[4k sequential 50write]
rw=write
rwmixread=50
bs=4k
stonewall
[4k random 50write]
rw=randwrite
rwmixread=50
bs=4k
stonewall
[64k sequential 50write]
rw=write
rwmixread=50
bs=64k
stonewall
[64k random 50write]
rw=randwrite
rwmixread=50
bs=64k
stonewall
[8k random 70write]
bs=8k
rwmixread=70
rw=randrw
stonewallRAM disk performance (connected via loopback)
| RAM Disk loopback (127.0.0.1) Linux SPDK NVMe-oF Target | |||
|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 709451 | 2771.30 | 0.04 |
| 4k random read | 709439 | 2771.26 | 0.04 |
| 4k random write | 703042 | 2746.27 | 0.04 |
| 4k sequential 50write | 715444 | 2794.71 | 0.04 |
| 4k sequential read | 753439 | 2943.14 | 0.04 |
| 4k sequential write | 713012 | 2785.22 | 0.05 |
| 64k random 50write | 79322 | 4957.85 | 0.39 |
| 64k random read | 103076 | 6442.53 | 0.30 |
| 64k random write | 78188 | 4887.01 | 0.40 |
| 64k sequential 50write | 81830 | 5114.63 | 0.38 |
| 64k sequential read | 131613 | 8226.06 | 0.23 |
| 64k sequential write | 79085 | 4943.10 | 0.39 |
| 8k random 70% write | 465745 | 3638.69 | 0.07 |
RAM disk performance (presented over RDMA)
| RAM Disk on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||
|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 444771 | 1737.40 | 0.05 |
| 4k random read | 460792 | 1799.98 | 0.05 |
| 4k random write | 452992 | 1769.51 | 0.05 |
| 4k sequential 50write | 455858 | 1780.71 | 0.05 |
| 4k sequential read | 464746 | 1815.43 | 0.05 |
| 4k sequential write | 438501 | 1712.90 | 0.05 |
| 64k random 50write | 78034 | 4877.35 | 0.39 |
| 64k random read | 101369 | 6335.77 | 0.30 |
| 64k random write | 78002 | 4875.36 | 0.39 |
| 64k sequential 50write | 80823 | 5051.73 | 0.38 |
| 64k sequential read | 119170 | 7448.45 | 0.25 |
| 64k sequential write | 79272 | 4954.69 | 0.38 |
| 8k random 70% write | 427503 | 3339.91 | 0.05 |
CAN I SQUEEZE ALL THE IOPS OUT OF AN INTEL OPTANE 900P?
Picking the optimal test utility parameters
Let’s find the best possible FIO settings. I ran a bunch of tests for different numbers of threads under varying queue depth (4k random read).
Here’s what performance is like.
| 1 Thread | 2 Threads | 4 Threads | 8 Threads | |
|---|---|---|---|---|
| Job name | Total IOPS | Total IOPS | Total IOPS | Total IOPS |
| 4k rnd read 1 Oio | 45061 | 93018 | 169969 | 329122 |
| 4k rnd read 2 Oio | 90228 | 185013 | 334426 | 528235 |
| 4k rnd read 4 Oio | 206207 | 311442 | 522387 | 587002 |
| 4k rnd read 8 Oio | 146632 | 389886 | 586678 | 586956 |
| 4k rnd read 16 Oio | 233125 | 305204 | 526101 | 571693 |
| 4k rnd read 32 Oio | 144596 | 443912 | 585933 | 584758 |
| 4k rnd read 64 Oio | 232987 | 304255 | 520358 | 586612 |
| 4k rnd read 128 Oio | 146828 | 448596 | 581580 | 580075 |
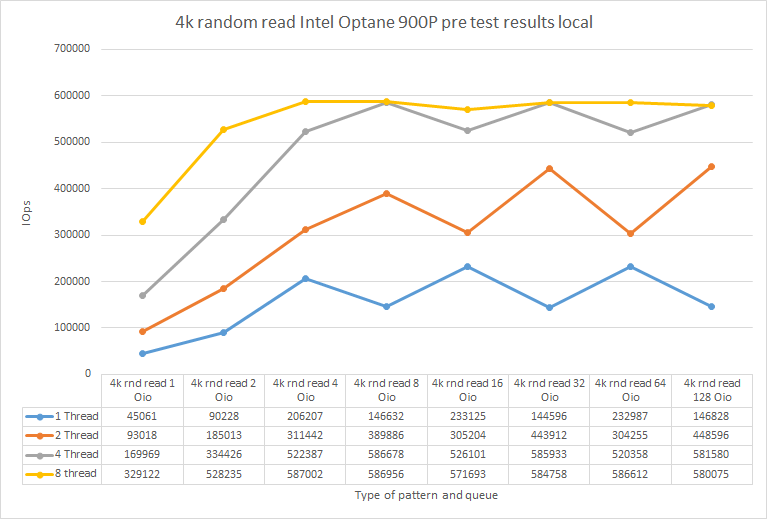
Discussion
Under numjobs = 8 iodepth =4, I basically reached performance from Intel’s datasheet: https://ark.intel.com/content/www/us/en/ark/products/123628/intel-optane-ssd-900p-series-280gb-1-2-height-pcie-x4-20nm-3d-xpoint.html (see the screenshot below). This means that these test utility parameters are the optimal ones.
Intel Optane 900P performance (connected over loopback)
| Intel Optane 900P loopback (127.0.0.1) Linux SPDK NVMe-oF Target | |||
|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 550744 | 2151.35 | 0.05 |
| 4k random read | 586964 | 2292.84 | 0.05 |
| 4k random write | 550865 | 2151.82 | 0.05 |
| 4k sequential 50write | 509616 | 1990.70 | 0.06 |
| 4k sequential read | 590101 | 2305.09 | 0.05 |
| 4k sequential write | 537876 | 2101.09 | 0.06 |
| 64k random 50write | 34566 | 2160.66 | 0.91 |
| 64k random read | 40733 | 2546.02 | 0.77 |
| 64k random write | 34590 | 2162.01 | 0.91 |
| 64k sequential 50write | 34201 | 2137.77 | 0.92 |
| 64k sequential read | 41418 | 2588.87 | 0.76 |
| 64k sequential write | 34499 | 2156.53 | 0.91 |
| 8k random 70% write | 256435 | 2003.45 | 0.12 |
Intel Optane 900P performance (presented over RDMA)
| Intel Optane 900P on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||
|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 397173 | 1551.47 | 0.06 |
| 4k random read | 434979 | 1699.15 | 0.05 |
| 4k random write | 405553 | 1584.20 | 0.06 |
| 4k sequential 50write | 398307 | 1555.89 | 0.06 |
| 4k sequential read | 444763 | 1737.37 | 0.05 |
| 4k sequential write | 385254 | 1504.91 | 0.06 |
| 64k random 50write | 34822 | 2176.51 | 0.91 |
| 64k random read | 40733 | 2546.04 | 0.77 |
| 64k random write | 34840 | 2177.88 | 0.91 |
| 64k sequential 50write | 31168 | 1948.23 | 1.01 |
| 64k sequential read | 40936 | 2558.75 | 0.77 |
| 64k sequential write | 32080 | 2005.06 | 0.99 |
| 8k random 70% write | 256474 | 2003.76 | 0.11 |
RESULTS
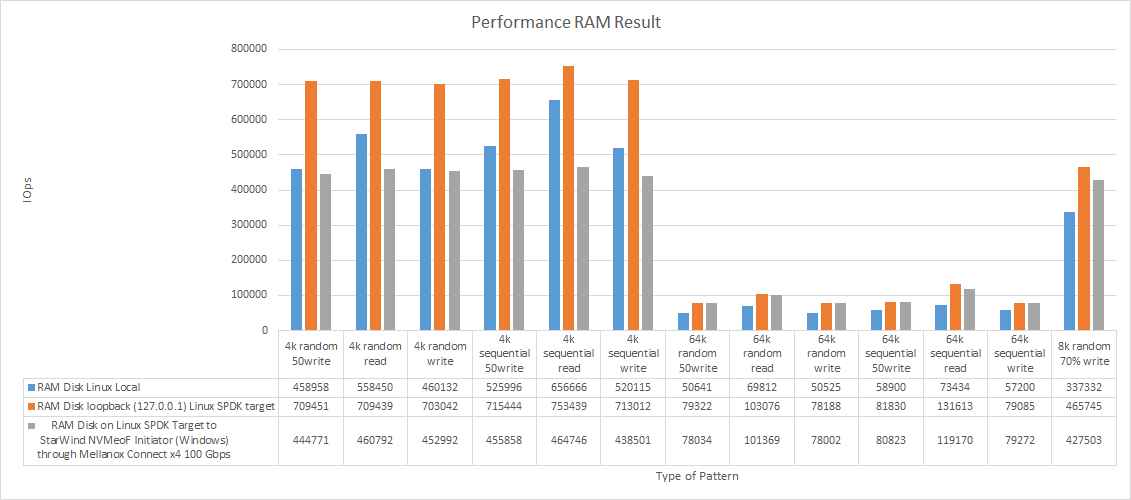
RAM disk
| RAM Disk Linux (local) | RAM Disk loopback (127.0.0.1) Linux SPDK NVMe-oF Target | RAM Disk on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||||||
|---|---|---|---|---|---|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 458958 | 1792.81 | 0.07 | 709451 | 2771.30 | 0.04 | 444771 | 1737.40 | 0.05 |
| 4k random read | 558450 | 2181.45 | 0.05 | 709439 | 2771.26 | 0.04 | 460792 | 1799.98 | 0.05 |
| 4k random write | 460132 | 1797.40 | 0.07 | 703042 | 2746.27 | 0.04 | 452992 | 1769.51 | 0.05 |
| 4k sequential 50write | 525996 | 2054.68 | 0.06 | 715444 | 2794.71 | 0.04 | 455858 | 1780.71 | 0.05 |
| 4k sequential read | 656666 | 2565.11 | 0.05 | 753439 | 2943.14 | 0.04 | 464746 | 1815.43 | 0.05 |
| 4k sequential write | 520115 | 2031.71 | 0.06 | 713012 | 2785.22 | 0.05 | 438501 | 1712.90 | 0.05 |
| 64k random 50write | 50641 | 3165.26 | 0.62 | 79322 | 4957.85 | 0.39 | 78034 | 4877.35 | 0.39 |
| 64k random read | 69812 | 4363.57 | 0.45 | 103076 | 6442.53 | 0.30 | 101369 | 6335.77 | 0.30 |
| 64k random write | 50525 | 3158.06 | 0.62 | 78188 | 4887.01 | 0.40 | 78002 | 4875.36 | 0.39 |
| 64k sequential 50write | 58900 | 3681.56 | 0.53 | 81830 | 5114.63 | 0.38 | 80823 | 5051.73 | 0.38 |
| 64k sequential read | 73434 | 4589.86 | 0.42 | 131613 | 8226.06 | 0.23 | 119170 | 7448.45 | 0.25 |
| 64k sequential write | 57200 | 3575.31 | 0.54 | 79085 | 4943.10 | 0.39 | 79272 | 4954.69 | 0.38 |
| 8k random 70% write | 337332 | 2635.47 | 0.09 | 465745 | 3638.69 | 0.07 | 427503 | 3339.91 | 0.05 |
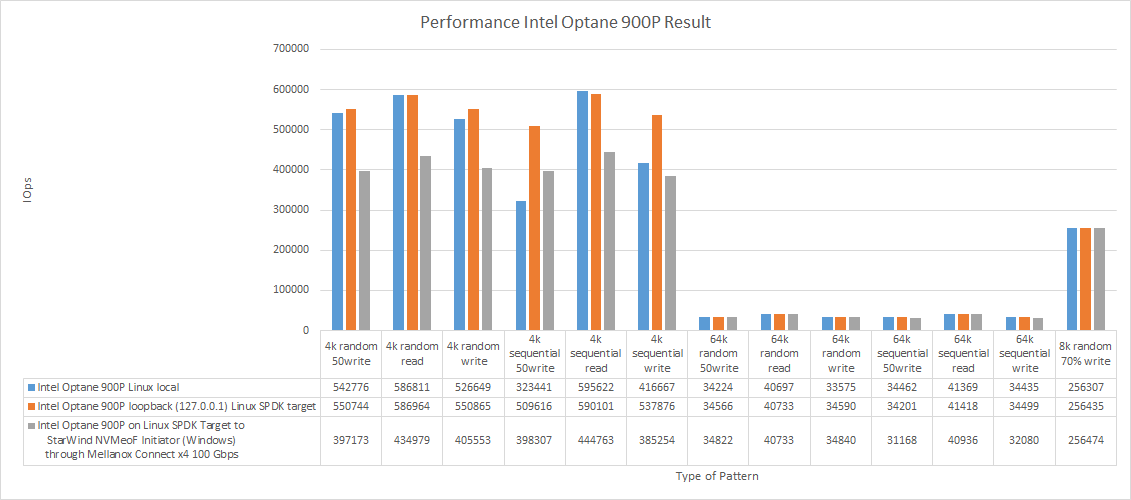
Intel Optane results
| Intel Optane 900P Linux (local) | Intel Optane 900P loopback (127.0.0.1) Linux SPDK NVMe-oF Target | Intel Optane 900P on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||||||
|---|---|---|---|---|---|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 542776 | 2120.23 | 0.05 | 550744 | 2151.35 | 0.05 | 397173 | 1551.47 | 0.06 |
| 4k random read | 586811 | 2292.24 | 0.05 | 586964 | 2292.84 | 0.05 | 434979 | 1699.15 | 0.05 |
| 4k random write | 526649 | 2057.23 | 0.06 | 550865 | 2151.82 | 0.05 | 405553 | 1584.20 | 0.06 |
| 4k sequential 50write | 323441 | 1263.45 | 0.09 | 509616 | 1990.70 | 0.06 | 398307 | 1555.89 | 0.06 |
| 4k sequential read | 595622 | 2326.66 | 0.05 | 590101 | 2305.09 | 0.05 | 444763 | 1737.37 | 0.05 |
| 4k sequential write | 416667 | 1627.61 | 0.07 | 537876 | 2101.09 | 0.06 | 385254 | 1504.91 | 0.06 |
| 64k random 50write | 34224 | 2139.32 | 0.92 | 34566 | 2160.66 | 0.91 | 34822 | 2176.51 | 0.91 |
| 64k random read | 40697 | 2543.86 | 0.77 | 40733 | 2546.02 | 0.77 | 40733 | 2546.04 | 0.77 |
| 64k random write | 33575 | 2098.76 | 0.94 | 34590 | 2162.01 | 0.91 | 34840 | 2177.88 | 0.91 |
| 64k sequential 50write | 34462 | 2154.10 | 0.91 | 34201 | 2137.77 | 0.92 | 31168 | 1948.23 | 1.01 |
| 64k sequential read | 41369 | 2585.79 | 0.76 | 41418 | 2588.87 | 0.76 | 40936 | 2558.75 | 0.77 |
| 64k sequential write | 34435 | 2152.52 | 0.91 | 34499 | 2156.53 | 0.91 | 32080 | 2005.06 | 0.99 |
| 8k random 70% write | 256307 | 2002.46 | 0.12 | 256435 | 2003.45 | 0.12 | 256474 | 2003.76 | 0.11 |
Discussion
In 64k blocks, RAM disk, while being presented over RDMA, reached the same performance as when it was connected over loopback. In 4k blocks though, RAM disk, while being presented over RDMA, exhibited significantly lower performance than when it was connected over loopback (250K-300K IOPS less).
For Intel Optane 900P, things looked more or less the same. In 64k blocks, Intel Optane 900P provided the same performance over RDMA as when it was connected to the local target via loopback. In 4k blocks, the drive exhibited roughly 100 000 – 150 000 IOPS lower performance than while being connected locally.
WHAT ABOUT THE LATENCY?
Performance is just as important metric as the latency, so I think that this study cannot be considered complete without latency measurements. FIO settings: numjobs = 1 iodepth = 1.
RAM disk
| RAM Disk Linux (local) | RAM Disk on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||||
|---|---|---|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 97108 | 379.33 | 0.0069433 | 22671 | 88.56 | 0.0344373 |
| 4k random read | 114417 | 446.94 | 0.0056437 | 22841 | 89.23 | 0.0345294 |
| 4k random write | 95863 | 374.46 | 0.0070643 | 23049 | 90.04 | 0.0341427 |
| 4k sequential 50write | 107010 | 418.01 | 0.0061421 | 23020 | 89.92 | 0.0341291 |
| 4k sequential read | 117168 | 457.69 | 0.0054994 | 22910 | 89.49 | 0.0344851 |
| 4k sequential write | 98065 | 383.07 | 0.0068343 | 22906 | 89.48 | 0.0342793 |
| 64k random 50write | 27901 | 1743.87 | 0.0266555 | 13665 | 854.07 | 0.0609151 |
| 64k random read | 36098 | 2256.14 | 0.0203593 | 15826 | 989.18 | 0.0520607 |
| 64k random write | 28455 | 1778.48 | 0.0260830 | 14614 | 913.38 | 0.0546317 |
| 64k sequential 50write | 28534 | 1783.42 | 0.0262397 | 12820 | 801.27 | 0.0634169 |
| 64k sequential read | 36727 | 2295.44 | 0.0200747 | 15918 | 994.93 | 0.0518925 |
| 64k sequential write | 28988 | 1811.78 | 0.0256918 | 13737 | 858.61 | 0.0605783 |
| 8k random 70% write | 85051 | 664.47 | 0.0083130 | 21648 | 169.13 | 0.0381733 |
Intel Optane
| Intel Optane 900P Linux (local) | Intel Optane 900P on Linux SPDK NVMe-oF Target to StarWind NVMe-oF Initiator (Windows) through Mellanox Connect x4 100 Gbps |
|||||
|---|---|---|---|---|---|---|
| Job name | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) | Total IOPS | Total bandwidth (MB/s) | Average latency (ms) |
| 4k random 50write | 73097 | 285.54 | 0.0108380 | 17563 | 68.61 | 0.0455358 |
| 4k random read | 82615 | 322.72 | 0.0093949 | 18097 | 70.69 | 0.0442594 |
| 4k random write | 73953 | 288.88 | 0.0108047 | 17217 | 67.26 | 0.0463379 |
| 4k sequential 50write | 74555 | 291.23 | 0.0108105 | 17463 | 68.22 | 0.0458633 |
| 4k sequential read | 85858 | 335.39 | 0.0092789 | 18850 | 73.63 | 0.0432678 |
| 4k sequential write | 74998 | 292.96 | 0.0107804 | 19135 | 74.75 | 0.0401418 |
| 64k random 50write | 19119 | 1194.99 | 0.0423029 | 9580 | 598.80 | 0.0899450 |
| 64k random read | 22589 | 1411.87 | 0.0356328 | 11481 | 717.62 | 0.0745408 |
| 64k random write | 18762 | 1172.63 | 0.0427555 | 9653 | 603.36 | 0.0892458 |
| 64k sequential 50write | 19320 | 1207.54 | 0.0423435 | 9629 | 601.84 | 0.0900962 |
| 64k sequential read | 22927 | 1432.96 | 0.0353837 | 10757 | 672.33 | 0.0801468 |
| 64k sequential write | 18663 | 1166.44 | 0.0429796 | 9588 | 599.30 | 0.0901930 |
| 8k random 70% write | 72212 | 564.16 | 0.0114044 | 17258 | 134.84 | 0.0469456 |
CONCLUSION
Today, I measured the performance of an NVMe drive presented over the network with Linux SPDK NVMe-oF Target + StarWind NVMe-oF Initiator for Windows. The main idea was to check whether a solution that brings NVMe-oF to Windows can unleash the whole potential of NVMe drives. StarWind NVMe-oF Initiator is a great solution allowing to enjoy the whole potential of NVMe drives.
In my next article, I sum up the results that I observed before and find out which NVMe-oF Initiator works better for presenting an NVMe SSD over RDMA.
