

Why you should learn about SMB Direct, RDMA & lossless Ethernet for both networking & storage solutions

Server, Hypervisor, Storage
Too many people still perceive Windows Server as “just” an operating system (OS). It’s so much more. It’s an OS, a hypervisor, a storage platform with a highly capable networking stack. Both virtualization and cloud computing are driving the convergence of all the above these roles forward fast, with intent and purpose. We’ll position the technologies & designs that convergence requires and look at the implications of these for a better overall understanding of this trend.
Some people would state that this discussion is already over and done with but in reality, a lot of environments are not converged yet, let alone “hyper converged” even when for some this would make the most sense.
A modern OS
Today Windows is indeed a versatile modern OS with native converged network capabilities for management, cluster, data, voice, backup traffic and the like. The Quality of Service capabilities have been extended and improved significantly. New versions, like Windows Server 2016, keep evolving and enhancing this OS for both on-premises and cloud deployments.
A Hypervisor
Windows provides a very capable, scalable and secure hypervisor that allows for convergence in the virtualization stack by leveraging the virtual switch (vSwitch) and the virtual NICs (vNICs) for the virtual machines and the hosts. Switch Embedded Teaming (SET) and the network controller in Windows Server 216 are the next evolutionary steps in this area.
Storage
Windows Server is also software-defined storage system (Storage Spaces, SOFS, SMB 3). Part of this stack is the support for SMB Direct and its ability to leverage Data Center Bridging (DCB). This enables Windows to deliver traditionally converged and hyper-converged storage solutions to any workload.
SMB Direct & Convergence
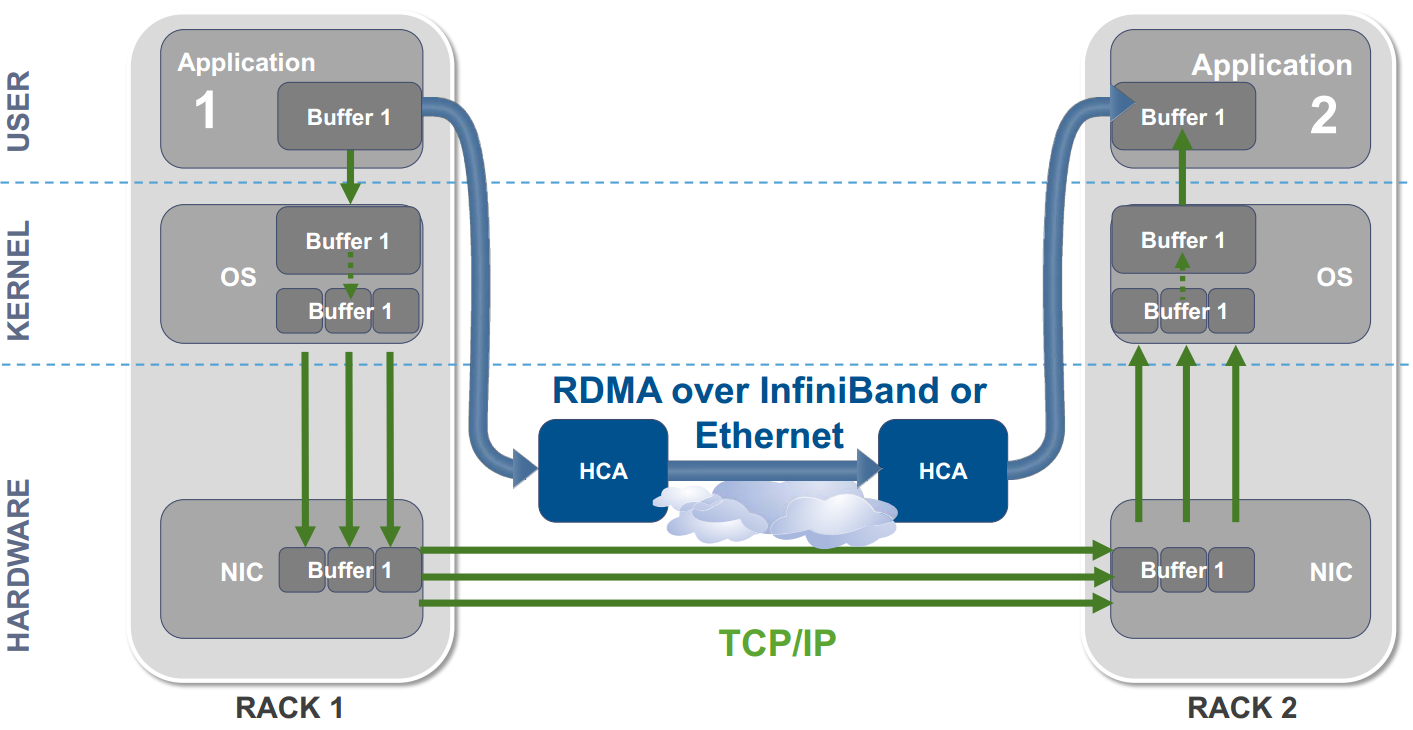
Early in 2015, Jeffrey Snover stated that organizations should buy the right stuff amongst which are network interface cards (NICs) that support RDMA. These enable the use SMB Direct. Since Windows Server 2012 introduced SMB 3, the uses cases for SMB Direct have only grown: Files sharing, Clustered Shared Volumes, live migration, storage live migration, “shared nothing” live migration, storage replication, Storage Spaces Direct. This is with good reason. The power of SMB Direct lies in the leveraging of Remote Direct Memory Access and the efficiencies this delivers.
A RDMA protocol allows for high throughput at very low latency while offloading the heavy lifting from CPU and bypassing the memory path of the TCP/IP memory stack on the hosts. This means that even at 25,40, 50 or 100Gbps speeds network traffic will not bog down your CPU cores and make you take a performance hit. “Zero-copy” avoids making multiple copies being made throughout the OS and TCP/IP stack. Another benefit is that it also saves on the usage of the CPU cache for application workloads. This also avoids context switches between user mode and kernel mode, which is referred to as “Kernel Bypass”.
The growing capabilities in Windows Server mean that the demands on the network have grown significantly. As a result, solid, modern network designs have never been more important to successful deployments. In order to provide the needed bandwidth and throughput at low latencies, Windows networking keeps evolving to make better use of the 10/25/40/50/100 Gbps capable network stacks that are becoming more prevalent in our data centers. SMB Direct is an important part of the answer to these demands and needs.

Figure: Courtesy of Mellanox ® showcasing zero copy, kernel bypass & CPU offloading
All the above translates into extremely fast application performance at high throughput and low latencies. This allows for optimal use of modern software and hardware capabilities delivered by Flash Only Arrays, NVM Express, DDR4, 10/40/100Gbps networking, …
SMB Direct can leverage 3 of RDMA Infiniband, RoCE, and iWarp.
Here’s a quick overview of the 3 types of RDMA SMB Direct can leverage. I will not go into much details on these here, that would be a white paper by itself.

Figure: courtesy of Microsoft – adapted by Didier Van Hoye
Each of these flavors works well. An important thing to note is that they cannot talk to each other. End to end you need to have the same flavor. All of them are successfully deployed in the wild. The argument can be made for any of them. It all depends. The one other thing you should realize that RDMA requires a lossless network.
Infiniband delivers this. But is not a first choice for converged environments due to it being a separate infrastructure. It is, however, a very cost effective solution when looking at the amount of Gbps/dollar.
That’s where RoCE (RDMA over Converged Ethernet) comes in, which is a simplified way could be looked at as “Infiniband over ethernet”. However, this requires DCB (Priority Flow Control) to achieve lossless networks. RoCE, being Ethernet, cannot deal with packet loss. ETS (Enhanced Transmission Selection) is the specification that delivers QoS in DCB which come in handy when using converged networking.
iWarp leverages offloaded TCP/IP and as such can benefit from its capability to handle lost packets without requiring DCB (PFC). However, the argument can be made that under stress and in a converged scenario iWarp also benefits from implementing lossless Ethernet with PFC and ETS for minimum bandwidth QoS. But, it’s not a hard requirement.
We’ll discuss DCB in more detail below. I don’t take a hard stance stating one is better than the other. You’ll need to find the best solution for your environment and that depends on many factors.
The Importance of Planning and Design
Windows has the ability to handle higher bandwidths, leverage SMB Direct and supports DCB enabling us to achieve lossless Ethernet. This is paramount for storage traffic and it helps the potential benefits converged networking can deliver materialize:
- simplifying network management (OPEX reduction)
- leveraging commodity equipment (CAPEX reduction).
Convergence means also means mixing different network traffic on the same physical port and cabling infrastructure. This increases the need for Quality of Service (QoS) implementations. This translates into greater complexity and a higher risk due to the larger impact of issues in the converged network stack.
SMB Direct for the file, storage and live migration traffic have given us more options and permutations for building converged solutions (Scale-Out File Server with Storage Spaces) than ever before. Now that the storage and compute layer come together completely in Windows Server 2016 we even get to build hyper-converged solutions via Storage Spaces Direct (S2D). Leveraging or even combining the hardware (DCB for PFC and ETS), virtualized and native QoS capabilities in windows this demands serious consideration what to use, where, why and when. All these options and approaches have their own benefits and drawbacks, strengths and weaknesses. Architecture and design are needed to make it work well. Remember we should only make things as complex as needed and then only to a level that we can manage successfully. That bar is being raised as the technologies evolve.
The Evolution of Quality of Service in Windows
When bringing all kinds of traffic together on the same network stack or infrastructure we need ways to make sure they all get what they need to function properly. Just over-provisioning alone will not save the day especially as the ability to use all that bandwidth materializes. The times where our servers could not even fill a 10Gbps NIC are over.

Figure: Didier Van Hoye – 75% of a 10Gbps was all we could get in the W2K8R2 era
Gone are the days where storage could not ever deliver the IOPS & latency to saturate a 10Gbps network are gone. SATA, SAS and PCIe NVMe disks have made that a reality.

Figure: NVME SSDs Courtesy of Intel ®
Quality of Service (QoS) can and will help. Just remember it’s technology, not magic. Windows Server QoS has quite a history. Today, generally speaking, Windows offers 3 ways to do QoS. Let’s have a quick look at those.
Policy-Based QoS
There is what I will call native QoS, which is the oldest and is policy based which allows GPOs to be leveraged to manage them. The OS Packet Scheduler applies the QoS rules to the network traffic passing through the Windows network stack. While it works and can be quite specific it can be tedious. Usually, it’s only done when absolutely required (VoIP, video, backups …). It works both on physical hosts and inside virtual machines and it most certainly still has its place for certain use cases or when no other options are available or cannot deliver the capabilities needed. In the real world, I don’t see this deployed very often.
Hyper-V QoS or Virtual Switch QoS
Before Windows Server 2012 Hyper-V was missing QoS capabilities. In heavily virtualized environments this was an operational and functional pain point. That was addressed with the introduction of Hyper-V or Virtual Switch QoS.
Also introduced in Windows Server 2012 is the capability to do minimum bandwidth instead of just bandwidth limiting. The ability to easily differentiate between the various network types was a second welcome enhancement.
Figure: fully converged Hyper-V QoS Courtesy of Microsoft
The figure above shows a fully converged Hyper-V QoS with minimal bandwidth configuration in combination with optional classification and tagging for priorities in the VMs and Management OS. In real life, it’s either used as a one of the time a bandwidth hungry VM or to provide a consistent bandwidth experience in VDI deployments.
Data Center Bridging QoS
Another new capability was the introduction of Data Center Bridging (DCB) support in Windows. DCB is paramount to the success of converged networking and storage today and in the future. It’s the way the Ethernet world is addressing the need for storage traffic to be lossless and deals with QoS challenges. This is hardware based and requires support end to end throughout the entire stack.
Below is an example of a favorite setup of mine for high-performance environments

It allows to benefits from RDMA for the Management OS traffic while leveraging Hyper-V QoS and optionally classification and tagging inside the VM. This setup also allows for DMVQ and vRSS. All bases are covered and it offers full redundancy combined with performance.
With great power comes great responsibility
On the same hosts, you can leverage multiple QoS types on multiple network stacks. You cannot mix just any combination of them than on a single end to end network stack.
For example, you can leverage Hyper-V QoS on the vSwitch and vNICs and DCB (PFC/ETS) on your RDMA NICs for SMB Direct traffic (as on the figure). Please note that Windows Server 2016 is pushing the envelope further to make more convergence possible with RDMA exposed to the Hyper-V host even on a teamed vSwitch when leveraging Switch Embedded Teaming. l expect them to continue to improve the capabilities beyond Windows Server 2016.
You can also use native QoS and DCB on two separate network stacks on the same host but you can use both of them on the same network stack on the same host.

The reason for this is that don’t understand each other and it will end badly.
I’m not trying to scare you away from convergence or QoS. But in order or deploy in successfully you have to understand what it is, what it can do and what not. Convergence is a means to an end, not an end goal. It’s not magic. Underprovisioned networks cannot be saved by QoS nor can it solve the issues that bad architectures or design choices expose. In regards to this, it’s important to note that the above-converged networking examples also included storage traffic. This type of traffic requires high throughput, low latency, and zero loss fabrics. As far a storage goes, these requirements are non-negotiable and have to be met. Convergence also introduces some operational challenges that need to be addressed.
Data Center Bridging
Since we mentioned losslessly we need to talk Data Center Bridging (DCB). Yes, lossless is extremely important when it comes to storage. It’s both the nature of the protocols but also a hard functional requirement. Dropping storage traffic tends to ruin each and every IT party.
What is it?
DCB is a suite standard defined by the Institute of Electrical and Electronics Engineers (IEEE). The goal is to enable converged fabrics in the data center. In other words, it’s what allows storage, data networking, cluster IPC and management traffic to share the same Ethernet network infrastructure. The 4 standards are:
Priority-based Flow Control (PFC): IEEE 802.1Qbb provides a link level flow control mechanism that can be controlled independently for each frame priority. The goal of this mechanism is to ensure zero loss under congestion in DCB networks.

Figure: Priority Flow Control Courtesy of DELL
Enhanced Transmission Selection (ETS): IEEE 802.1Qaz provides a common management framework for assignment of bandwidth to frame priorities.

Figure: Enhanced Transmission Selection Courtesy of DELL
Quantized Congestion Notification (QCN): IEEE 802.1Qau provides end to end congestion management for protocols that are capable of transmission rate limiting to avoid frame loss. It is expected to benefit protocols such as TCP that do have native congestion management as it reacts to congestion in a more timely manner.
Data Center Bridging Capabilities Exchange Protocol (DCBX): a discovery and capability exchange protocol that is used for conveying capabilities and configuration of the above features between neighbors to ensure consistent configuration across the network. This protocol leverages functionality provided by IEEE 802.1AB (LLDP). It’s part of the 802.1az standard.
ETS provides hardware-based bandwidth allocation to specific types of traffic. PFC provides lossless Ethernet, this kind reliability is assumed (required) by the storage protocols where the traffic bypasses the operating system and leverages hardware offloading to the HBA (iSCSI, iSER, FCoE, and RDMA).
If you look at the implementation of DCB is seems incomplete. Windows 2012 R2 only has PFC and ETS. Some switches have only PFC, most have PFC, ETS, and DCBX but QCN is often missing.
Is the lack of DCB completeness an issue?
What the impact of DCBx not being available end to end? Well, potentially a lot of tedious work that needs to be done correctly but it’s not a show stopper. We can get things to work. Automation is your friend (PowerShell, switch CLI). As Windows has DCBx which you can enable or disable but is not functional it seems this is a stub that might be leveraged in later versions.
Quantized Congestion Notification is missing. For very large scale deployments you might want or need this. That’s what I understand anyway. Today it’s not in windows, many switches, let alone storage systems. But when you need to deploy converged on a very large scale you might need it, end to end. Fibre Channel fabrics have this (and boy they won’t let us forget that). But on the positive side, not having this never ruined the big iSCSI party we had for well over a decade nor is it wreaking havoc on FCoE deployments. The large cloud players leveraging SMB Direct and RoCE RDMA are not running into scalability issues (yet). Design plays a big part in this. So to me, this indicates that you will not run into issues with the size of deployments you’re most likely dealing with due to not having QCN. Is it ever coming and when? I don’t know. It might and necessity will be what makes it happen when needed I guess.
Why convergence makes sense
The concept of convergence makes a lot of sense. It’s getting it to work as it should that has tripped the industry up for a long time. After all, in the past, there has been said and written more about convergence than it has been implemented and achieved in the wild. That’s changing rapidly. Some, often smaller players that are great at engineering cost-effective solutions lead the way here. For the promise of convergence to come to fruition it has to work well enough to offset the costs in introduces. Yes, cost, that seems counter intuitive. Economies of scale, less cabling, cheaper commodity switches, less labor costs have made the CFO an early “adopters” of convergence. Well, at least of the concept. We need to realize that these savings are often assuming economies of scale that you might not necessarily have yourself. The potential is certainly there under the rights circumstances. The CFO and his team are very receptive to this and will certainly be on board. This seems like a match made in heaven. The business and engineering are both supporting the same technology. What could possibly go wrong?
Whether the benefits materialize depends on the environment, the needs and the politics at hand. So it’s not just about capabilities of the technology available. Well we need to make sure that the benefits of converged outweigh the costs it introduces.
Technical Limitations
Early attempts at convergence more or less failed. There are multiple reasons for this. There was the fact that the networking technologies to make it successful where not good enough. While the introduction 1Gbps, which quickly replaced 100Mbps in the data center was great, it’s capabilities where soon overshadowed by ever more network traffic for ever more workloads (iSCSI, virtualization, backups, data growth). This need for ever more bandwidth drove us to ever more 1Gbps pipes as 10Gbps was not readily available to many or feasible back then. This was helped by a steady influx of better CPUs with ever more cores.
On top of that the switch technologies for convergence in these scenarios were not adequate or missing and it introduced complexity and risk. Classic priorities & global pause just did not cut it for converged lossless scenarios in the real world.
Last but not least we get away with a lot by over-provisioning and avoiding QoS, which is becoming less feasible with modern storage (SSD, NVMe, …) & the various live migration options that are giving the network fabrics a run for their money.
A lot has changed as 10Gbps became affordable and available to the masses. 40Gbps and 100Gbps (and 25/50Gpbs) are here and are making their way into our datacenters. This evolution is gaining traction and is moving faster than most deemed possible or even necessary. On top of this convergence technologies are maturing steadily in the storage and network industry as well as in Windows Server. RDMA and DCB are playing a major part in all of this. Combined with 10/25/40/50/100Gbps switches and larger buffers we have the capabilities to deal with these amounts of traffic.
Who would have guessed 4 years ago that an SMB would be able to leverage a hyper-converged solution in Windows 2016 via Storage Spaces Direct (S2D). Technology available in box with Windows that leveraged better than 10Gbps networking, SMB Direct, NVMe disks etc with a 4 node solution? The economies are there now for smaller scale deployments.
Maybe I should not have to stress this but successful convergence does not have to mean 100% convergence. Success is not defined by perfection but by moving forward with the good to achieve the better. In order to do this one should avoid falling victim to “marchitecture” & cunning sales talk. Which isn’t always easy. Recently, at a wine tasting, none of the “seasoned” wine enthusiast could distinguish a white from a red wine when blind folded. It reminded me of many a managerial “strategical” choice in ICT based on glossy magazine articles.
There are still some very valid reasons that has slowed adoption of converged networks: operational challenges and risk that need to be balanced out.
Operational Challenges & Risk Isolation
Convergence does come with its own price tag. That of more complexity, more management and more risk. The latter as Windows Server updates, configuration changes and firmware/driver updates now affect more or even all of the converged network traffic flowing through our network cards and switches. Think about trouble shooting an issue. You now potentially affect all network traffic, not just one type. End to end architecture & design are need to deal with this.
It also requires an investment in modern switch hardware and topologies. This means a modern fabric and not a large classic switch design where layer 2 spanning tree can wreak havoc. It’s bad enough to lose client server traffic but imagine losing your storage traffic due to STP problems? Ouch! Fibre Channel or even completely isolated iSCSI networks get a lot of bad press lately but at least it never went down because of a network loop and spanning tree on the data network. There’s a trend to avoid these and other issues is to move layer 3 down to the Top of Rack switches but until all network traffic works over layer 3 (routed) networks we’ll have challenges in that department. There’s a lot of client access challenges with a layer 3 approach to deal with.
How important and feasible a non-blocking, high performance layer 3 fabric is depending on your environment. Having a network fabric to use when needed and possible makes total sense and avoids some issues. The big benefits of the fabric lie in the optimal use of both bandwidth, aggregation & flow of the traffic. The above has always been a challenge to implementing converged just as much as the lack of technologies to make it worth wile and feasible. Today however we see that the switches you buy today, can handle lossy and lossless traffic. So the cost of replacing network infrastructure is disappearing. It’s already in place. Good, that’s taken care of. Well, sort off, the implementation of DCB is not complete and can be complex to get working in a heterogeneous environment.
Distinct separate networks for East-West traffic (i.e the various live migration types), North South traffic (to your clients and services) and storage traffic are very tempting. It’s the (relative) easy of management and the isolation of issues due to hardware, driver problems or admin errors. That’s worth something.
Just look at the majority of iSCSI deployments in the wild. They are running on a dedicated network, often consisting of 2 completely isolated failure domains. Simple, reliable and with 10Gbps low over subscription risks. This is an exact mirror what FC itself had. A dedicated, isolated and independent managed storage network. Actually this is the case for the majority of iSCSI networks out there as well. And I do not blame the people who do so. I do this. It’s safe and easier to manage. It makes sense, storage is not something you can lose and get away with!
Sure the bean counters have less to rejoice about but that’s only one argument. The cost of complexity and risk is very real and impacts the business’s bottom line just as much, if not a lot more. You do not want to lose data ever. Never introduce risk and complexity you cannot or are not willing the handle or you will be in a world of hurt one day. Murphy’s Law affects us all sooner or later; the point is not to give Murphy a force multiplier.
Separate networks also take away the risks of spanning tree issues (layer 2 failure domains) and allow for a very comfortable capacity margin avoiding over subscription … you have all the bandwidth you need. Today all-flash arrays have opened the possibility for applications to challenge all that but a lot of them don’t generate that amount op IOPS yet. But still, the days that 8Gbps FC or 10Gbps Ethernet was a safe bet without worries is ending as the workloads start using that IOPS and use the full bandwidth of a 10Gbps NIC. In converged scenarios, the non-storage traffic like live migration is already giving 10Gbps cards a run for their money.
The software stack with converged solutions does not become less risky either. An example of this is bringing vRSS to the VM which requires DVMQ to work in a NIC team. Now add to that QoS, other NIC offloading features etc. That’s a lot of switch firmware, NIC driver, firmware and hypervisor network stack complexity layered on top of each other. Things do go wrong and sometimes it takes more time to fix than we have in reality.
Then there is the fact that some very interesting capabilities don’t mix such as SR-IOV and NIC teaming or RDMA and NIC teaming. Things are evolving all the time so in the future, we’ll see new capabilities. Just look at what’s happening in Windows Server 2016 where SET is enabling scenarios that were not possible before.
Choices
To converge or not to converge? If so 100% or a mix. If so what types of in QoS? Which flavor of RDMA for SMB Direct? And then, even more, choices on how to put it all together. There is no one size fits all. It takes a certain breadth and depth of understanding of what’s happening and possible at many levels. This is a challenge.
What do I prefer for my networking? Nothing. I’ll build what’s needed to the best of my abilities with the resources at hand. If the conditions are not right to make that happen I will tell you so. Non converged or converged, and if the latter, what flavor(s) of QoS, and if SMB Direct is needed with or without DCB all depends on the environment and the available resources. Not all combinations work or are even supported or wise.
I have done SMB Direct/ DCB alone where the vSwitch had no QoS whatsoever (A), SMB Direct/DCB and Hyper-V QoS combined on the same hosts (B) or Hyper-V QoS (C) alone. The latter is something I like in scenarios where there is no RDMA/DCB capability and workloads not too demanding. It’s easy, even if it has some drawbacks. One is the loss of RSS to the host due to the vSwitch leveraging DVMQ. This means you’ll hammer that poor single core 0 of your CPU limiting the total throughput. This loss can be mitigated by having multiple vNIC and by leveraging SMB multichannel, but still it’s not great.
I only do native QoS if it’s the best or only option available (D).
If I can get away with raw bandwidth, I’ll gladly take that option (E). In some situations, today the use of 8 or 10 individual 1Gbps NIC ports per host still makes sense if that’s what’s at hand to solve the problems we’re facing.
Many a manager or IT Pro who asked me what I prefer had to live to live with a longer answer than just a choice between A, B, C, D or E. To get to that answer I have to ask a lot of questions. It depends! Yeah, yeah, I know, go read https://blog.workinghardinit.work/2015/01/09/dont-tell-me-it-depends/ if you don’t like my answer!
There is one nothing you need to realize. In modern converged environment you’ll need DCB and RDMA. In the Windows ecosystem that means SMB Direct leveraging lossless Ethernet (PFC) and QoS (ETS). Now DBC is not perfect but neither are you. Still, you can live a fun and productive life. Perfection is not of this world but the industry is making progress with lossless Ethernet to a level where it’s more than just good enough. When I see initiatives around RoCE in NVM Express Fabrics it seems the indicate DCB as is will do the job. There’s DCB for FcoE, iSCSI, we have iSER (iSCSI Enhancements over RDMA) etc … this all points to DCB being up for the job. Which means Windows is a valid software-defined storage platform that’s maturing.
Storage & Lossless Ethernet
Since Windows Server 2012 we’ve had the Scale Out File Server (SOFS) to deliver storage to our workloads over a file share over SMB 3. While there is no strict need for SMB Direct it does make SOFS more performant and scalable. The storage behind that SOFS can be deliver by shared PCI RAID, traditional shared SAN storage or shared SAS leveraged by Storage Spaces. In Windows Server 2016 Storage Spaces Direct (S2D) delivers us the option of Converged and Hyper-Converged storage on top of this. The latter two options leverage non shared storage that can still be consumed by a cluster either direct (Hyper-Converged) indirect (Converged).

Figure: S2D deployments Courtesy of Microsoft
The storage used can be internal to the (storage) server nodes.

Figure: S2D with internal DAS Courtesy of Microsoft
The storage can also reside in JBODs (or even a combination of internal disks and JBODs, as far as know at the moment of writing).

Figure: S2D with JBOD Courtesy of Microsoft
Nonshared storage means you can now even leverage non SAS or NL-SAS disks like NVMe (Non Volatile Memory Express) disks. This delivers even more options for cost effective, performant, low latency storage in even more use cases.
Key to making this happen is a high throughput, low latency network to keep the multiple copies in sync across the nodes. In other words, here comes SMB Direct into the picture again for yet another use case.
The technology enabling all this RDMA. RoCE in Windows Server 2016 TPv2 but also Infiniband and iWARP in the future. Who says RDMA over RoCE (and even over iWARP) says DCB with PFC to achieve a lossless network and a scalable high throughput, low latency network. Add ETS in converged scenarios for a more predictable and consistent behavior. In combination with improved ReFS we’re seeing certain ODX like capabilities delivered at low cost in Windows Server 2016.
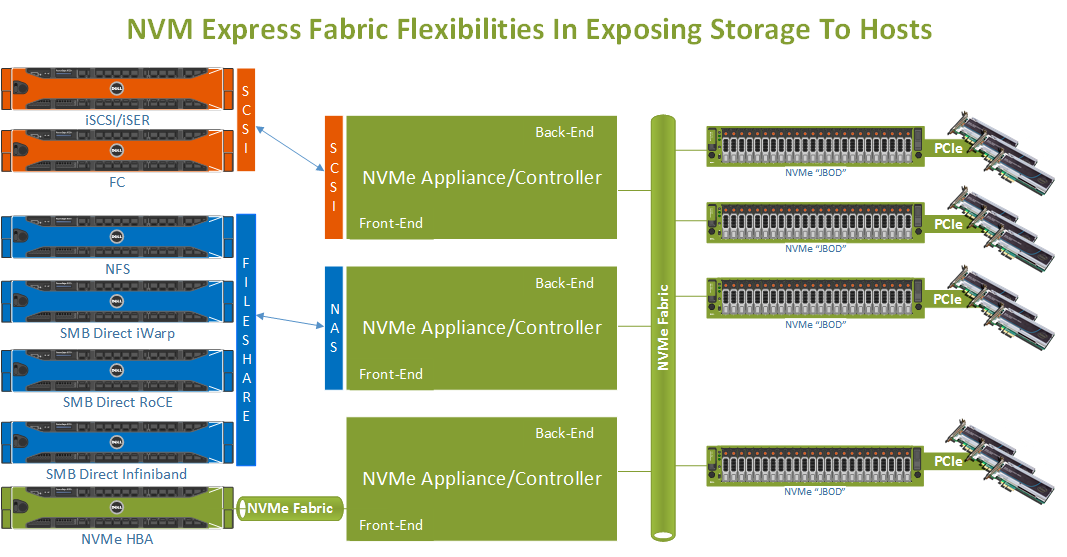
The industry is also hard at work in developing NVMe Fabrics which will enable us to leverage NVMe disks in large storage arrays to deliver ever more IOPS at very low latencies. Again, high throughput, low latencies and low CPU load are the realm of RDMA so it will come as no surprise the fabrics leverage RDMA (RoCE or iWarp) to achieve these characteristics in an NVMe Fabric.
Perhaps these trends will motivate storage vendors to deliver storage to the client servers over a feature complete SMB 3 stack, including SMB direct. Todays this remains an issue. They, potentially, could even offer all RDMA flavors like iWarp, RoCE or Infiniband to the hosts so you won’t lose your prior investments or get locked into one flavor of RDMA. For environments where SMB 3 is not viable NFS or iSER (iSCSI Extensions for RDMA) can be leveraged.

Figure: Didier Van Hoye
It does seem that these lossless Ethernet protocols are poised to play a leading role in storage fabrics. We can even envision native NVMe from the storage array to the hosts. After all those vast amounts of IOPS at low latencies need to be delivered to the hosts. Having said that, the Fibre Channel world is also working on MVMe fabrics but I don’t see this being big in hyper-converged solutions today. And then we haven’t even mentioned iSCSI Extensions (iSER) for RDMA. Interesting times ahead indeed!
No matter what happens it’s clear that SMB 3 is leveraged for more and more use cases in the Windows Server stack and as such SMB Direct with RDMA as well.
RDMA is also leveraged by many storage vendors in various ways (DELL Compellent Fluid Cache for SAN, VMWare, NVME Fabrics …) so don’t think for one minute this is a Microsoft/Windows only game. It’s a network and storage industry play in an ever more converged world.
Do note that both SOFS, CSV, various forms of live migration and the Storage Spaces Direct traffic leverage SMB Direct and as such will not be distinguished from each other by PFC or ETS. The fact that all this traffic benefits from being lossless means that’s not an issue for PFC. But we cannot leverage ETS to distinguish these from each other. I wonder if this is a problem that will materialize or not. The trick is and will be to provide the required bandwidth where and when needed. QoS protects bandwidth boundaries, it does not create bandwidth.
I have invested a substantial amount of my time in SMB Direct and DCB. I am an early adopter in the Windows Ecosystem and I’m happy I did that. There is no reason for you to delay any longer and get up to speed. The good news is you have not missed the boat. Things are only just getting started and the journey looks promising. The message we’ve gotten since Windows Server 2012 (R2) is getting louder. Add to this that SMB Direct is leveraged for more use cases such as storage replication, RDMA being available to the host via the switch when leveraging Switch Embedded Teaming (SET) and Storage Spaces Direct (S2D) leveraging this and it should by now be crystal clear to you.
You don’t have to be a top level expert but just like common knowledge about TCP/IP strengths and weaknesses comes in handy when implementing iSCSI, you might want to get a grip on some of the characteristics of SMB Direct (RDMA) and DCB.
Converged networking and both converged / hyper-converged storage is becoming more and more common. Windows is no exception to this trend. The capabilities to deliver on potential on converged solutions are increasing and improving while costs are coming down. A good architecture and design, based on capabilities, complexities and risks will be paramount in making that happen successfully.
As long as you remember that for you, the consumers of the four principal resources in IT, compute, memory, network and storage convergence are means to an end and not a goal I’m pretty sure you’ll be able to make the right decisions. You can wait for the perfect world or act now on what’s available and which is better than what we ever had before. The industry has certainly chosen the latter and seems to be moving forward fast. While you might not build all this yourself it does mean that as a Windows engineer you want to understand why, where and how SMB Direct, RDMA, DCB are used and what the impact of convergence and QoS – both technically and operations wise – is.

{kind=link}
{kind=link}
{kind=link}