

What? Where? When?
Before the time when SSDs took their irreplaceable place in the modern datacenter, there was a time of slow, unreliable, fragile, and vacuum filled spinning rust drives. A moment of change divided the community into two groups – the first with dreams of implementing SSDs in their environment, and the second, with SSDs already being part of their infrastructure.
The idea of having your data stored on the associated tier has never been so intriguing. The possibility of granting your mission-critical VM the performance it deserves in the moment of need has never been more appropriate.
By breaking down your mixed storage environment into multiple tiers it would be possible to reap the benefits of each tier when required. The possible configurations span from implementing from 2 to 5 tiers, where the configuration of more than 3 – is highly overrated.

After the announcement of the performance benefits of NVMe drives the difficulties of mixing and matching storage within your environment went into a downwards spiral.
Hands-on
The goal of improving the performance of your mixed storage environment starts with questions of management. Depending on the environment, some cases would require manual migration of data between tiers, and end with the creation of multiple conflicting policies. Not necessarily something that everyone is looking forward to but even if it’s highly eliminated, it is always an option.
A case where the management aspect can be set aside is worth the never-ending process of research along with trial and error. Results of such determination can cripple the performance of the data which is stored on one of the tiers at any given moment. Either the case, it’s really a matter of the maximum utilization of SSDs, which is something that is quite difficult to get right.
After a single division of groups, there is an additional division into more subgroups. The first contains the people that run their whole environment on all-flash arrays, and the second – people making a transition between the two. The complexity of the policy creating process and the number of people involved may lead to nightmares.
There are cases when your data can migrate from the hot tier to the cold overnight, leaving you with a process to begin your day with. The morning migration process of your data from the cold tier to the hot may take several hours and may leave the availability of your data at risk, and your legs shaking. Finding the sweet spot is exactly what makes the process of improving the utilization of your storage a pain.
Hands-off
The implementation of tiered storage can be considered as a cure for the call of the desperate. A main difference between the various available options is the architecture behind the process. With the implementation of any kind of tiering functionality, something to watch out for is the trigger from migrating your data from the hot to the cold and vice-versa.
The implementation of a solution like VSAN from StarWind can be considered a blessing to those stranded in the same boat and drowning in all the FUD.
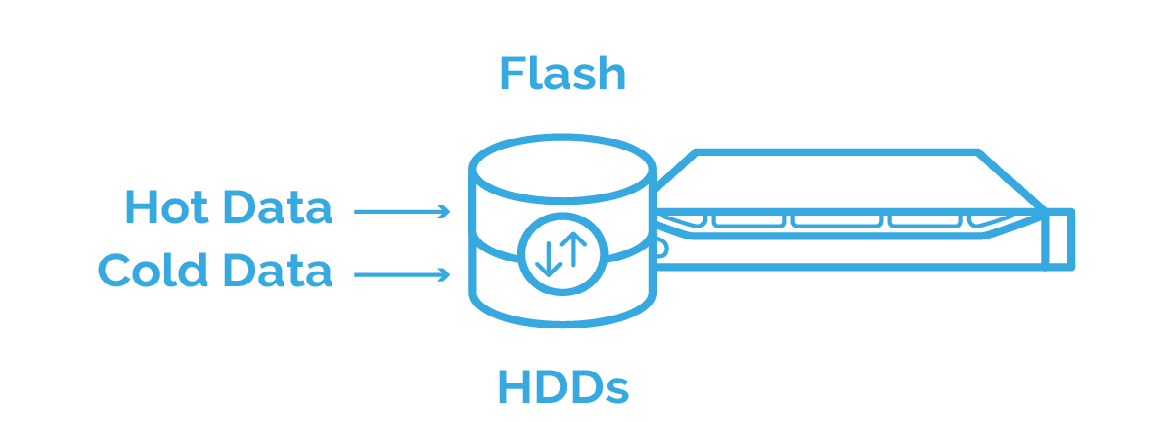
Depending on your scenario requirements, there will always be an option of specifying the amount of storage you’re willing to allocate to each tier.
Once configured, it provides the option of creating a single storage volume and spanning it over all your mixed underlying storage components, making an automated tiering architecture a part of your environment.
No hands
As you can see, there really is no difference between the amount of locally available storage types – the configuration of automated storage tiering will improve the utilization of your storage. For the elimination of any uncertainty of the availability of your mission-critical data within your environment, the implementation of a single solution can be a real game-changer and open boundaries you were previously limited by.
