

Here is a part of a series about Microsoft Resilient File System, first introduced in Windows Server 2012. It shows an experiment, conducted by StarWind engineers, dedicated to seeing the ReFS in action. This part is mostly about the FileIntegrity feature in the file system, its theoretical application and practical performance under real virtualization workload. The feature is responsible for data protection in ReFS, basically the reason for “resilient” in its name. It’s goal is avoidance of the common errors that typically lead to data loss. Theoretically, ReFS can detect and correct any data corruption without disturbing the user or disrupting production process.
Here is a part of a series about Microsoft Resilient File System, first introduced in Windows Server 2012. It shows an experiment, conducted by StarWind engineers, dedicated to seeing the ReFS in action. This part is mostly about the FileIntegrity feature in the file system, its theoretical application and practical performance under real virtualization workload. The feature is responsible for data protection in ReFS, basically the reason for “resilient” in its name. It’s goal is avoidance of the common errors that typically lead to data loss. Theoretically, ReFS can detect and correct any data corruption without disturbing the user or disrupting production process.
Introduction
The FileIntegrity option is what stands behind the data protection feature of ReFS, being responsible for scanning and repair processes. This test is aimed at checking if the option is effective for random I/O, typical for virtualization workloads. As of Windows Server 2012, ReFS didn’t really cope with virtualization, often crashing on such workloads. Right now we’re about to see if that has changed.
Test
Our goal is to monitor how a ReFS-formatted disk works with FileIntegrity off and then with FileIntegrity on while doing random 4K block writes.
We’ve got two utilities to monitor the tests – DiskMon and ProcMon. DiskMon is a tool that logs and shows all HDD activity on a system. ProcMon is a monitoring application that displays real-time file system, Registry and process/thread activity. You can get them here:
https://technet.microsoft.com/en-us/sysinternals/diskmon.aspx
https://technet.microsoft.com/en-us/sysinternals/processmonitor.aspx
In order to create the workload, we’re going to use IOmeter, an I/O subsystem measurement and characterization tool: http://www.iometer.org/
In the next iteration of this research, we’re going to utilize Diskspd (https://gallery.technet.microsoft.com/DiskSpd-a-robust-storage-6cd2f223) utility, but right now the above mentioned tools are enough.
The method of the test:
- To begin with, we’ll format the disk into ReFS and turn the FileIntegrity option off (which it is by default). Then we start DiskMon (configuring it to monitor the target HDD) and ProcMon (filtering Iometer test file). Having done that, we are ready to start the IOmeter with random 4K access pattern and collect the utility logs.
- Format the disk into ReFS and turn the FileIntegrity option on. Then we start DiskMon (configuring it to monitor the target HDD) and ProcMon (filtering Iometer test file). Having done that, we are ready to start the IOmeter with random 4K access pattern and collect the utility logs.
- At the end, we export the logs into MS Excel and compare the HDD work in both scenarios.
Hardware setup specs:
Intel Xeon X3460 @ 2.8GHz
RAM 8GB
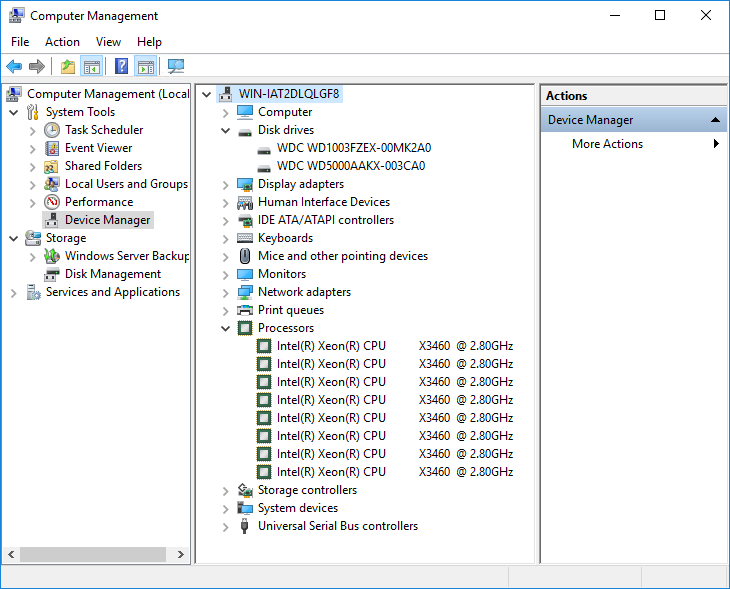
Boot: SATA WD5000AAKX – 500 GB
Test disk: (D:\): SATA WD1003FZEX – 1TB
Software setup:
Microsoft Windows Server 2016 Technical Preview 4
DiskMon and ProcMon
Iometer settings:
4 Workers
Maximum Disk Size – 1048576000 (500 GB)
# of Outstanding I/Os – 16
4K random write
Testing time: 1 hour
Performing the test on the disk with FileIntegrity off
Formatting the disk into ReFS.
Checking FileIntegrity option status. It is off.
Get-FileIntegrity D:\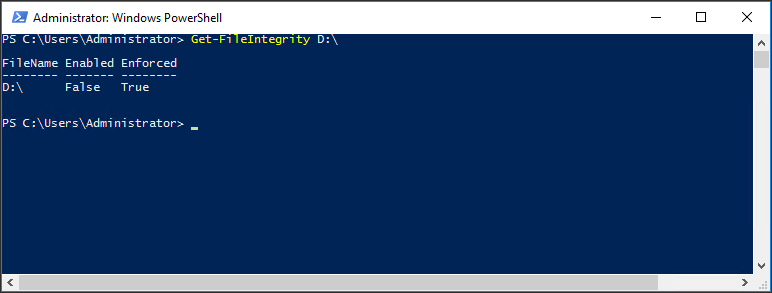
In the Iometer test file the option is also off.
Get-FileIntegrity D:\iobw.tst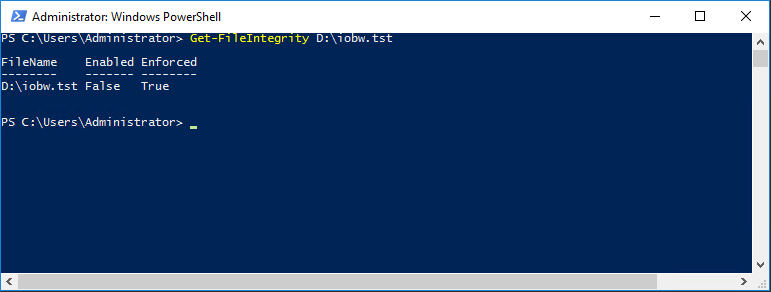
Starting DiskMon
Starting ProcMon, adding the Iometer test file filter on the ReFS disk.
Next, we turn on Iometer and initiate the workload
Now let’s save the logs of DiskMon and ProcMon.
Performing the test on the disk with FileIntegrity on
Formatting the disk into ReFS.

Turning FileIntegrity on. Checking if it’s on.
Set-FileInetgrity D:\ -Enable $True
Get-FileIntegrity D:\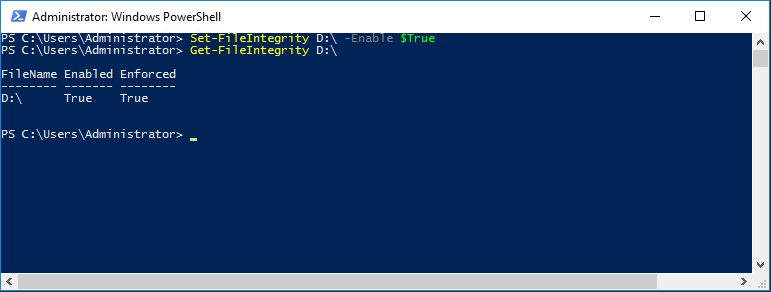
In the Iometer test file the option is also off.
Get-FileIntegrity D:\iobw.tst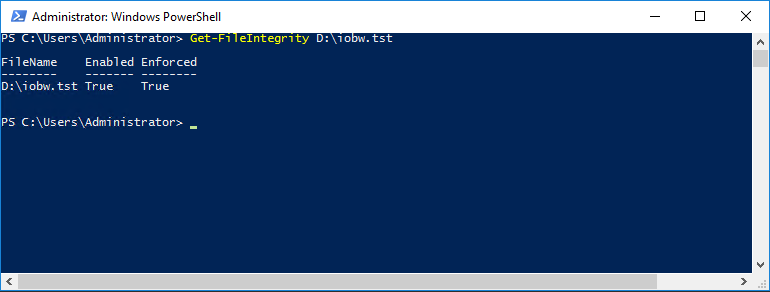
Starting DiskMon
Starting ProcMon, adding the Iometer test file filter on the ReFS disk.
Next, we turn on Iometer and initiate the workload
Now let’s save the logs of DiskMon and ProcMon.
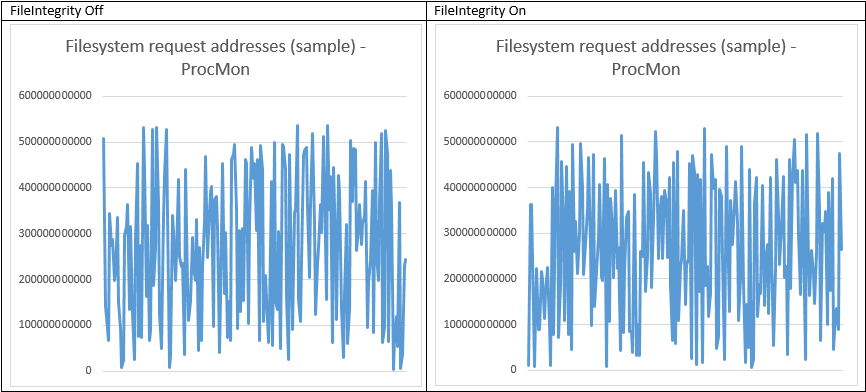
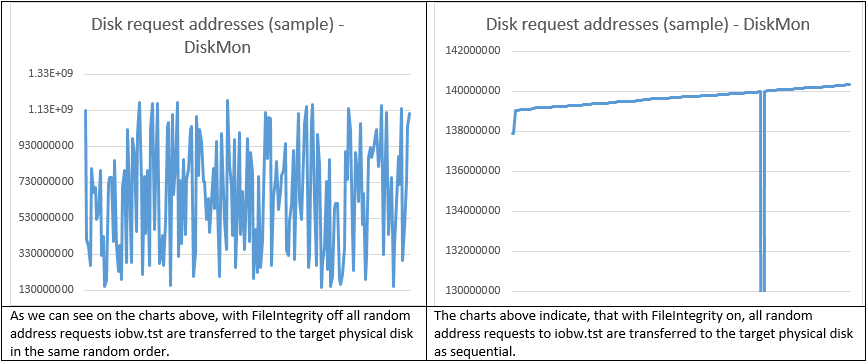
DiskMon and ProcMon Logs Analysis
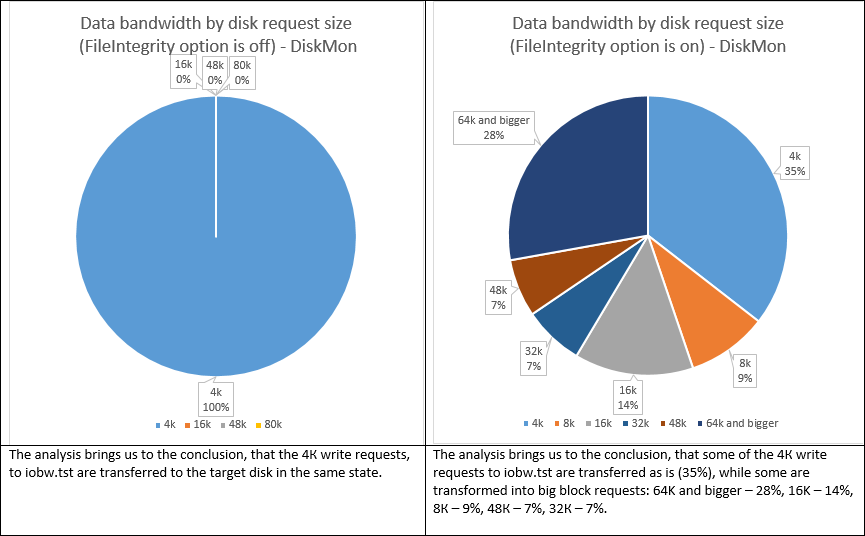
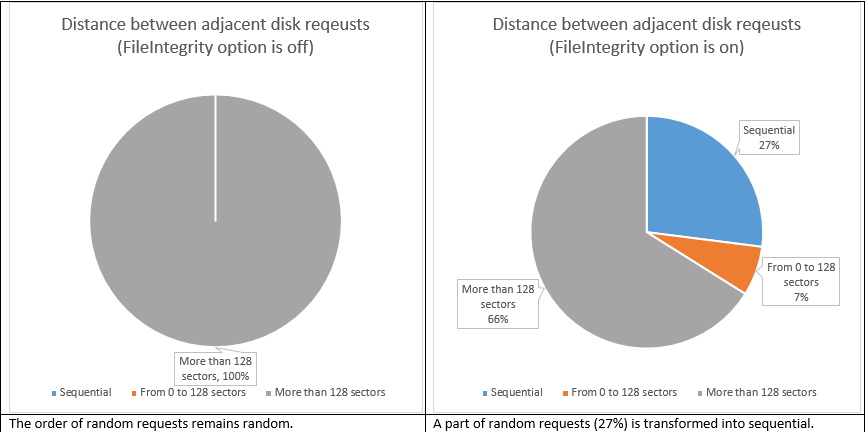
Conclusion
As we can see, ReFS with FileIntegrity off works much like a conventional file system, like its predecessor NTFS (https://en.wikipedia.org/wiki/NTFS) in terms of processing random write requests. All the writes were transferred as is, without any changes in LBA request size. This mode makes ReFS just a regular file system, well-suited for the modern high-capacity disks and huge files, because no chkdsk or scrubber are active.
Once you turn FileIntegrity on, ReFS starts transforming those 4K writes into something else. 27% of them become sequential and 65% also become bigger (64K and bigger – 28%, 16K – 14%, 8К – 9%, 48К – 7%, 32К – 7%). What’s also important is the fact that the random LBA access became sequential. Basically, ReFS works much like Log-Structured File System (https://en.wikipedia.org/wiki/Log-structured_file_system) in this mode. This seems like good news for virtualization workloads, because transforming multiple small random writes into bigger pages improves performance and helps avoid “I/O blender” effect. The latter issue is typical to virtualization. It is an effect of dramatic performance degradation, being the result of multiple virtualized workloads merged into a stream of random I/O. Before LSFS, we used to spend a fortune on SSD in order to battle this problem. Now we have LSFS (WAFL, CASL) and as it appears, ReFS helps too.
However, while the writes become sequential, the reads are scrambled, so in case some application makes a log, then we have a problem typically called “log-on-log” (https://www.usenix.org/system/files/conference/inflow14/inflow14-yang.pdf). It means that several logs are stacked on each other when some application has a log of its own, which also gets processed by Log-Structuring. This is common with SQL Server, Exchange, Oracle, etc. While the application “thinks” it writes a sequential page, its log is scrambled by ReFS FileIntegrity option, which is basically trying to log the log again. The problem is – none of the logs “know” about the other one, so both are using resources for the same meaningless work.
Besides, there are performance issues that we’re going to cover in the next test. It’s a common misconception that performance degradation in ReFS is associated with hashsumming, but we have all the reasons to doubt it. Stay tuned for the next part of our research and see what happens.
