

We are continuing our set of articles dedicated to Synology’s DS916+ mid-range NAS units. Remember we don’t dispute the fact that Synology is capable of delivering a great set of NAS features. Instead of this, we are conducting a number of tests on a pair of DS916+ units to define if they can be utilized as a general-use primary production storage. In Part 1 we have tested the performance of DS916+ in different configurations and determined how to significantly increase the performance of a “dual” DS916+ setup by replacing the native Synology DSM HA Cluster with VSAN from StarWind Free.
To be honest, we were not really satisfied after achieving just the raw performance metrics in our previous research. Today we will cover another important aspect of the highly-available clustering. Actually, it does not really matter how much IOPS your HA storage has if it fails to recover in time and causes your VMs to freeze or shut-down. Thus, the main question left is the failover duration.
Measuring the failover duration of 2x Synology DS916+ in DSM HA Cluster setup
Test lab description
We have configured the same kind of setup as we used previously in our performance benchmarks.
Remember that DSM HA Cluster works in “active-passive” mode and Multipathing is not available since 1x1GbE port on each Synology unit is used for replication and Heartbeat.
Network diagram:
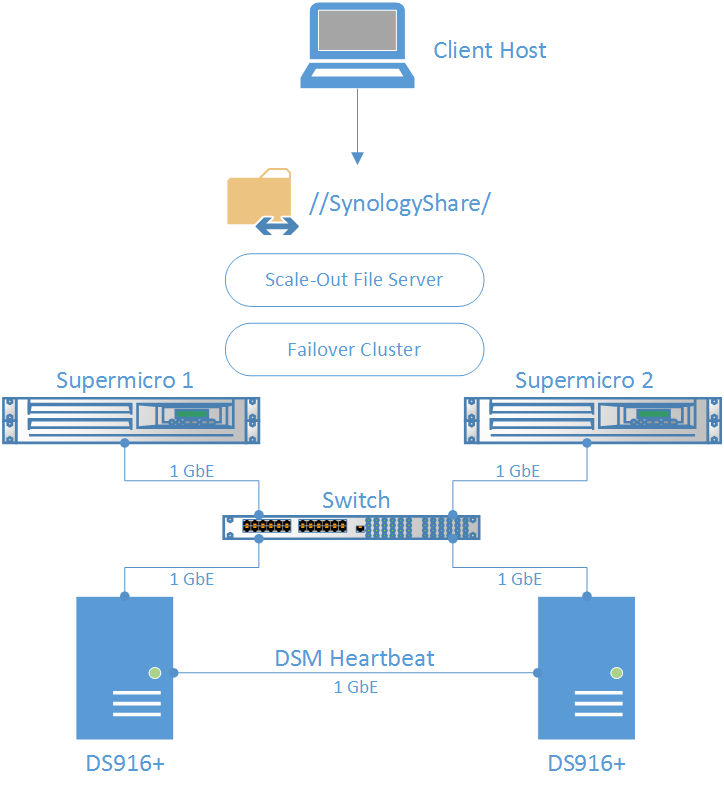
Configuration description:
- 1TB HA iSCSI LUN is presented by Synology DSM HA Cluster
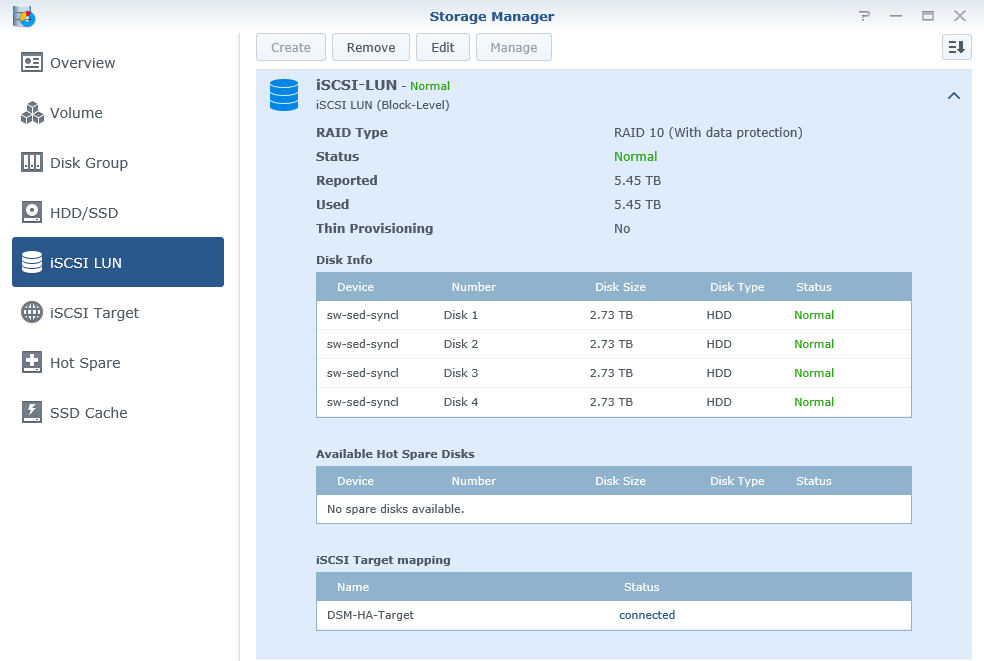
- Each Supermicro server is connected to iSCSI LUN via 1x 1GbE NIC
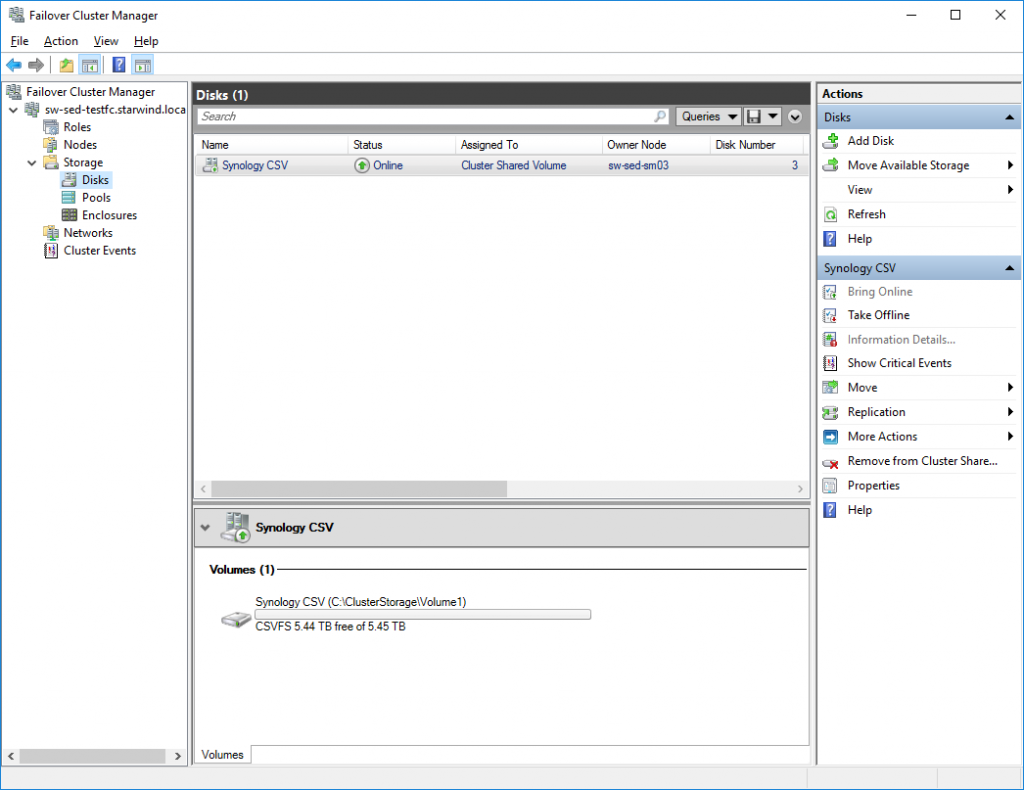
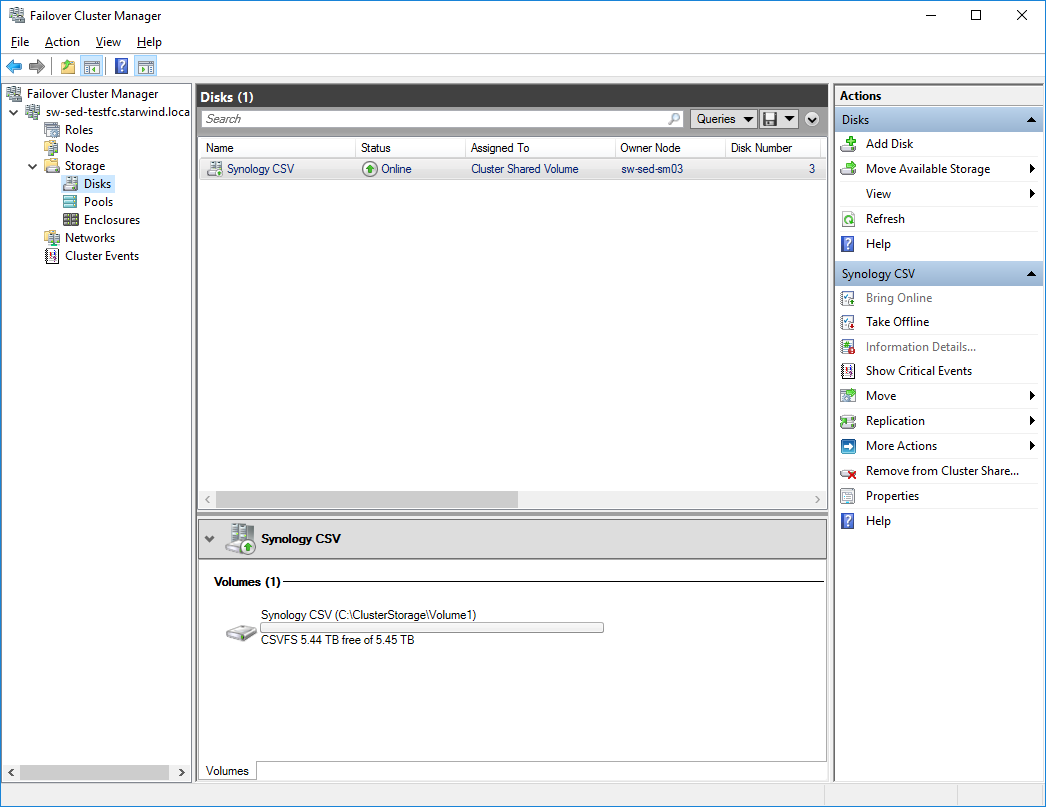
- iSCSI LUN is mounted on both hosts and added as Cluster Shared Volume (“Synology CSV”) to Windows Failover Cluster.
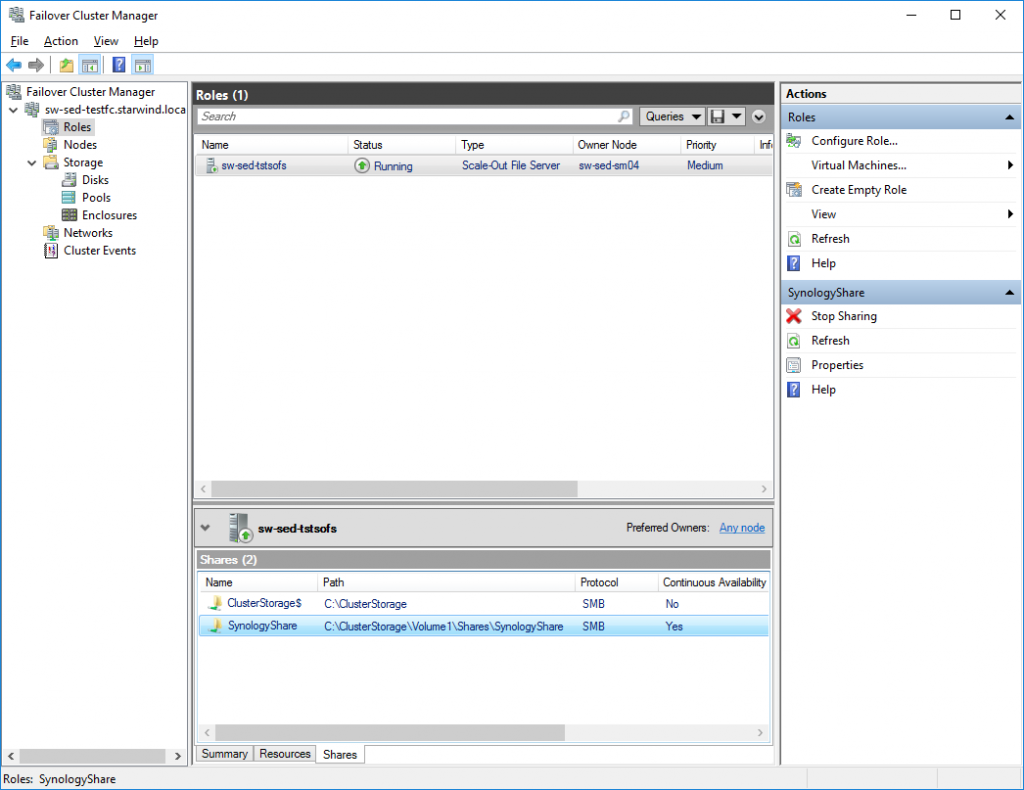
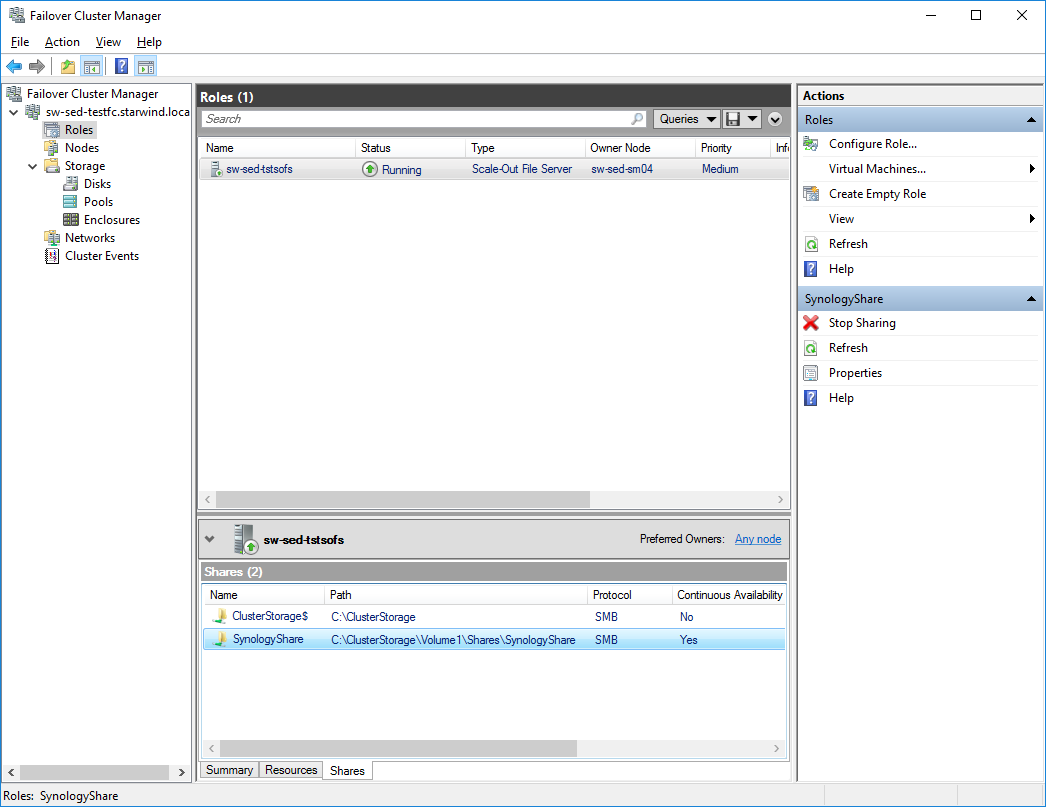
- Scale-Out File Server role is deployed inside Failover Cluster
- File share is created on top of Cluster Shared Volume (“SynologyShare”)
- “SynologyShare” is mounted on the remote client host
We would like to determine the exact failover duration. That’s why we have chosen to deploy SOFS role and perform our tests using the file share instead of, for example, pinging the virtual machine located on top of the corresponding CSV. Monitoring data transfer via SMB protocol will show what we are dealing with in a clearer way.
1st test case: “Soft” failover in DSM HA Cluster
First of all, we decided to test the soft “switch-over” (that’s how failover is called in DSM). The procedure is fairly simple: while copying a test file from the remote client to “SynologyShare”, we will initiate the “switch over” from DSM HA Cluster Manager.
During “switch over” DSM will switch the current active node with passive, changing the corresponding iSCSI sessions the same way as well.
We have measured the “black out” duration from the moment when data transfer has stopped and to the point when it has been completely restored. This timeframe is what we consider as failover duration.
Highlighted part of the progress bar indicates the failover period:
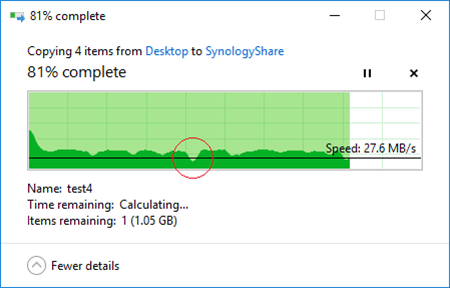
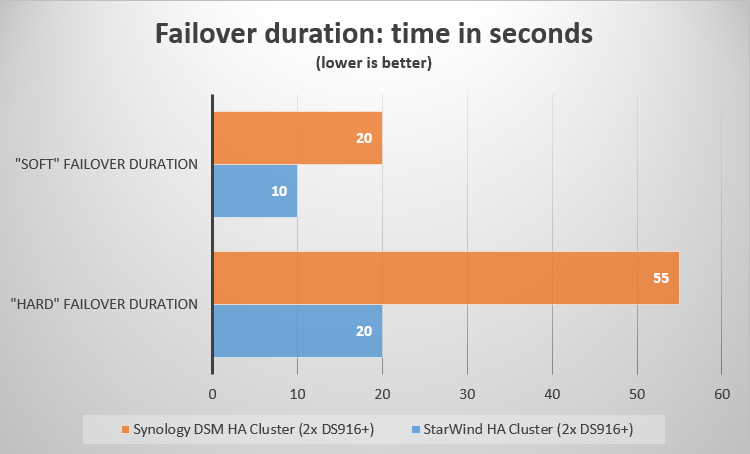
The total failover duration in case of soft switch-over was 20 seconds.
In 20 seconds I/O was restored. This is a good result meaning the most of the virtual machines, that may be potentially stored on “Synology CSV”, would be able to continue running after failover without falling into “blue screen” or encountering errors.
2nd test case: “Hard” failover in DSM HA Cluster
Our next step is to test the “hard” switch-over. In this experiment, we are simulating the power outage on our “active” DS916+ unit by pulling-out its power cord. After the power outage, DSM HA Cluster will use Heartbeat network to detect that “active” node is absent and initiate the “switch-over” to the partner unit.
We are using exactly the same lab configuration as in our previous test. The only thing that has been changed is how do we trigger a “switch-over”.
Highlighted part of the progress bar indicates the failover period. Interestingly, this time the data transfer was not as consistent as before:
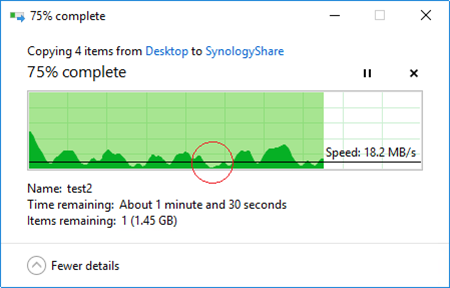
It took 55 seconds to completely restore I/O. Obviously, this time failover was initiated unexpectedly which resulted in some extra efforts for DSM HA Cluster to redirect iSCSI sessions. Nevertheless, the achieved failover duration is less than a minute and should not seriously affect virtual machines located on the corresponding storage.
Measuring the failover duration of 2x Synology DS916+ with VSAN from StarWind
Test lab description
In order to perform the next set of test, we are switching the HA storage provider from DSM HA Cluster to VSAN from StarWind Free. In this configuration, StarWind is deployed on Supermicro servers and Synology boxes are used as a simple “iSCSI-attached” storage. StarWind Synchronous Replication and Multipath I/O will give us the ability to utilize both Synology units simultaneously and should decrease the failover duration.
Each Synology DS916+ unit is connected to the corresponding Supermicro server via 2x 1GbE networks. Supermicro servers are connected between each other via the single 10GbE network that will be used for both StarWind Synchronization and iSCSI traffic. 10GbE network is used to eliminate a possible network bottleneck.
Network Diagram:
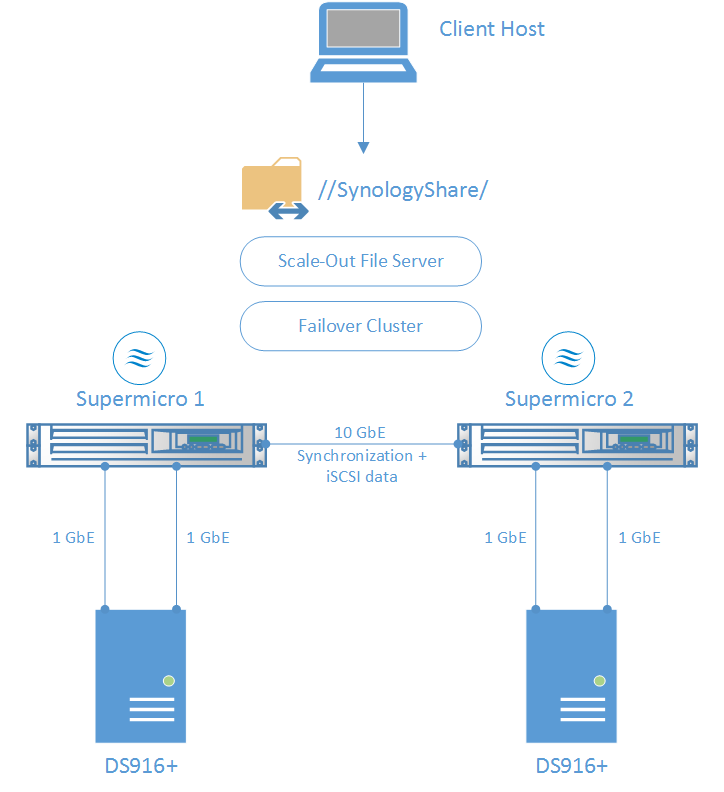
Configuration description:
- Similar 1TB iSCSI LUNs are created on both Synology boxes (“iSCSI-LUN1” and “iSCSI-LUN2”)
Synology unit #1

Synology unit #2
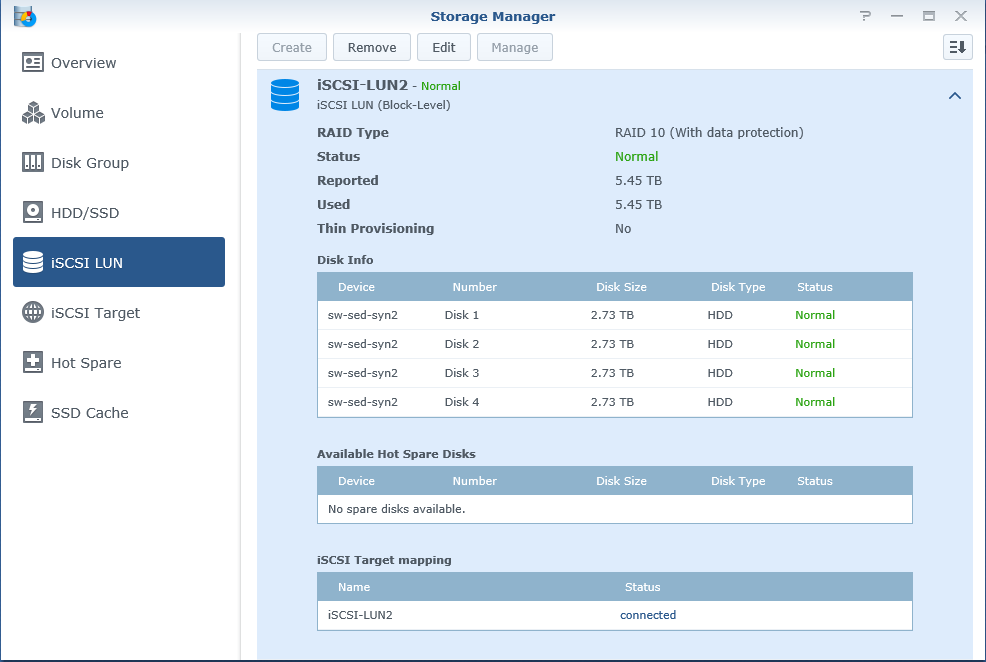
- Each Supermicro server is connected to iSCSI LUN via 2x 1GbE NICs
- “iSCSI-LUN1” is mounted on Supermicro1
- “iSCSI-LUN2” is mounted on Supermicro2
- iSCSI LUNs are used as a storage for StarWind HA device
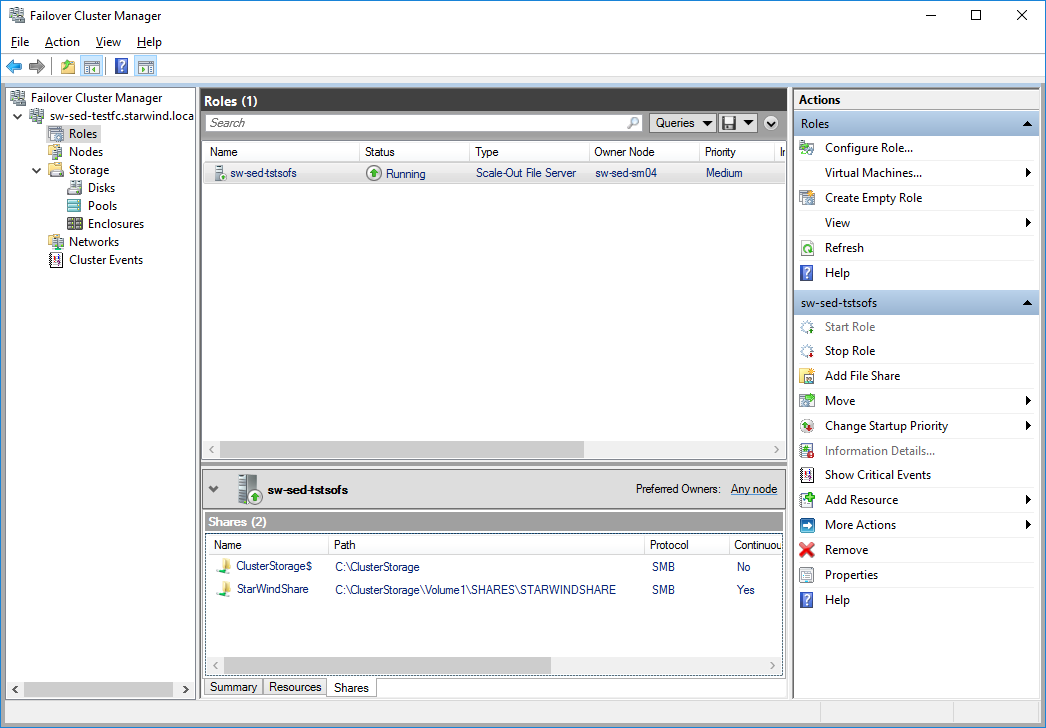
- StarWind HA device is mounted via iSCSI through 10GbE network and loopback on both hosts and added as Cluster Shared Volume (“StarWind CSV”) to Windows Failover Cluster
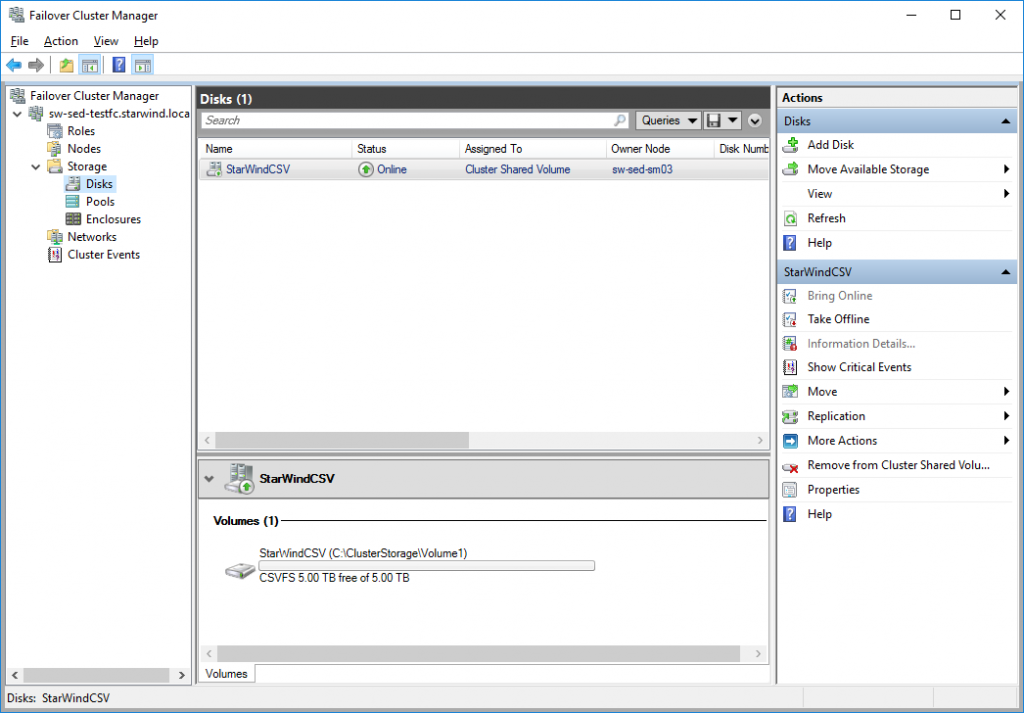
- Scale-Out File Server role is deployed inside Failover Cluster
- File share is created on top of Cluster Shared Volume (“StarWindShare”)
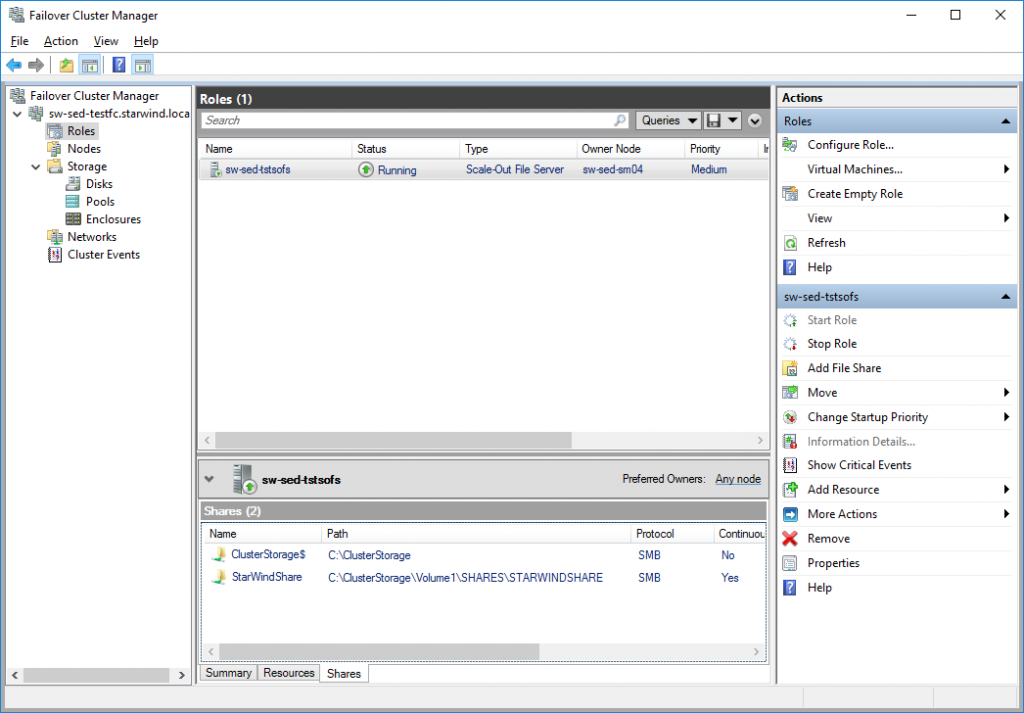
- “SynologyShare” is mounted on the remote client host
StarWind HA Device settings:
- Type: Imagefile
- Size: 5TB
- L1 cache: no cache
- L2 cache: no cache
1st test case: “Soft” failover in StarWind HA Cluster
In order to compare VSAN from StarWind and Synology DSM HA Cluster, we are repeating our tests starting from the “soft” failover. The procedure will be a bit different this time: while copying a test file from the remote client to “StarWindShare”, we will stop VSAN from StarWind Service on one of the Supermicro servers. Essentially, this is the “softest” way of interrupting StarWind cluster.
When StarWind Service goes down on one of the nodes, partner server stays active and keeps the corresponding iSCSI target alive.
Using VSAN from StarWind as “active-active” HA storage provider, we are able to benefit from Multipath I/O not only in terms of performance. “Round Robin” MPIO policy allows utilizing all available paths simultaneously, which, in conjunction with StarWind “active-active” model, should decrease the failover duration. Thus, in the case of failure, MPIO will mark unavailable paths as “dead” and continue using active ones.
With this information in mind, we are moving forward to perform the test.
Highlighted part of the progress bar indicates the failover period. As you can see from the progress bar, “StarWindShare” performs significantly better thanks to MPIO and increased throughput. What is more, the data transfer consistency is also better if compared to “SynologyShare”:
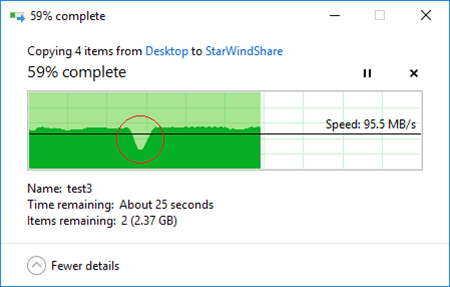
The total failover duration in case of “soft” failover with VSAN from StarWind was 10 seconds.
This is a great result which means that most virtual machines stored on “StarWindCSV” will survive the failure without encountering any issues.
2nd test case: “Hard” failover in StarWind HA Cluster
Continuing our research, we are going to perform the “hard” failover within VSAN from StarWind setup. Test sequence stays the same as in the 2nd test case with Synology DSM HA: we are simulating the power outage on one of our DS916+ units by pulling out the power cord while transferring some files to “StarWindShare”.
StarWind Service is not able to monitor Synology’s current state, thus, the only indication for StarWind that something went wrong, would be the underlying storage outage.
In case of underlying storage failure, StarWind Service detects that storage is no longer available and marks the corresponding device as “Not Synchronized”, at this point StarWind breaks synchronization and stops sharing the iSCSI target of the damaged device. At the same time, healthy node keeps working and stays in “Synchronized” state, thus, corresponding iSCSI paths stay alive as well.
Highlighted part of the progress bar indicates the failover period:
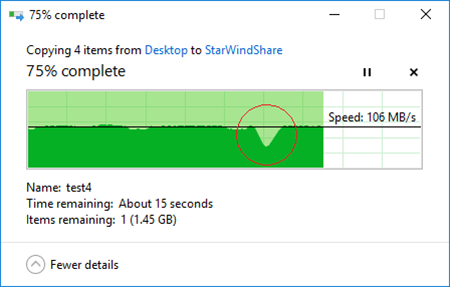
This time failover took 20 seconds to complete. Some extra time was consumed by StarWind Service to detect the underlying storage absence. This is a great result which means that virtual machines stored on StarWind device would be able to continue running without errors.
Summarizing the results:
Here you can see a comparison chart which represents the difference in failover duration between Synology DSM HA Cluster and VSAN from StarWind:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion:
Today we have performed a set of simple failover tests to determine whether Synology DSM HA Cluster is capable of handling power outage or similar emergency cases in a timely manner.
In order to better interpret the achieved results, we should mention the Disk Timeout parameter which is present in most modern operating systems. Basically, this parameter dictates how long OS waits for an I/O request before aborting. If underlying storage stays offline for a period that is longer than Disk Timeout value, it may lead to various errors or even OS crash.
Default Disk Timeout values for some operating systems:
Windows Server 2016 = 65 seconds
Windows 8, 10, 2012, 2012R2 = 60 seconds
CentOS 7 = 60 seconds
Red Hat Enterprise Linux 7.2 = 30 seconds
While operating system itself has a Disk Timeout parameter, I/O timeouts are present in most of the applications that continuously work with any type of storage. For example, SQL Server will consider any I/O request which processes longer than 15 seconds as incomplete and would accommodate it to a “pending” queue. However, we are talking only about emergency cases, since average healthy latency of SQL transactions should not exceed 20-50 ms.
Now let’s analyze the results summary.
As we can see from the chart numbers, failover duration with Synology DSM HA Cluster takes significantly more time if compared to VSAN from StarWind HA configuration. However, speaking about virtual machines, most of them should be fine during the DSM HA Cluster failover, since the maximum duration of 55 seconds is lower than Disk Timeout values of most operating systems. Obviously, Disk Timeout can be increased for all virtual machines that would reside on this storage, however, the general rule here is “Less is better”. In most cases, we do not recommend to set this value higher than 65 seconds.
Nevertheless, we discovered that VSAN from StarWind provides a great possibility of significantly decreasing the failover period. The maximum failover duration in StarWind HA configuration was 20 seconds, which is a good result, meaning that virtual machines would have better chances of surviving the storage outage if compared to Synology HA Cluster configuration.