

You may have heard that RAID is no longer applicable for enterprise storage: that it’s time had passed. RAID has dominated enterprise storage for decades and, while not a hot topic of conversation today, it remains a key strategic approach for businesses to consider.
To some degree, it is true, RAID is no longer the singular answer to enterprise storage that it once was. For decades it was unchallenged as a technology and as an approach, and so reigned alone – a foregone conclusion in a giant sea of storage. Today, RAIN has joined the space and is a viable alternative to RAID in many scenarios. But just because RAIN is newer and the darling of storage conversations does not mean that RAIN will simply displace RAID nor that RAID’s position of importance has been eliminated. Not at all.
First, we should compare RAID and RAIN. RAID, or the Redundant Array of Inexpensive Disks, is a “disk-aware” storage abstraction technology that uses striping, mirroring, or parity to turn multiple, logical disks into a single logical drive that is enhanced through some combination of speed, capacity, or reliability. RAID can still span physical servers over a network (called Network RAID), but still does so viewing all array members as logical disks, so nodal awareness is an artefact of disk awareness as a logical abstraction that represents the server node rather than being native.
RAIN, or Redundant Array of Independent Nodes, is a true nodally aware array technology that generally works through a combination of “sub-drive” level (typically block) awareness combined with high-levelserver node awareness. RAIN is a loosely defined group of non-RAID technologies and so will differ dramatically from implementation to implementation and cannot be categorized easily. RAIN is, in many ways, comparable to NoSQL while RAID is comparable to relational databases, in the loosest of senses. Both have their place, while one is highly defined and the other is a loosely associated collection of technologies that only eschews the first.
There is no doubt that RAIN is important and growing in importance. But RAID is simple, well tested, and very well understood. Most RAIN implementations, while often very advanced, can be problematic for implementation engineers to predict for performance, reliability, and possibly even capacity. RAID’s long history and strict definitions mean that formulas, characteristics, and implementation rules are well known and easy to research.
RAID comes in a set of basic “levels” or definitions and a few different styles. Traditional RAID is handled locally on a single server, but there is no reason that RAID communications cannot be over a network and this is commonly done in order to create clustered systems. RAID can be handled by dedicated hardware controllers, or in software. RAID, due to its abstraction as standard drives, can be layered or “nested” allowing one RAID level to exist on top of another, providing for an ability to creatively modify RAID characteristics for larger deployments.
First, to analyze each accepted RAID level.
RAID 0 – Striping
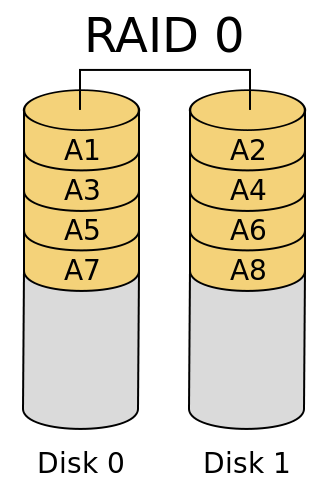
RAID 0 is the most basic level of RAID and is a simple striping of data across the disks in the array. You need only a minimum of two disks but can grow as large as desired. RAID 0 provides very high performance, with one hundred percent efficiency of capacity, but has no mechanisms for data protection and therefore is incredibly risky. As the number of drives in the array increase, the risk of data loss increases accordingly. If any drive in the array were to fail, the entire array would be instantly lost and no data is recoverable. Typically, RAID 0 arrays are used for ephemeral data only, such as in caches or “scratch space”. With modern cloud computing, they are sometimes used for stateless systems that are redundant elsewhere.
RAID 1 – Mirroring
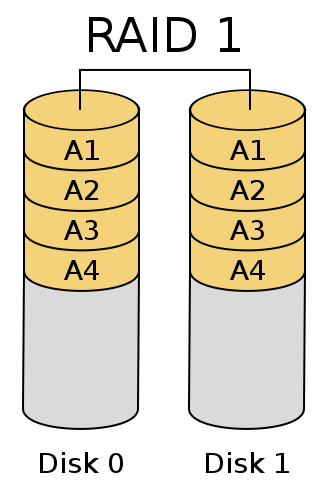
RAID 1 is the most commonly used and often the most practical RAID level. RAID 1 consists of simple mirroring, just keeping two (or more) disks in perfect sync. This may sound simple, but in this simplicity lies the power of RAID 1. With mirroring there is low overhead and extremely high reliability. In fact, RAID 1 is, by far, the most reliable form of RAID available. RAID 1 is chosen when reliability is the key objective, as adding additional drives to a RAID 1 array does not expand its capacity and does little to improve performance.
RAID 5 – Parity Striping
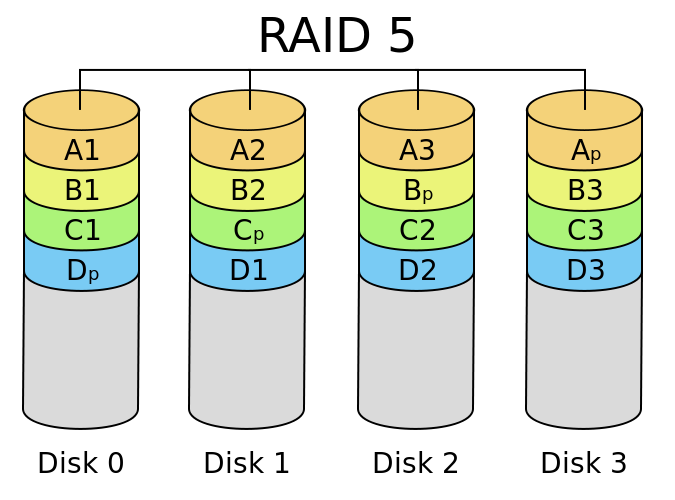
RAID 5 uses a single parity stripe mechanism to provide data protection. RAID 5 increases in capacity and performance as additional drives are added to the array, while decreasing in reliability. RAID 5 is tuned heavily towards maximizing capacity, while mostly sacrificing reliability. RAID 5 was traditionally very popular when disk capacity was of key concern, especially in the 1990s and very early 2000s, but today tends to be used only for smaller solid state based arrays. In order to accomplish its parity, RAID 5 consumes the capacity equivalent to one of its array members (drives) for parity, but the parity does not reside on a single or specific drive. RAID 5 requires a minimum of three drives.
RAID 6 – Double Parity Striping
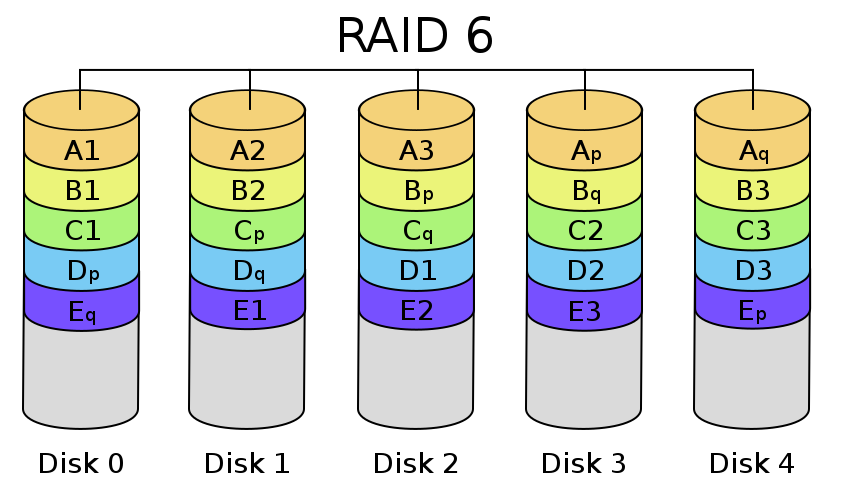
RAID 6 extends what we had with RAID 5 by adding a second parity calculation, and consuming two drives worth of capacity in order to do so. In doing so, RAID 6 sacrifices some capacity compared to RAID 5, but dramatically increases reliability, roughly by an order of magnitude. RAID 6 has broadly supplanted RAID 5 in modern usage, especially with mechanical or “Winchester” hard drives. RAID 6 requires a minimum of four hard drives.
These RAID levels form the foundation for essentially all RAID that we use today. Some archaic RAID forms, such as RAID 2, 3, & 4, have passed into IT history and are no longer considered useful. Some highly unique or proprietary RAID levels can be found such as RAID 7 (aka RAIDZ3) or dual parity RAID 4 (aka RAID-DP) and so forth, but are not widely available and depend on a single implementation and not worth discussion in an overview of the technology.
Most importantly, complex or nested RAID levels, one RAID on top of another, play an important role in every day RAID usage with RAID 10 and RAID 60 being the most important and influential nested RAID types. RAID 10 is so important that it may rival RAID 1 and 6 as the most common and important form of RAID overall.
RAID 10 – A Stripe of Mirrors
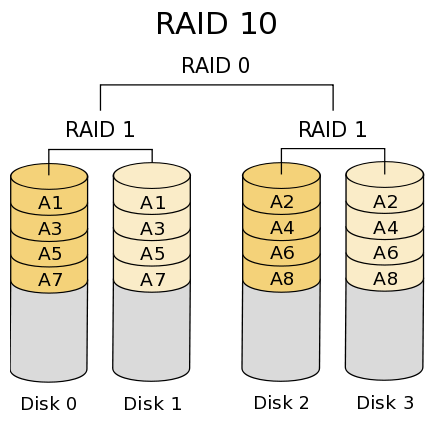
RAID 10 is a single RAID 0 stripe over top of a series of two or more RAID 1 mirrors. This gives RAID 10 incredible reliability while still being able to scale, but has a low capacity utilization rate. RAID 10 is today the most popular RAID level for large, mission-critical workloads due its extremely high reliability while still scaling up performance and capacity.
This provides an overview of common, standard RAID levels and when they might be used. While it might be tempting to dive into a discussion of exact reliability, RAID is not so simple and we must be very cautious about attempting to find simple answers to complex questions. Many sources will attempt to simplify RAID reliability into terms like “how many disks can be lost” but RAID works nothing like that and cannot possibly be described in such a way. RAID suffers from a range of different risks that affect different drives, arrays, and array sizes differently. Understanding RAID risk is extremely complex and “how many drives can be lost” simplification isn’t just wrong, it will lead to outright incorrect choices even when comparing one RAID type to another.
Capacity and performance characteristics are far more predictable, but even those can require more than a simple overview. Individual implementations may alter expected results, for example, and different workloads will interact with different RAID types in a multitude of ways.
Even after several decades, RAID remains complex and elusive to a deep understanding, but still highly relevant and the right answer for many workloads and systems.
Follow my RAID series on YouTube where I work through many of the details behind RAID.
