

Introduction
The need or perceived need for hard CPU processor affinity stems from a desire to offer the best possible guaranteed performance. The use cases for this do exist but the problems they try to solve or the needs they try to meet might be better served by a different design or architecture such as dedicated hardware. This is especially true when this requirement is limited to a single or only a few virtual machines needing lots of resources and high performance that are mixed into an environment where maximum density is a requirement. In such cases, the loss of flexibility by the Hyper-V CPU scheduler in regards to selecting where to source the time slices of CPU cycles is detrimental. The high performance requirements of such VMs also means turning of NUMA spanning. Combining processor affinity and high performance with maximum virtual machine density is a complex order to fulfill, no matter what.
Today the amount and quality of compute, memory, bandwidth and storage IO at low latencies you can deliver to virtual machine with modern hardware is nothing but impressive. Most of you will run out of money before failing to serve the needed resources to an application and then deciding to go for another approach. That different approach could be a dedicated hypervisor setup for those virtual machines or could be found in a hardware based solution. The requests for hard CPU processor affinity died down somewhat over the years as hardware became ever more performant, prices dropped and hypervisors matured into highly performant solutions.

Lately, with ever more demanding workloads being virtualized the number of questions around setting processor affinity and reserving entire CPUs to a virtual machine seems to be on the rise again. Often this is combined with a request to have the ability to disable NUMA spanning on a per VM basis. Some of industry solutions run their entire fabric, including the storage components (storage controllers), software defined networks and backup targets in virtual machines. This means that these VMs, no matter how performant the hosts are, share resources with other virtual machines. This is not criticism against such solutions, like “cloud in a box offerings and some converged or hyper-converged offerings, it’s just an observation. These are sometimes the best of breed and the better solution for certain environments and needs. No size fits one however and, as anything in IT, it has it strengths and weaknesses, its benefits and drawbacks.
The question is whether the size and number of these use cases are sufficient to have hypervisors cater to those needs. In other words, is it smart to invest in trying to meet those needs when the vast majority of deployments have no need for it? Many people that ask for it, seem to do so out fear that performance or consistence in performance might not be met. Or it’s a proxy question for some ISV making demands for their applications that might be based on testing for that application 10 years ago on a version of Microsoft Virtual PC or the like.
What are your options to get top notch performance?
First of all, make sure you do not under provision anything. You’ll need sufficient network throughput and storage IOPS at low latencies to handle anything that’s thrown at your virtual machines. Provide for enough of the fasted memory money can buy. Don’t save on the speed and number of cores. If needed turn to SR-IOV, RDMA etc. to make sure you get the best possible performance for your workloads. Hyper-V supports a number of high performance technologies to cater to demanding workloads. When those options are covered we can monitor the Hyper-V hosts and virtual machines to see if they get all the resources they need.
Next to that Hyper-V allows you to configure some settings on the hosts and the virtual machines that will optimize performance in the most virtualization friendly manner. These are NUMA spanning and optimizing the CPU scheduling.
Disable NUMA Spanning
For top notch performance, you’ll need to disable NUMA spanning on the host. This cannot be done on a per virtual machine basis on Hyper-V. Remember it also has some drawback towards density and results in some loss of flexibility in regards to achieving maximum virtual machine density at all times. This is because with NUMA spanning disabled it could mean a virtual machine cannot start or live migrate because the required amount of memory per NUMA node is not available.
Disabling NUMA Spanning also means that VMs with dynamic memory are always limited to the memory of a single NUMA node. You cannot have virtual NUMA and dynamic memory simultaneously.
Note that a virtual machine with multiple vCPUs having multiple NUMA Nodes running on a host with NUMA spanning disabled will still get memory from multiple NUMA node, but a virtual NUMA Node will not cross it’s NUMA boundary. Let’s take a 2 vCPU VM on a 2 NUMA node host that has been assigned more memory that a single NUMA node can provide as an example. This means the virtual machine gets 2 NUMA nodes assigned.
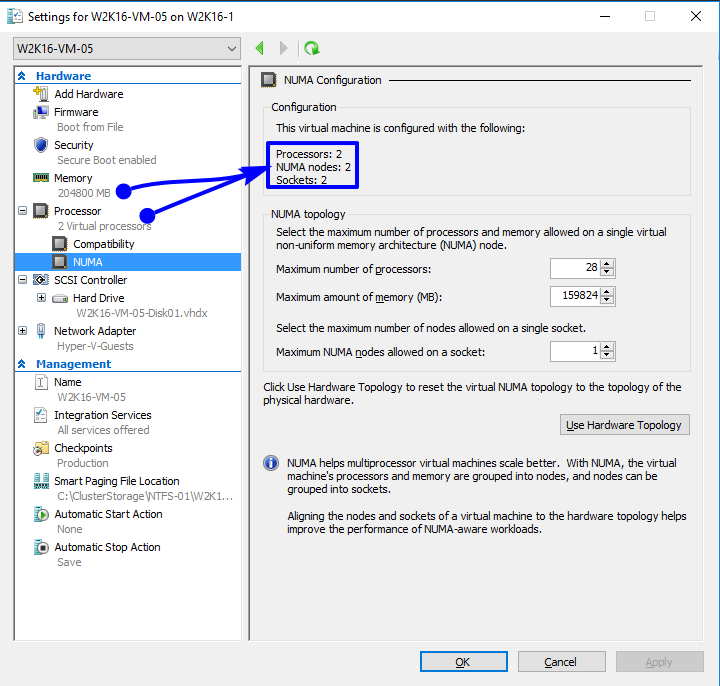
Even with NUMA spanning disabled this doesn’t mean that the virtual machine won’t start. As it has two NUMA nodes assigned each vCPU will get memory from its own NUMA node. In the virtual machine this look like below.
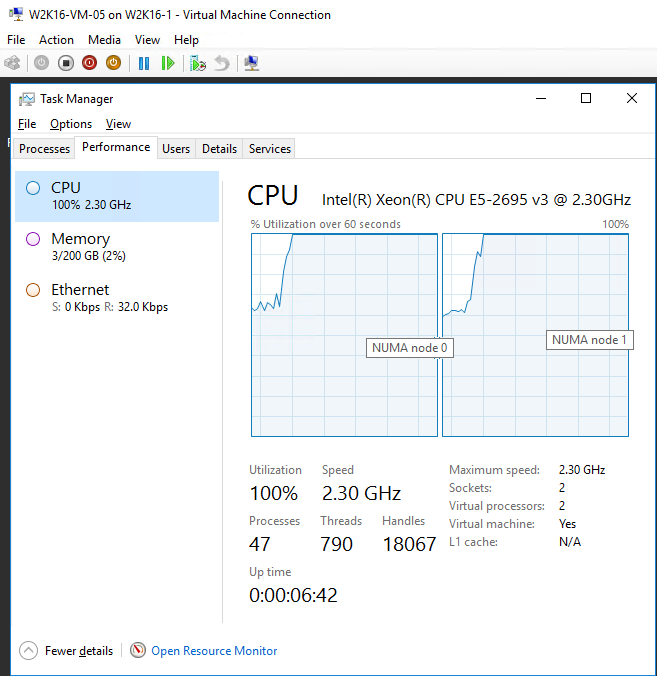
With NUMA spanning disabled this means that 1st vCPU gets compute time slices from the 1st NUMA node and gets memory form that same NUMA node and the 2nd vCPU is getting processor time slices from the other NUMA node and gets its memory form that NUMA node. With NUMA spanning enabled this is also attempted, but memory from another NUMA node can be used if it’s needed to start or live migrate the virtual machine.
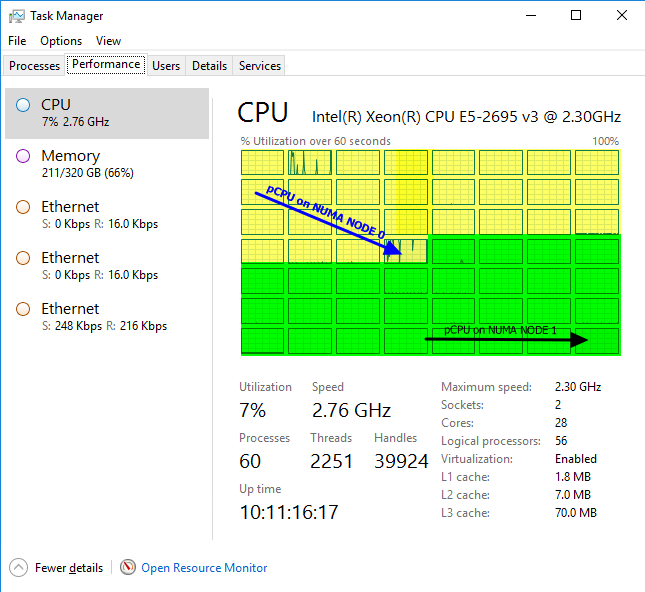
With NUMA spanning disabled the vCPU will never consume memory from a different NUMA node. For this to work well you need NUMA aware apps in the virtual machine. These will benefit by getting the best possible performance consistently between reboots because the virtual NUMA topology of their VM aligns with the physical NUMA topology of the host.
You also need to accept that under certain conditions those VMs might not start, migrate. You sacrifice the best flexibility and density for performance. That means you really need to size your hosts accordingly.
Processor Affinity
So what about hard processor affinity? Without it we cannot reserve and dedicate an entire pCPU for a vCPU can we? Yes, you can and that requires no hard CPU affinity. As a matter of fact, I actually did that in the example above.
All you need to do is set the virtual machine reserve for the processor setting of a virtual machine to 100 %.

In the example above the Hyper-V scheduler guarantees that wherever the virtual machine is running it will get 2 complete processors for its needs. As it has 2 vCPU and more memory than a single NUMA node can provide it get to virtual NUMA nodes assigned meaning both vCPUs run on different NUMA nodes or a 50/50 split
The thing to note is that while you reserve 100% of a pCPU for the vCPU it’s not a fixed pCPU. So Hyper-V scheduler keeps the flexibility of moving to a different core (within its NUMA node) when it’s better to do so. All this while still having 100% of a CPU when it’s needed.
When need is important here! This is not a reservation that is enforced when the VM doesn’t need the cycles. It only gets them when needed. Think of it a minimal QoS guarantee, you’ll get it when need without needlessly holding on to them if you don’t. As that reserve is set to a 100% you’ll get it when the need arises.
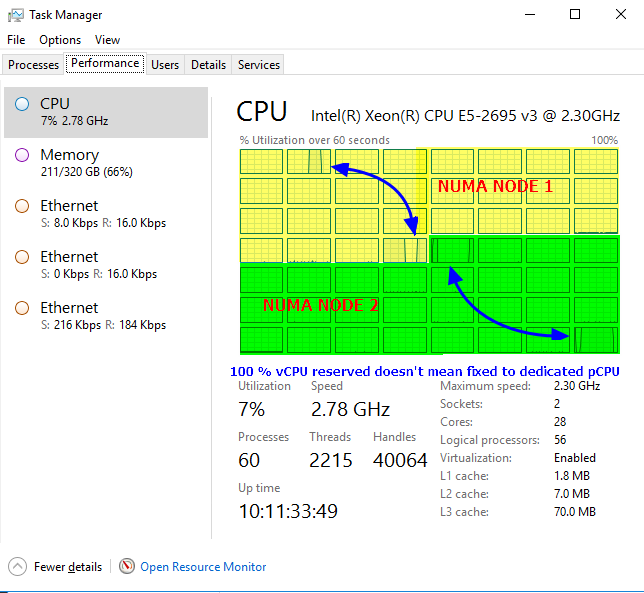
That’s it. You do not control what pCPU it is, so that can and will change. Remember that a vCPU gets time slices of CPU cycles. You do get the equivalent of 100% of a pCPU (or pCPUs) reserved for that virtual machine when needed just not by setting an entire pCPU aside for you as it would waste resources needlessly.
This all sounds great but it comes with some restrictions you need to be aware off. First of all, the total CPU reserve cannot be higher than what’s physically available on the host. Don’t go and reserve a 100% for all your VMs with the idea they only get it when it’s needed. Do remember that “reserved” means it has to be there when needed. A 56 core host can only have 56 single vCPU VMs with a 100% reserve. Or 28 with 2 vCPUs and a 100% reserve. When you exceed the available physical resources the VM won’t start or live migrate. Even worse when you add VMs you’ll need redistribute the reserve % to accommodate the new ones. Likewise, then you remove VMs. It becomes a tedious exercise which requires down time. So only use the virtual machine reserve with moderation on those VMs where you need to guarantee CPU cycles to be available when needed and leave the others at 0. One use case where you might evaluate setting it for all VMs is in a high performance SQL Server virtualization environment where you need to guarantee top notch performance and actually don’t want new VMs being brought up without you intervening, which is prevented by you reserving 100% of the available CPU cycles to the VMs you know about.
In reality it’s even a bit more complicated. Consider a Hyper-V host with 56 pCPU. Let’s say you create a single 56 vCPU VM (W2K16-VM-01) with a 30 % reserve (30% of what’s available on the host).

and another VM W2K16-VM-02) with 8 vCPUs with 80% reserve (11% of what’s available on the host).
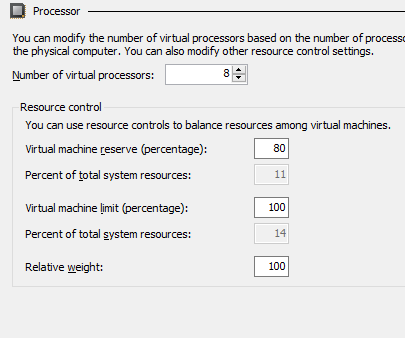
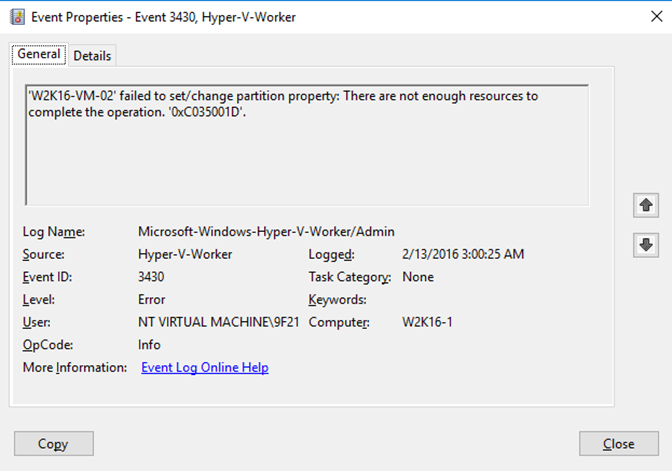
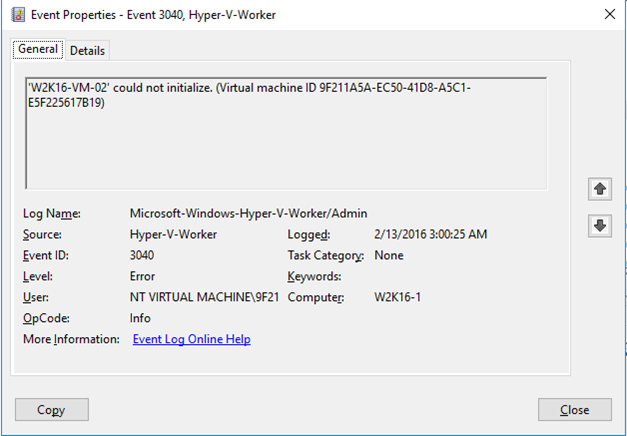
These can 2 VMs can’t start on the same host. The VMs with 56 vCPU might only reserve 30% of the total physical CPU cycles available, but it does so over 56 pCPU. There are no 8 pCPU to be found that have 80% to be reserved. On a cluster that will means the VM will start on another node that has the resources. When live migrating this is also a factor, W2K16-VM-02 will not move to the node where W2K16-VM-01 is running. You’ll see 3430 errors logged in the Microsoft-Windows-Hyper-V-Worker/Admin event log:
There is more to be said of virtual machine limit and weight. Weight might the more interesting one here in this context but it’s not guaranteed like the reserve, so it’s not really the better choice in our discussion here.
Conclusion
This is a discussion that seem to come up again more recently after it had died down somewhat over the years. In the end I’m not convinced that a lot of the people who request dedicated, hard vCPU Processor affinity actually need it. It has drawbacks as well and those might very well outweigh the benefits you hope to gain from it.
I hope to have demonstrated that while affinitizing vCPUs to pCPUs and disabling NUMA Spanning on a per VM basis sounds like it’s needed and a good idea, it probably isn’t. NUMA spanning per VM isn’t the best possible way of managing memory allocations on a host as it means more complexity & restrictions for the scheduler. Combining both hard CPU affinity and NUMA Spanning setting on a per VM basis would become a serious micro-management effort for the Hyper-V scheduler that then needs to distinguish between two types of VMs for both CPU cycle and memory allocation on the same hosts. There are good reasons why Hyper-V doesn’t take this approach.
I hope to have shown you at least the basics of getting the maximum guaranteed CPU performance out of your virtual machine, when needed, by using the virtual machine reserve and by disabling NUMA spanning on the host.
As always you need to consider the benefits and drawbacks when deciding to use these options. If you cannot get the last few percentages of performance consistency for your virtual machine by reserving 100% of the vCPU or vCPUs of that virtual machine and disabling NUMA spanning on the host, you might need to consider another solution.
In another article I’ll be diving into the behavior of disabling NUMA spanning a bit deeper.

{kind=link}