

Introduction
I guess every IT administrator wants his data to be transferred over the network like a hot knife through butter. So, in order to decrease the latency and ensure the max number of IOPS for data transfers, you should take a closer look at SPDK which stands for Storage Performance Development Kit and NVMe-oF (Nonvolatile Memory Express over Fabrics).
As you probably know, SPDK is an open source set of tools and libraries that help to create high-performing and easily scalable storage applications. It grants high performance by moving all of the necessary drivers into userspace and operating in a polled mode instead of relying on interrupts, which avoids kernel context switches and eliminates interrupt handling overhead.
Nonvolatile Memory Express (NVMe) over Fabrics is a technology specification which enables NVMe message-based commands to transfer data between a host computer and a target solid-state storage device or system over a network such as Ethernet, Fibre Channel, and InfiniBand.
Now, how these two are combined? Well, to support broad adoption of NVMe over Fabrics, SPDK has created a reference user-space NVMe-oF target implementation for Linux for maximum efficiency in dedicated storage contexts. The code is running next to the physical storage devices and handling I/O requests. Like all other SPDK components, the NVMe-oF target is designed to run the whole data path, from network to storage media, in user space, completely bypassing the kernel. And like all other SPDK components, the NVMe-oF target is designed to use a polling-based, asynchronous I/O model instead of dealing with interrupts. These techniques substantially reduce the software latency incurred in the traditional I/O path, maximizing the benefit of new, low-latency storage media. The NVMe over Fabrics target uses RDMA to transfer data over the network and thus, requires an RDMA-capable NIC.
Purpose
So, why am I telling you all this? There’s a common opinion that the performance in general and IOPS-intensive performance like NVMe over Fabrics is usually lower in virtualized environments due to the hypervisor overhead. Therefore, I’ve decided to run a series of tests to prove or knock down this belief. For this purpose, I’ll have three scenarios for measuring the performance of NVMe over Fabrics in different infrastructures: fist – on a bare metal configuration, second – with Microsoft Hyper-V deployed on the client server, and finally, with ESXi 6.5.
In each case, I’ll also compare the performance of NVMe-oF, NVMe-oF over iSER transport, and SPDK iSCSI.
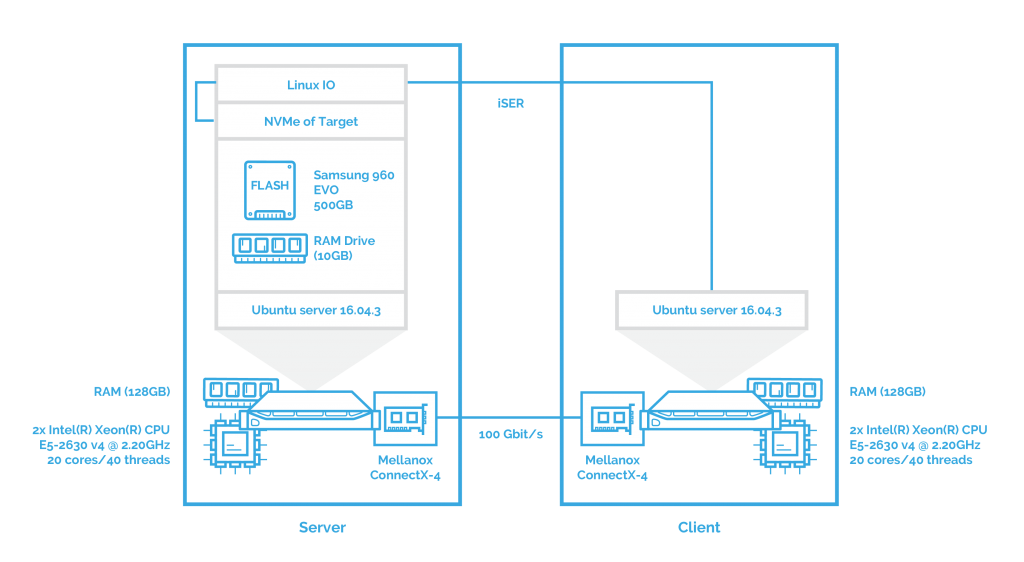
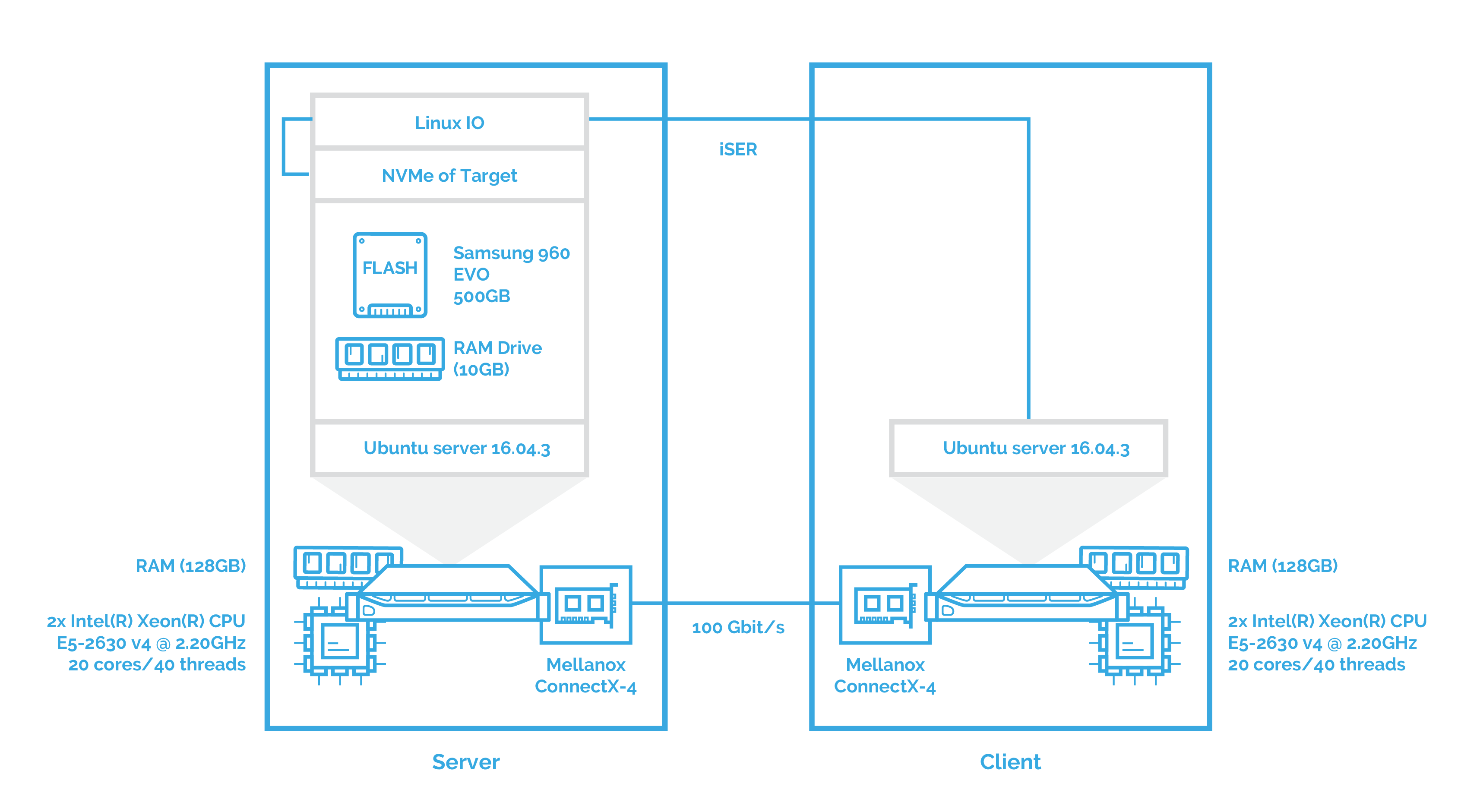
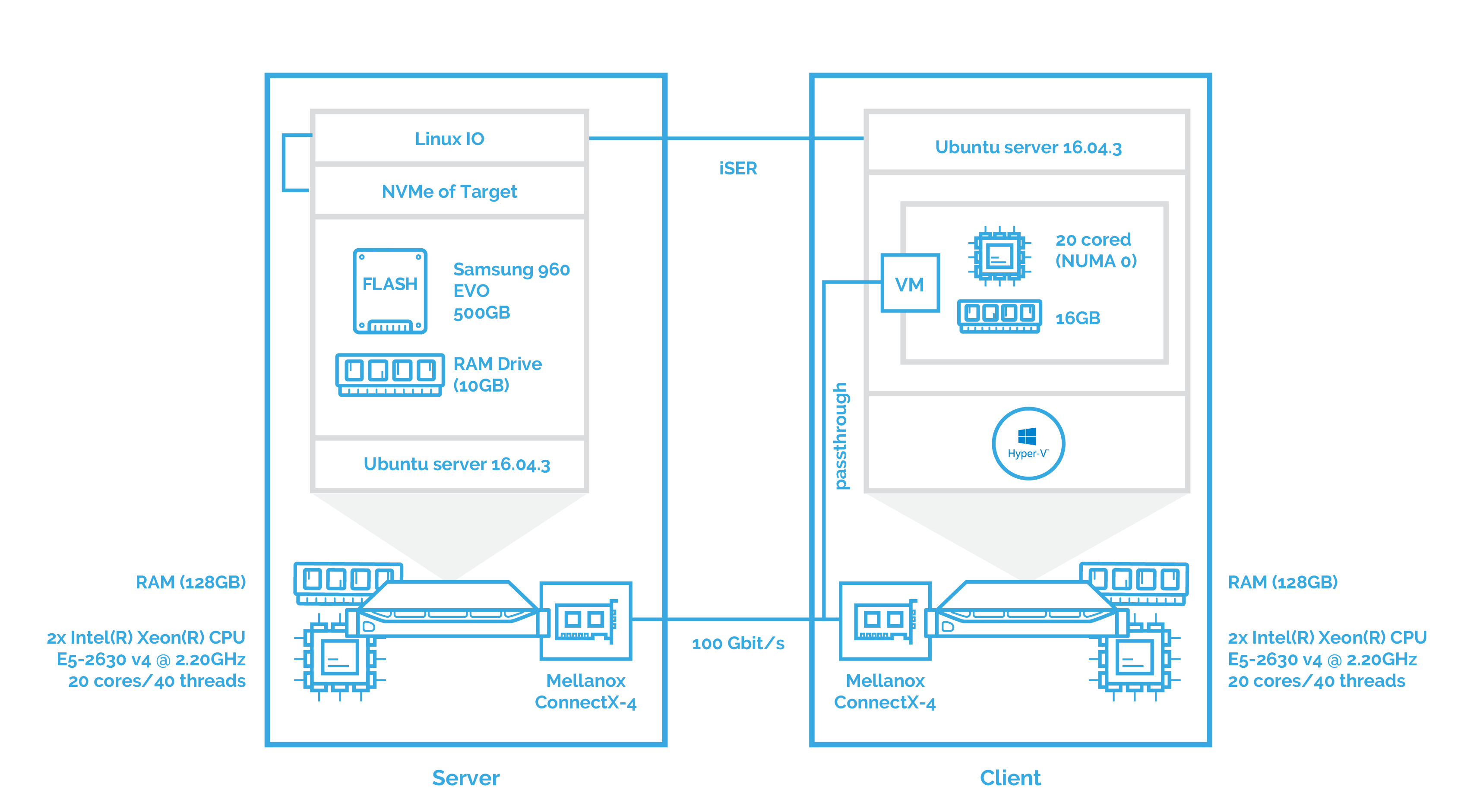
Since SPDK doesn’t allow the use of iSER, I’ve used LinuxIO (LIO) to test iSER as transport. LIO is the Linux SCSI target and supports a large number of fabric modules and all existing Linux block devices as backstores.
We have a long way ahead and just to make it clear, here is the content of the upcoming articles.
- Introduction
- Preparing the environment
- Testing NVMe over Fabrics performance on a bare metal architecture
- Testing NVMe over Fabrics performance with Microsoft Hyper-V deployed on a client
- Testing NVMe over Fabrics performance with VMware ESXi deployed on a client
- Conclusions
OK, let’s take a look at our hardware configuration. I’ll be using 2 Supermicro servers connected directly with the following specs:
| Server | Supermicro X10DRH |
| CPU | 2x Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz |
| Sockets | 2 |
| Cores/Threads | 20/40 |
| RAM | 128Gb |
| NIC | Mellanox ConnectX-4 (100Gbit\s) |
| OS | Ubuntu server 16.04.3 HWE (Linux kernel 4.10.0-38-generic) |
| Storage | RAM Drive 10G;
Samsung SSD 960 EVO NVMe M.2 500GB. |
As you can see, I’ll use Samsung SSD 960 EVO NVMe M.2 500GB and RAM Drive 10G to measure NVMe over Fabrics performance.
Here you can see the software components for our benchmarks:
| SPDK | v17.10 | |
| DPDK | v17.08 | |
| fio | v2.2.10 | |
| Protocol | Target | Client |
| RDMA | NVMe-oF Target | nvme-cli |
| iSER | LIO | open-iscsi |
| iSCSI | SPDK iSCSI Target | open-iscsi |
Scenario 1
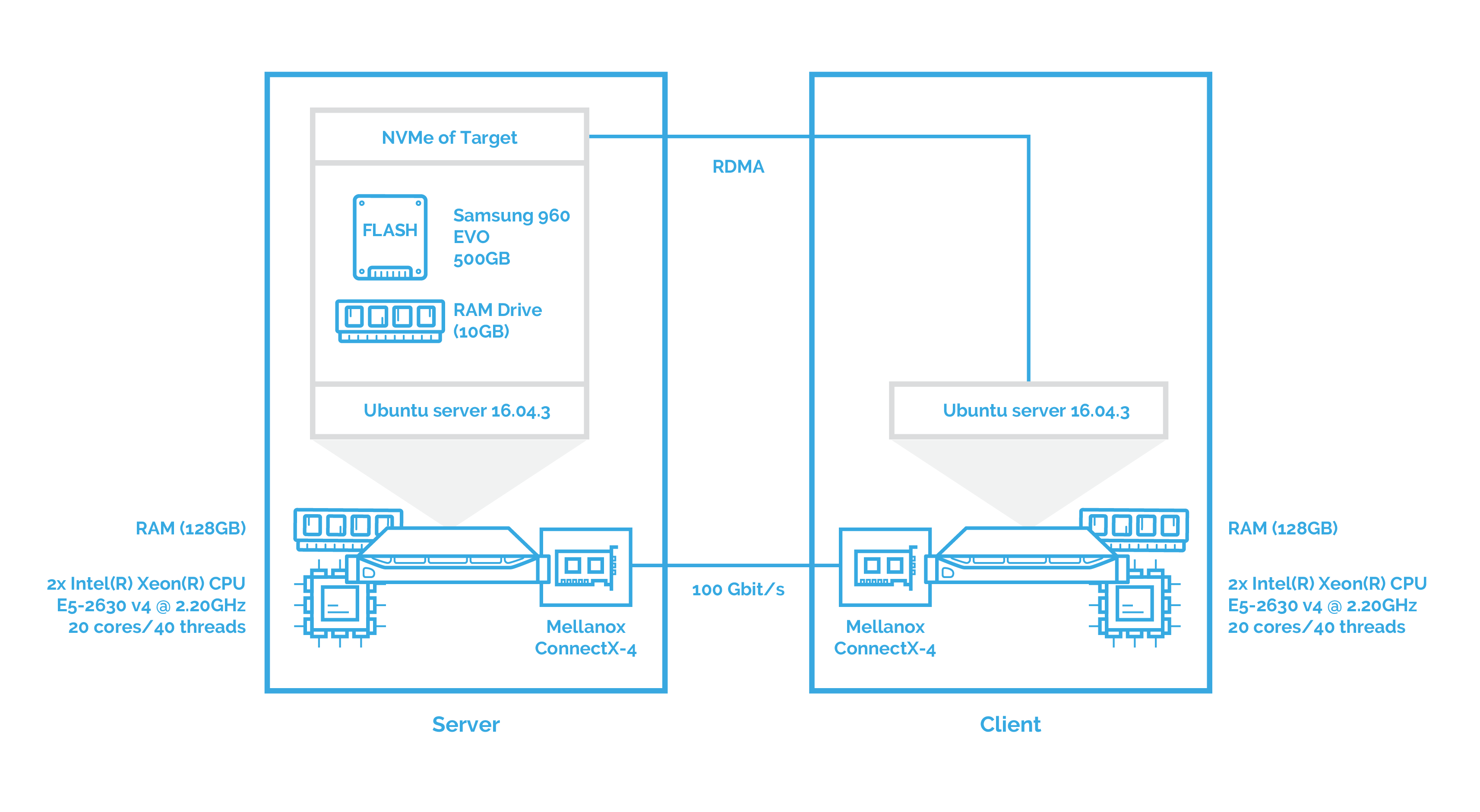
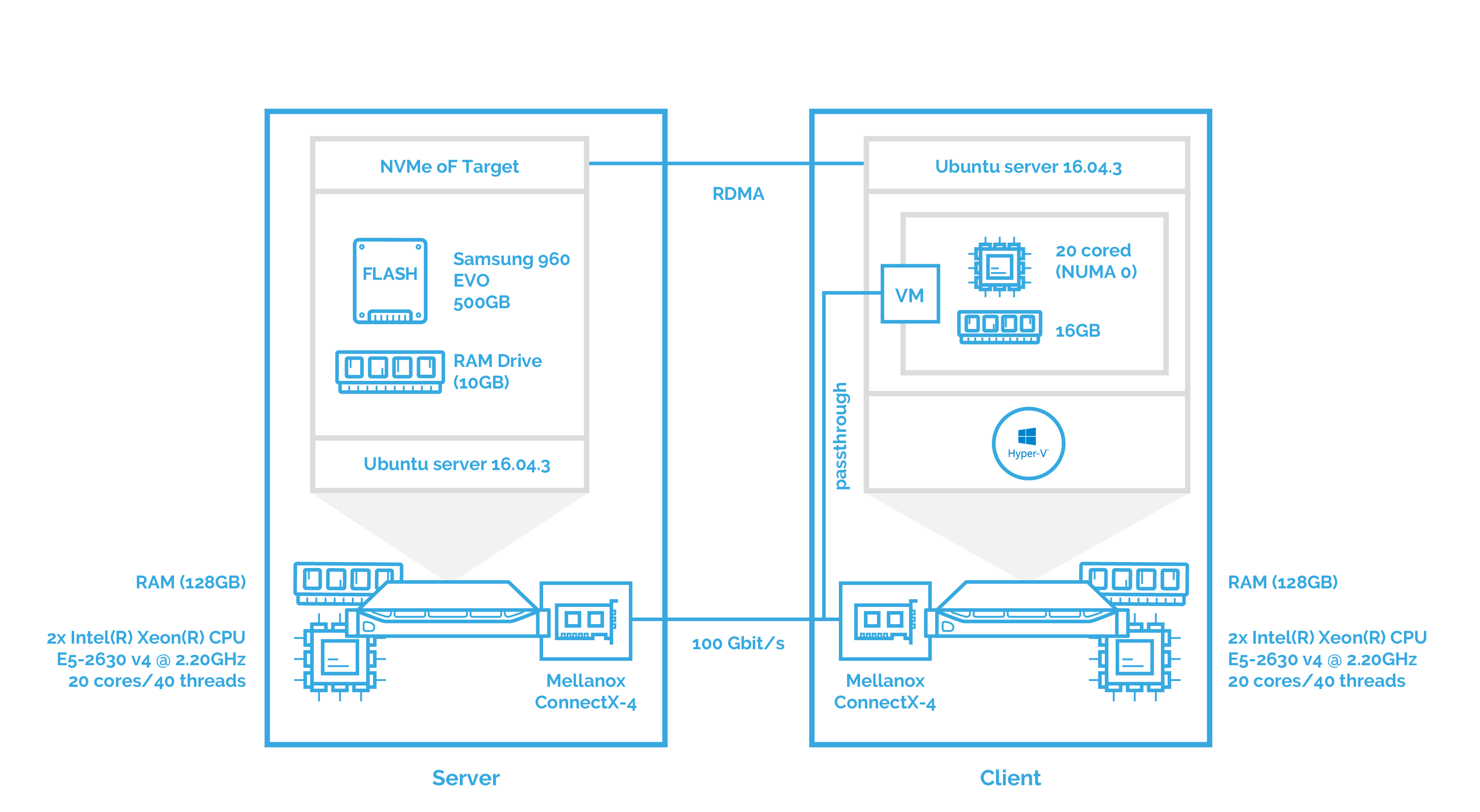
As mentioned above, in this part, I’ll evaluate the performance of NVMe over Fabrics on the client server with no virtualization software installed. This gives us “pure” results which will be further compared with the outcomes in other scenarios.
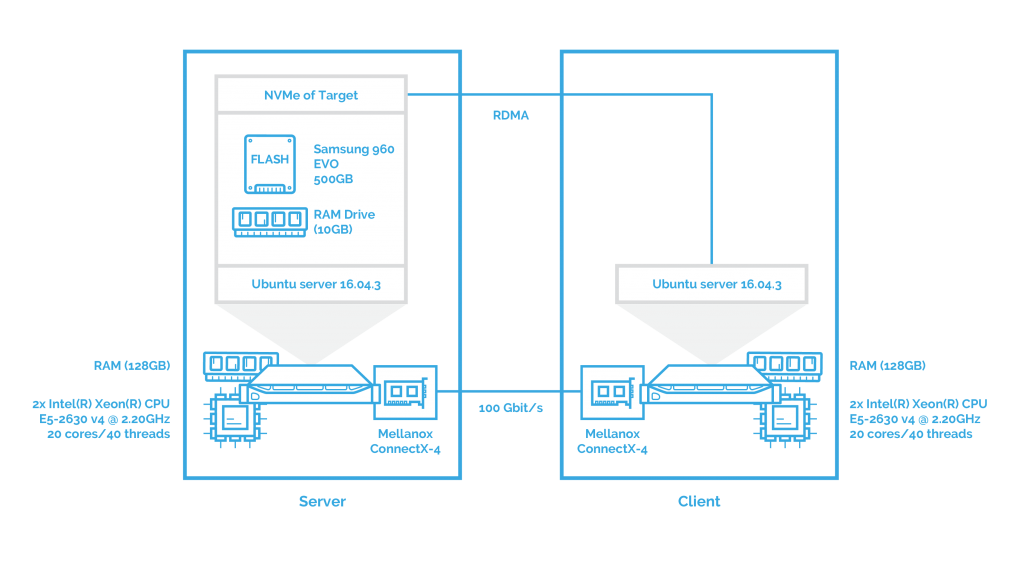
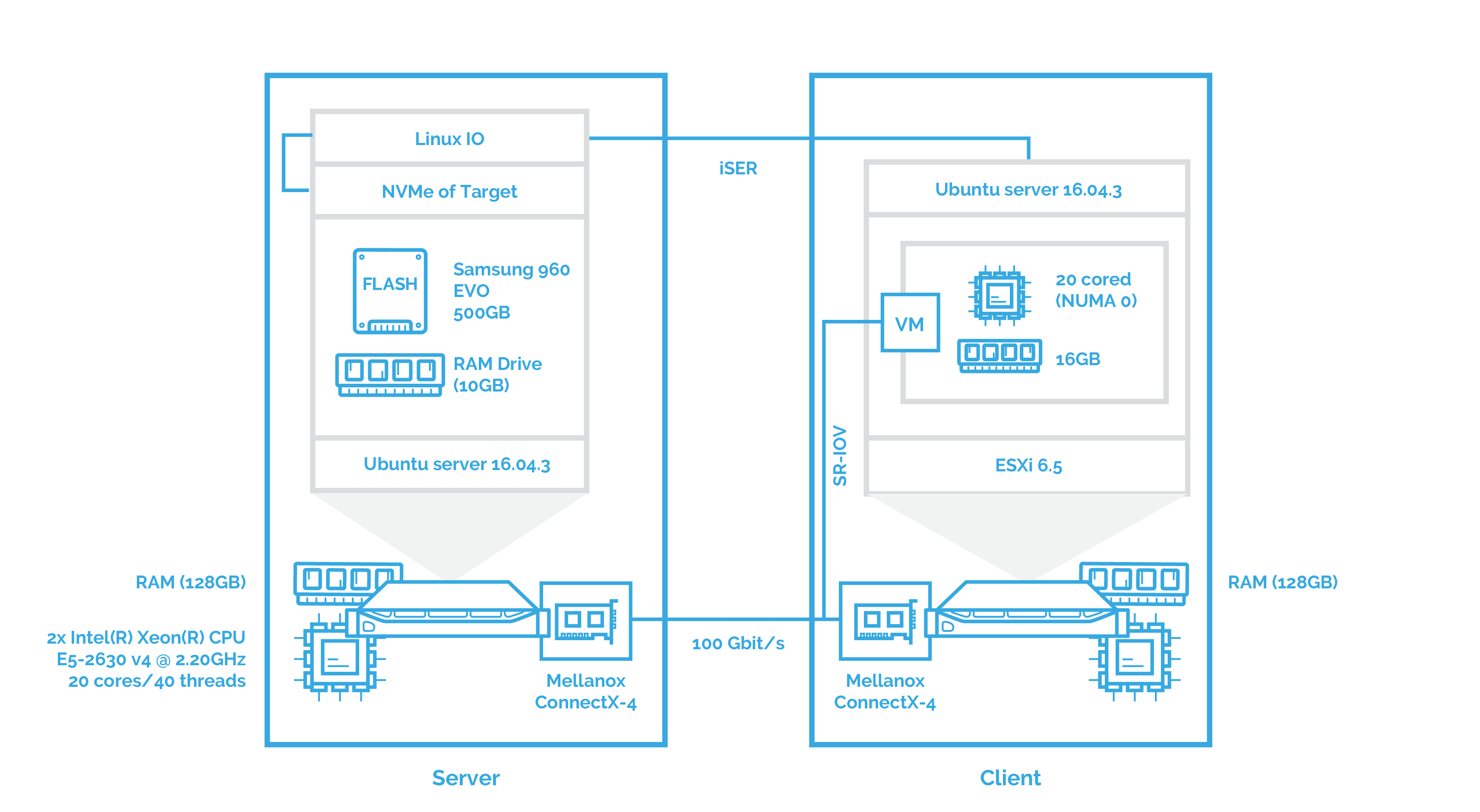
After this, I’ll measure the performance of NVMe over Fabrics when using iSER as transport. You can see the configuration below:
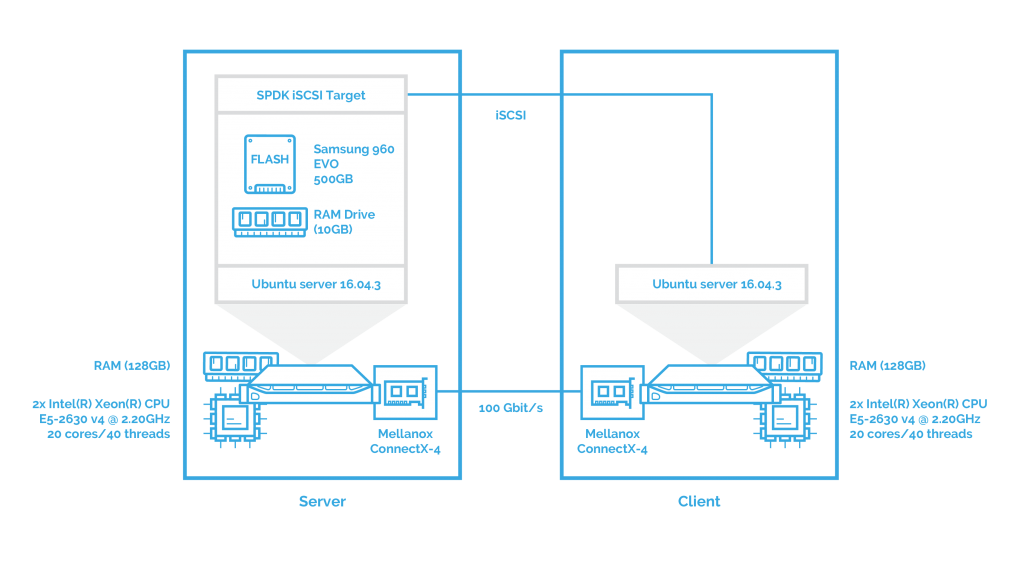
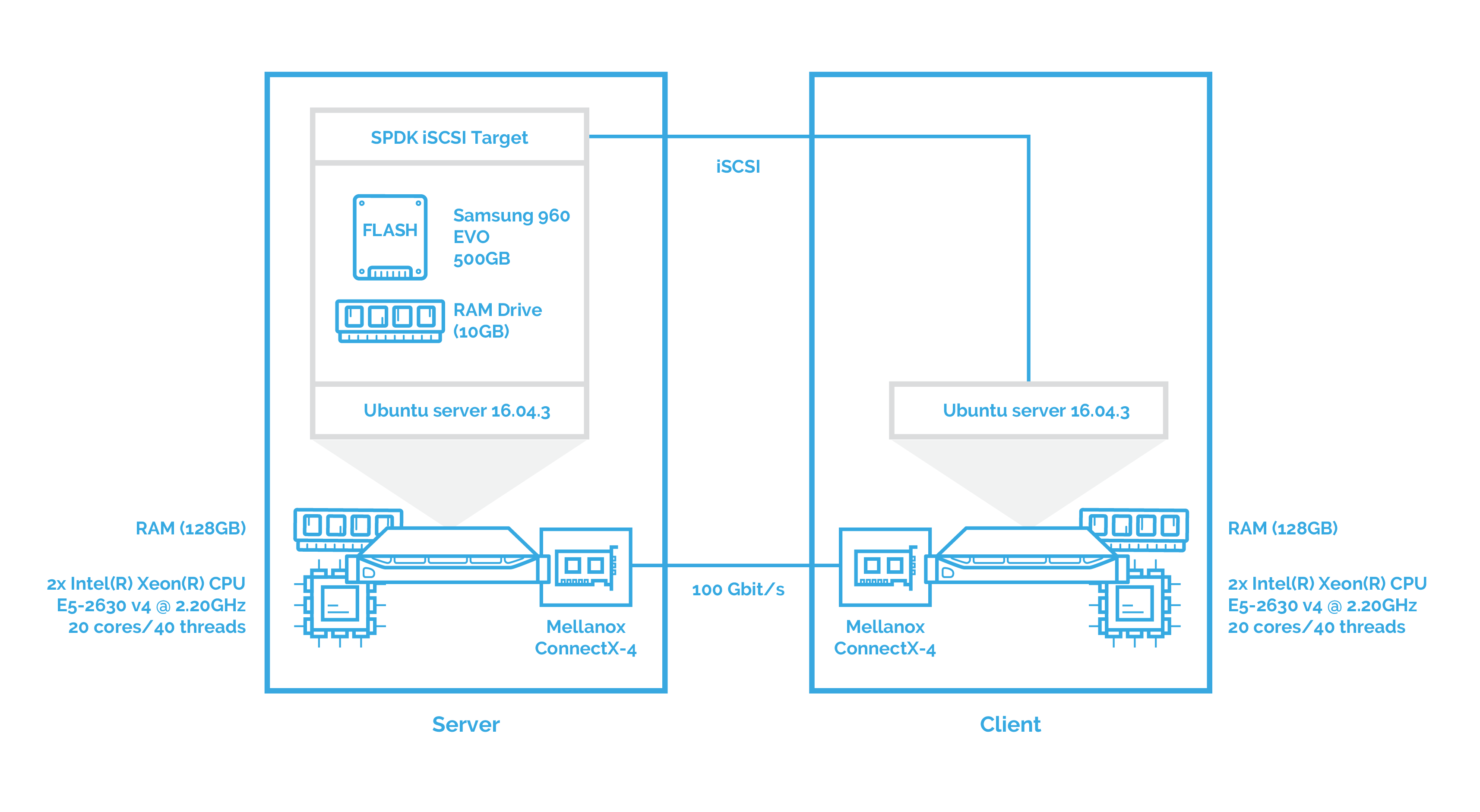
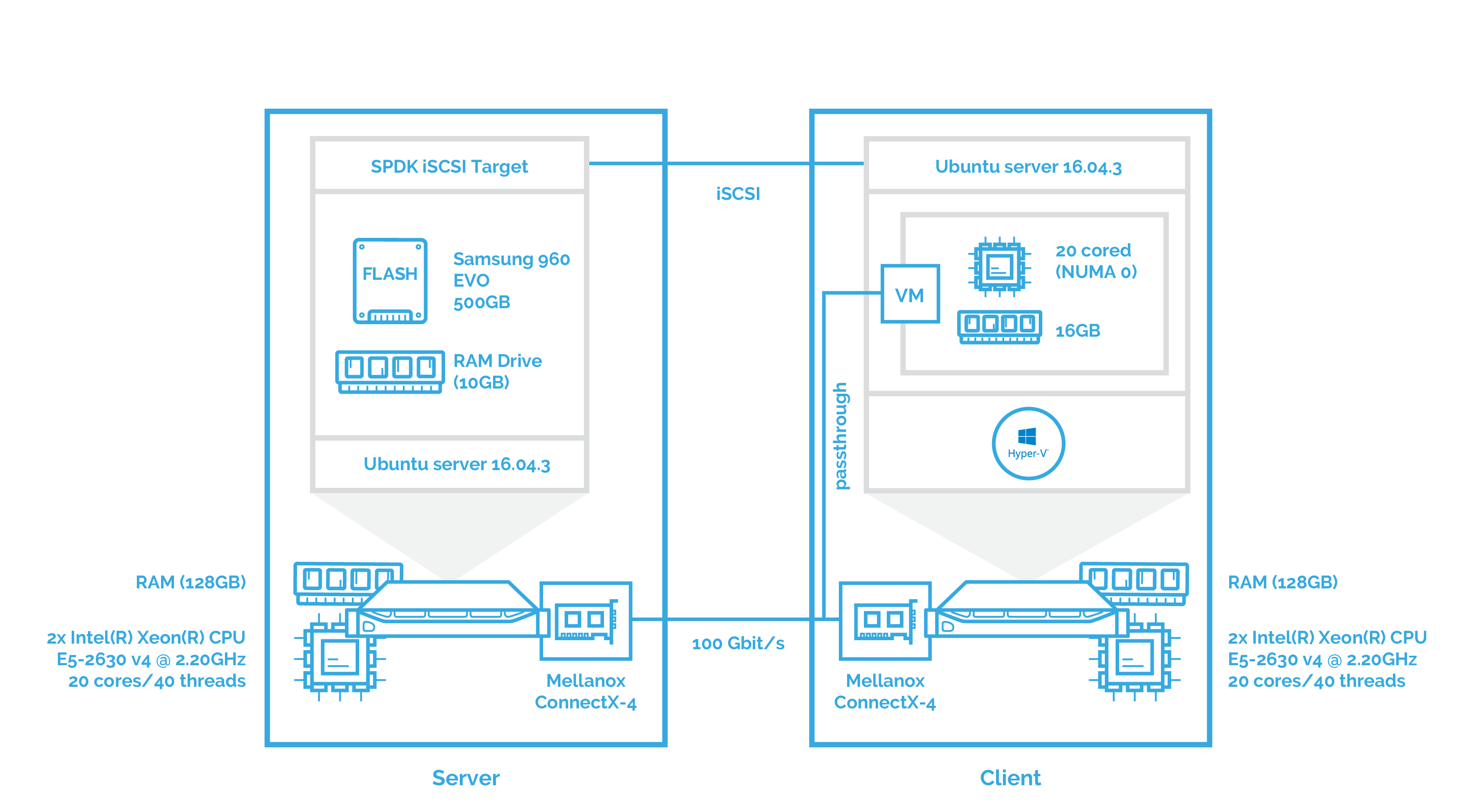
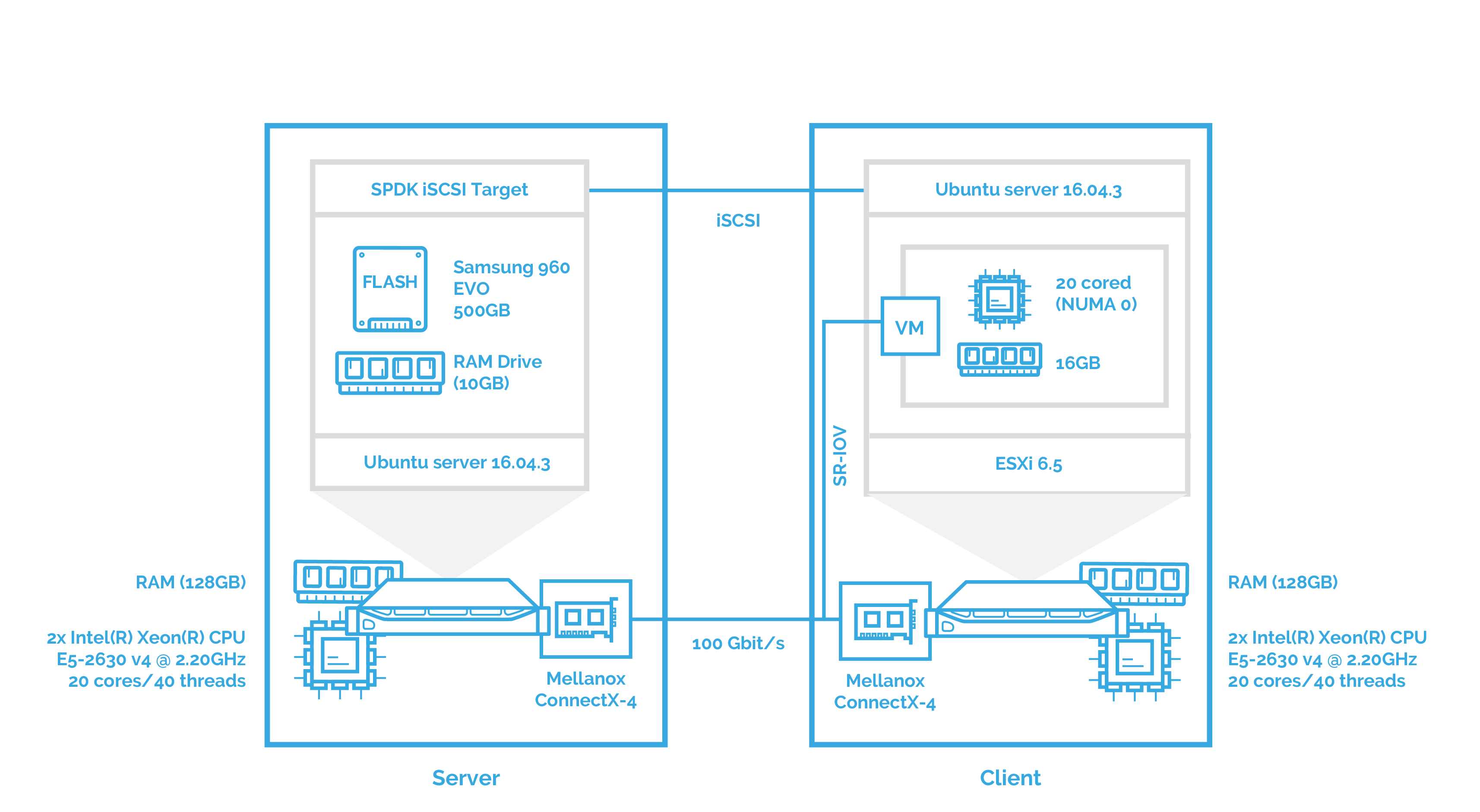
To get the full picture, I’ll also check the performance of SPDK iSCSI. Here is the scheme:
Scenario 2
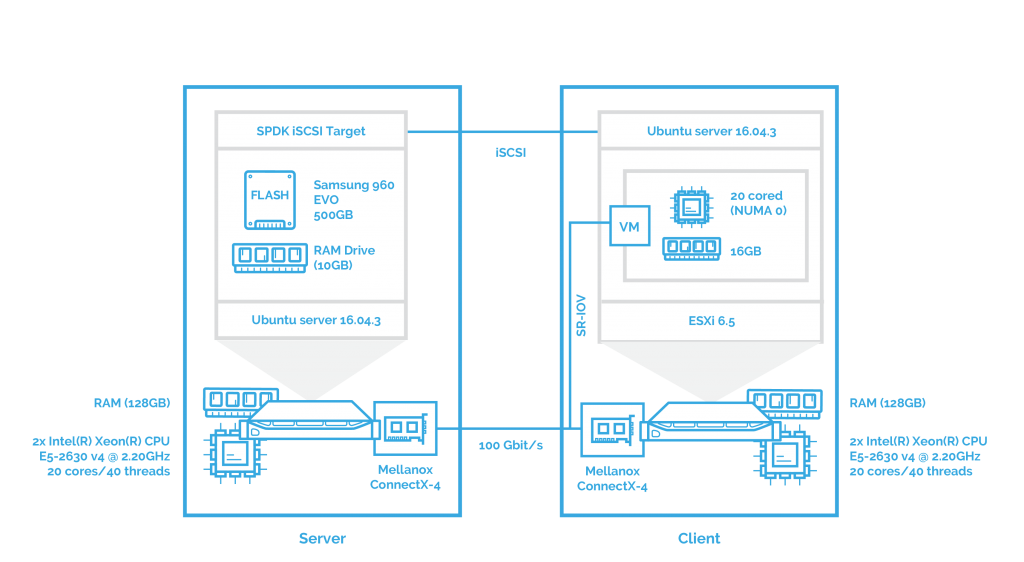
Now, the main goal of the next two benchmarks is to see how NVMe over Fabrics handles data transfers in virtualized environments. In this part, I’ll evaluate the performance of NVMe-oF with Hyper-V deployed and a VM with 20 cores and 16 GB that takes the role of the client. Mellanox ConnectX-4 network interface card is attached to the VM using PCI passthrough. I’ve planned to use SR-IOV but there are certain issues with Hyper-V. I’ll tell you more about that in the corresponding article. The configuration looks like this:
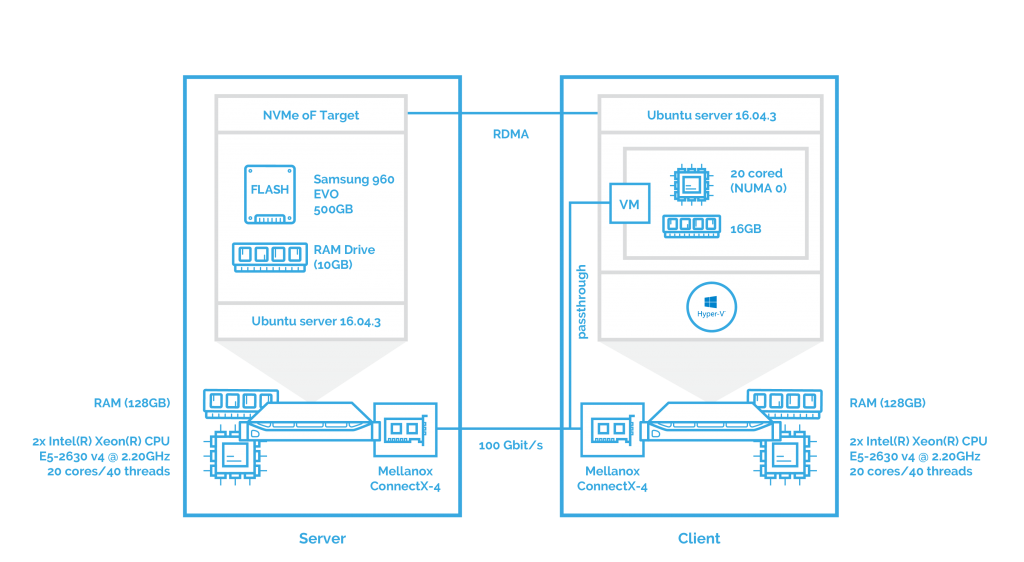
The next step is to measure how NVMe over Fabrics performs when iSER transport is used. All other settings remain the same.
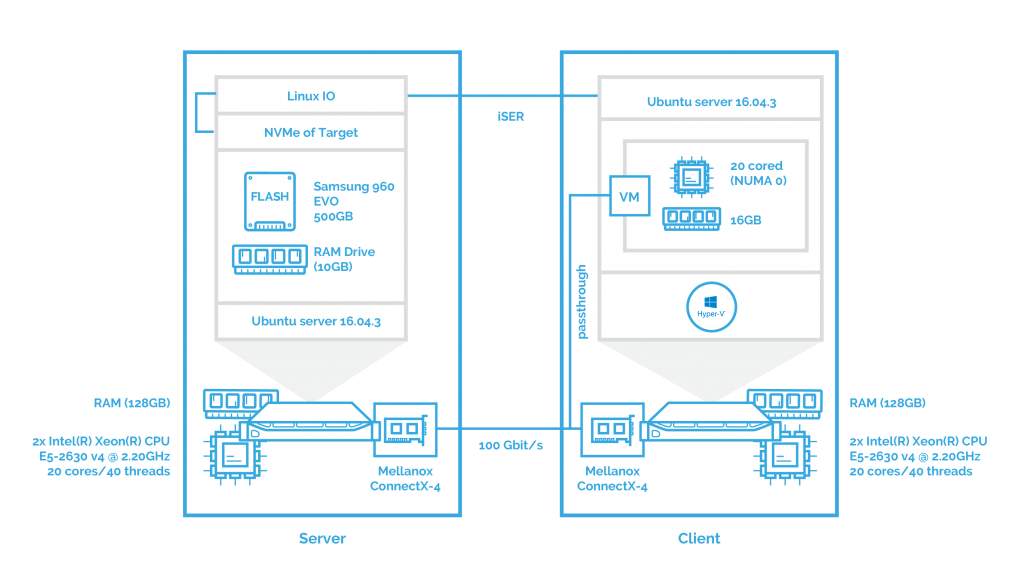
As you probably guessed, afterward, I’ll assess the performance of SPDK iSCSI when Hyper-V is deployed on a host.
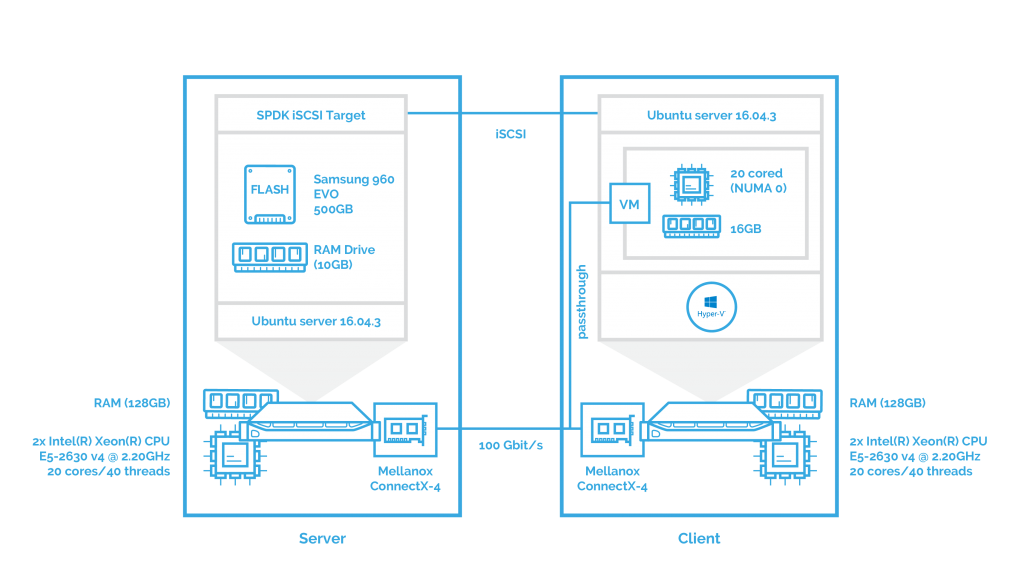
Scenario 3
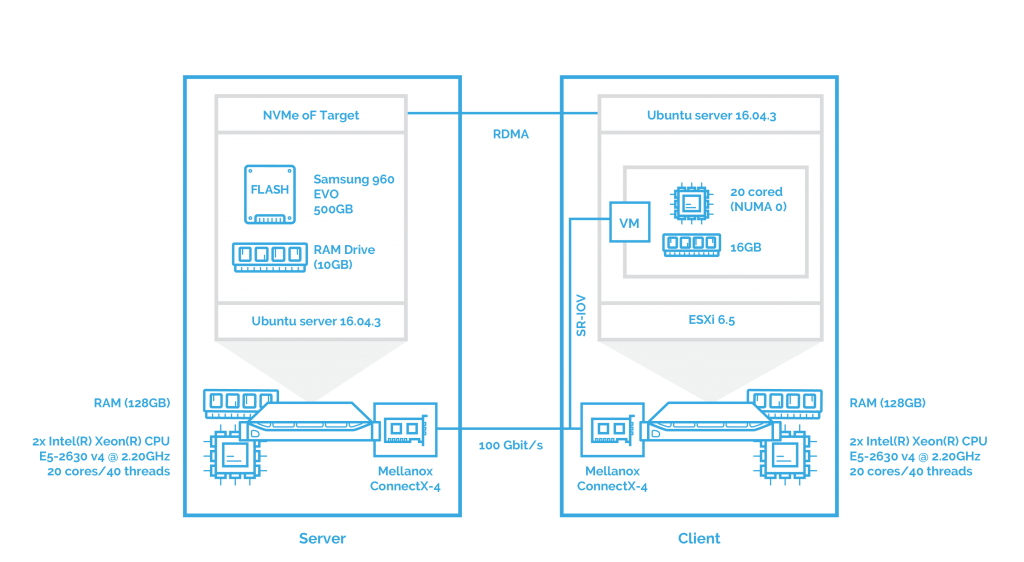
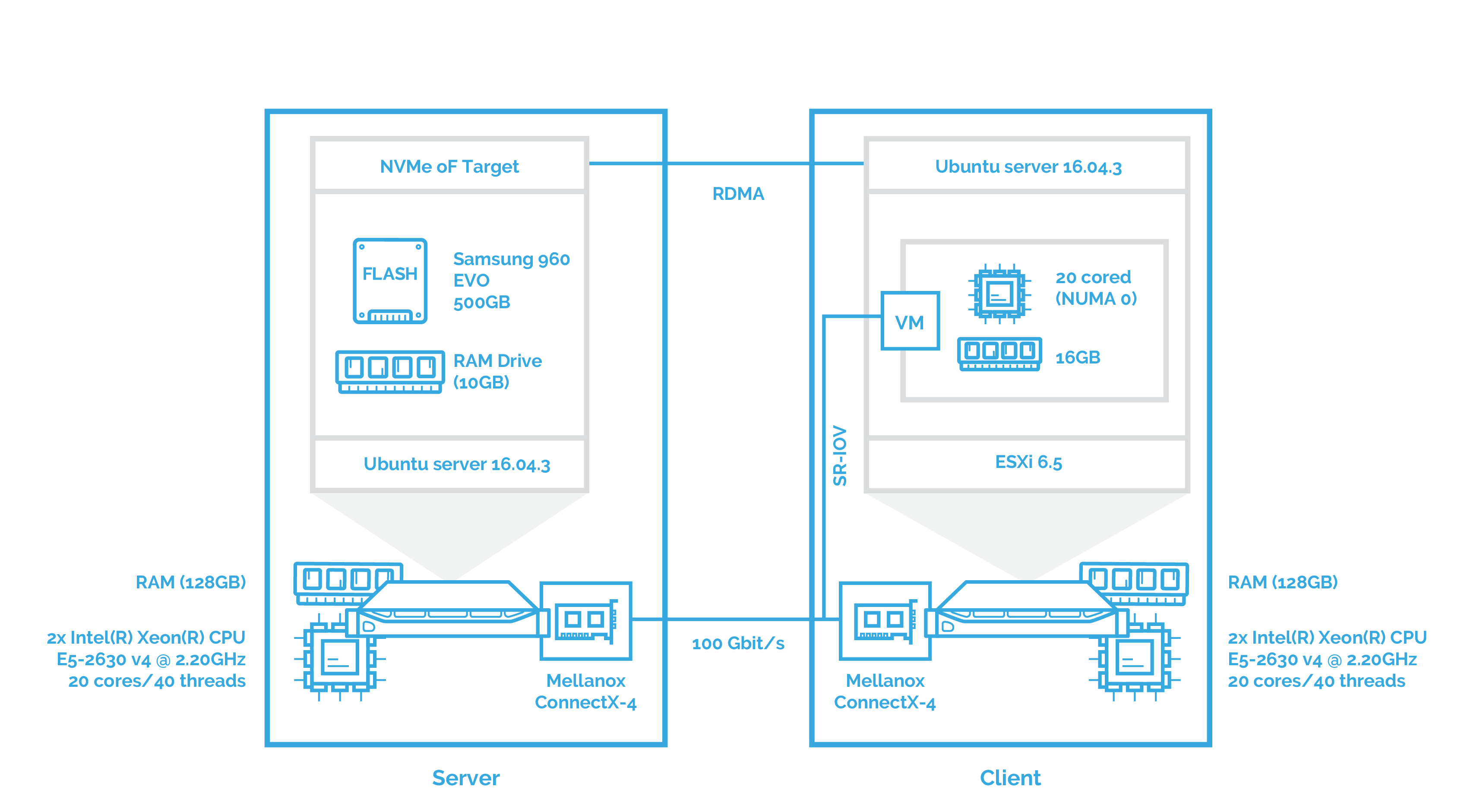
This chapter is pretty much the same as the second one. The difference here is that I’ll use VMware ESXi as a hypervisor and that the network controller is attached to the VM using SR-IOV. First, examining the NVMe over Fabrics performance.
As in the previous case, I’ll test the performance of NVMe-oF with iSER transport when ESXi is deployed.
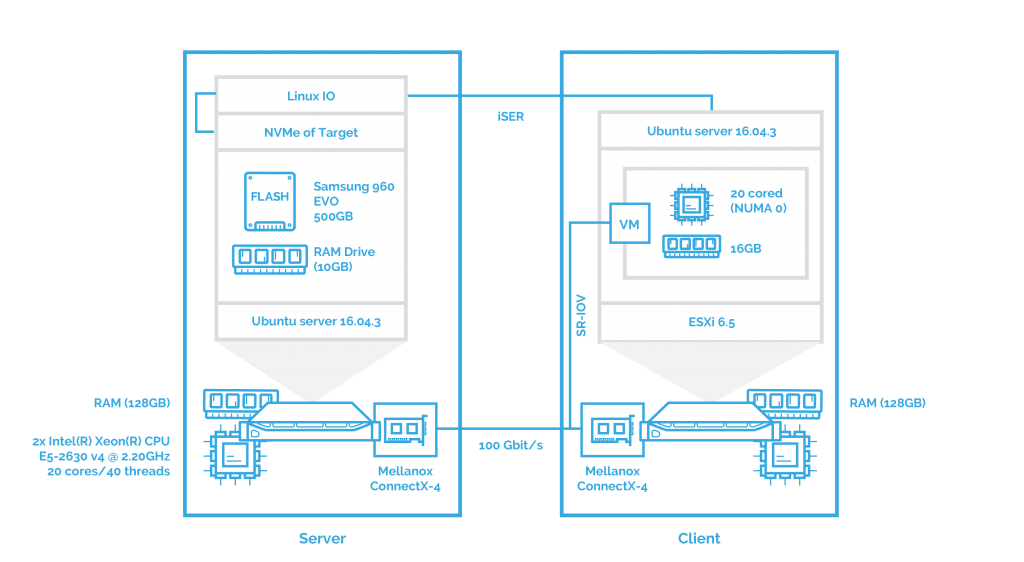
And finally, assessing the SPDK iSCSI performance with ESXi:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Now, when you got the idea, let me tell a few words about the tools to be used for benchmarking and metrics to be measured.
So, to evaluate the NVMe over Fabrics performance in all three scenarios, I’ll use the FIO tool.
I have first tested the devices locally to determine optimal performance and latency parameters. Based on the outcomes, I’ve set the following parameters for further examination:
RAM Drive 10G – numjobs=8 iodepth=64
Samsung SSD 960 EVO NVMe M.2 500GB – iodepth=32, numjobs=16
Here is the example of the FIO configuration file for RAM Drive:
[randomread4k]
buffered=0
ioengine=libaio
rw=randread
bs=4k
iodepth=64
numjobs=8
direct=1
runtime=120
time_based=1
filename=/dev/nvme0n1
group_reporting=1The example of the FIO configuration file for NVMe Drive:
[randomread4k]
buffered=0
ioengine=libaio
rw=randread
bs=4k
iodepth=32
numjobs=16
direct=1
runtime=300
time_based=1
filename=/dev/nvme1n1
group_reporting=1As to the metrics, I’ll assess the following parameters: IOPS, MBps, Latency, and CPU usage for Random and Sequential 4K and 64K Reads, and Random and Sequential 4K and 64K Writes.
I will be using 1,2 and 4 connections on RAM Drive and 1 and 2 connections on NVMe accordingly since these settings give the best outcomes on my particular hardware. Generally, the more connections there are, the lower performance will be.
Conclusion
The main goal of these benchmarks is to see how virtualization influences (if it does at all) the NVMe over Fabrics performance. For that matter, I’ll evaluate how it performs on the bare metal configuration. It will be a “standard” to which the performance of NVMe-oF with Hyper-V and ESXi will be compared. In the next article, I’ll prepare the server and the client, install SPDK and LIO, prepare the VM in Hyper-V and ESXi and configure NVMe-oF. Basically, I’ll cover all the steps needed to prepare our testing environment, so stay tuned!