

Why do we always see Responder CQE Errors with RoCE RDMA?
Anyone who has configured and used SMB Direct with RoCE RDMA Mellanox cards appreciates the excellent diagnostic counters Mellanox provides for use with Windows Performance Monitor. They are instrumental when it comes to finding issues and verifying everything is working correctly.
Many have complained about the complexity of DCB configuration but in all earnest, any large network under congestion which needs specialized configurations has challenges due to scale. This is no different for DCB. You need the will to tackle the job at hand and do it right. Doing anything at scale reliable and consistent means automating it. Lossless Ethernet, mandatory or not, requires DCB to shine. There is little other choice today until networking technology & newer hardware solutions take an evolutionary step forward. I hope to address this in a future article. But, this I not what we are going to discuss here. We’ve moved beyond that challenge. We’ll talk about one of the issues that confuse a lot of people.
The thing is, even with a perfectly working RoCE/DCB setup, when everything is working fine, you might see one error counter stubbornly going up over time. That’s the “Responder CQE Errors” counter.
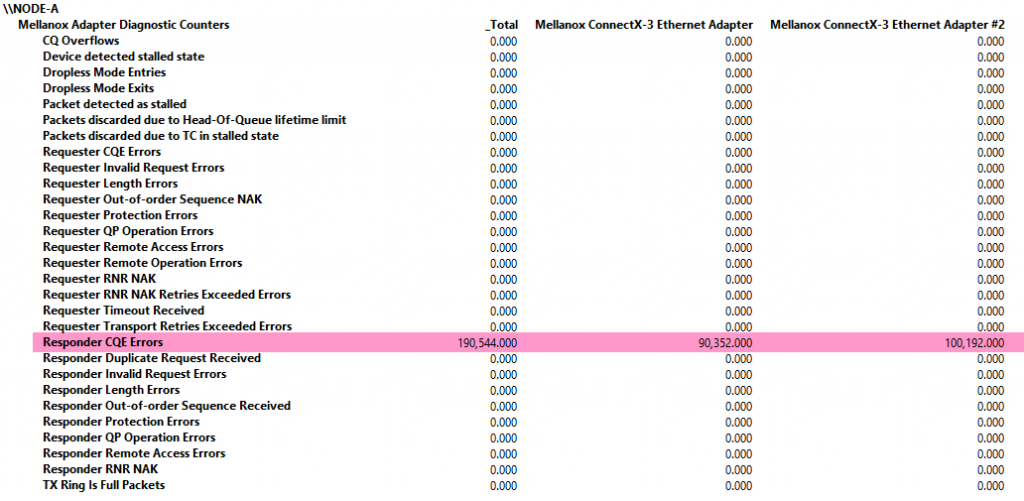
The picture above is a typical example of what it looks likes after some live migration of virtual machines from Hyper-V cluster Node B to Hyper-V cluster Node A. It has led many people to believe something is still wrong even if all other counters stay zero (on a cleared system, which means a rebooted one). They see that every works but they keep digging, worrying and doubting if bad thing will happen to their SMB Direct data.
I have good news for you. If all else is in order, this is perfectly fine, normal and expected. Awesome, right?! But why are we seeing an error counter go up then? And why only that one?
Mellanox states the following in How to Configure SMB Direct (RoCE) over PFC on Windows 2012 Server
Note: “Responder CQE Error” counter may raise at an end of SMB direct tear-down session. Details: RDMA receivers need to post receive WQEs to handle incoming messages if the application does not know how many messages are expected to be received (e.g. by maintaining high-level message credits) they may post more receive WQEs than will actually be used. On application tear-down, if the application did not use up all of its receive WQEs the device will issue completion with the error for these WQEs to indicate HW does not plan to use them, this is done with a clear syndrome indication of “Flushed with error”.
Today well tray to explain why we always see Responder CQE Errors with Mellanox RoCE RDMA card performance counters. To do so, we need to dive a bit deeper (but not too deep and without all the details and the options as that would take us too long and make us go too far) in to how RDMA works.
RDMA Basics
The big difference between RDMA & TCP is that TCP is stream based and when you send data between machines it doesn’t really care where it comes from in the app memory or needs to be written to in the app memory on the other side. The TCP/IP stack & OS will handle that.

The Mellanox Connect-X Pro 5 EN 100Gbps dual port RoCE RDMA card
Not so for RDMA, which is message based and actually needs to know where to read the data from the and where to write the data into the application memory. RDMA pins the application memory, containing data that needs to be moved to make sure it stays where it is. That memory is then mapped to the rNIC then sets up a “pipeline” that moves data bypassing the kernel completely. That’s the application memory to memory copy in the user space, buffer to buffer directly. The zero copy, kernel bypass, CPU offload magic so to speak. We’ll now look a bit more in detail at how that is done. The verbs API (OFED see https://www.openfabrics.org/index.php/openfabrics-software.html) is used to set this all up and what the NIC vendors, applications and operating systems that support RDMA program against. So how does the OS, the application and the hardware RDMA capable NIC (rNIC) achieve this?
A tale of 3 Queues: one pair of read/write queues and one completion queue.
Actually, there is a lot more (detail) to the tale than this, but this isn’t a thesis on RMDA verbs  . That’s why this “tale” is more conceptual than academic. Let’s keep it as simple as possible on a level that I understand. The application memory RDMA needs to read/write is pinned to the physical memory telling the kernel what memory is owned by the applications that support & use RDMA. Hyper-V with live migration over SMB is a prime example. This involves the OS/kernel and is needed to make sure the data in that memory will be controlled by the rNIC, not the operating system. This prevents it from being paged away etc. The rNIC is told to address that memory directly and to do so it sets up a direct “pipeline” from the rNIC to that memory. This is called registering memory regions. That channel is the kernel bypass highway from the RDMA NIC over the PCI bus to the application memory. The registered memory regions and the data in those regions, buffers, can now be used by 3 types of queues.
. That’s why this “tale” is more conceptual than academic. Let’s keep it as simple as possible on a level that I understand. The application memory RDMA needs to read/write is pinned to the physical memory telling the kernel what memory is owned by the applications that support & use RDMA. Hyper-V with live migration over SMB is a prime example. This involves the OS/kernel and is needed to make sure the data in that memory will be controlled by the rNIC, not the operating system. This prevents it from being paged away etc. The rNIC is told to address that memory directly and to do so it sets up a direct “pipeline” from the rNIC to that memory. This is called registering memory regions. That channel is the kernel bypass highway from the RDMA NIC over the PCI bus to the application memory. The registered memory regions and the data in those regions, buffers, can now be used by 3 types of queues.
Simplified for the purpose of explaining the error counter going up, all RDMA communication is based on 3 queues. A pair of queues that exists of a send and a read queue. These two queues are always created as a pair and they serve to schedule the actual work. That pair is also called the queue pair (QP). Then, there is the Completion Queue. The name gives it away, it’s used to notify us that the work queues have finished a job. And yes, that’s related to the Responder CQE Errors counter that you see go up. We’re getting there, stick with me!
Work Requests, Work Queue Elements and Completion Queue Elements
When an application wants to move data over (Hyper-V live migration for example) it tells this to the RDMA NIC that translates work request (WR) into work queues (WQ). This is done by placing instructions into the respective send or receive queues telling the rNIC what memory buffers form the registered region it wants to send or receive. Those instructions are called Work Queue Elements (WQE). A WQE contains a pointer to the memory buffer. When it’s a send queue it points to data to be sent over to the other side. In the case of a receive queue, it points to the memory buffer where the data will be written to. This is a big difference with TCP/IP. TCP/IP just streams data back and forward without having to worry where that data will need to be written in the memory. RDMA knows.
The entire process of moving data with RDMA is actually asynchronous. A bunch of send and receive WQE are placed on the respective queues at any given time and the rNIC will handle these, in order, as fast as it can. That means processing the instruction and moving the data. Once a WQE is handled and the transaction is finished Completion Queue Element (WQE) is created and put into the Completion Queue (CQ). Yes, that’s where see our WQE of our diagnostic counter come into play. The application (consumer) polls the Completion Queue to retrieve the CQE which are than translated to Work Completions (WC). When the work is done, the pinning of memory and the registered memory regions can be torn down etc. Rinse and repeat.
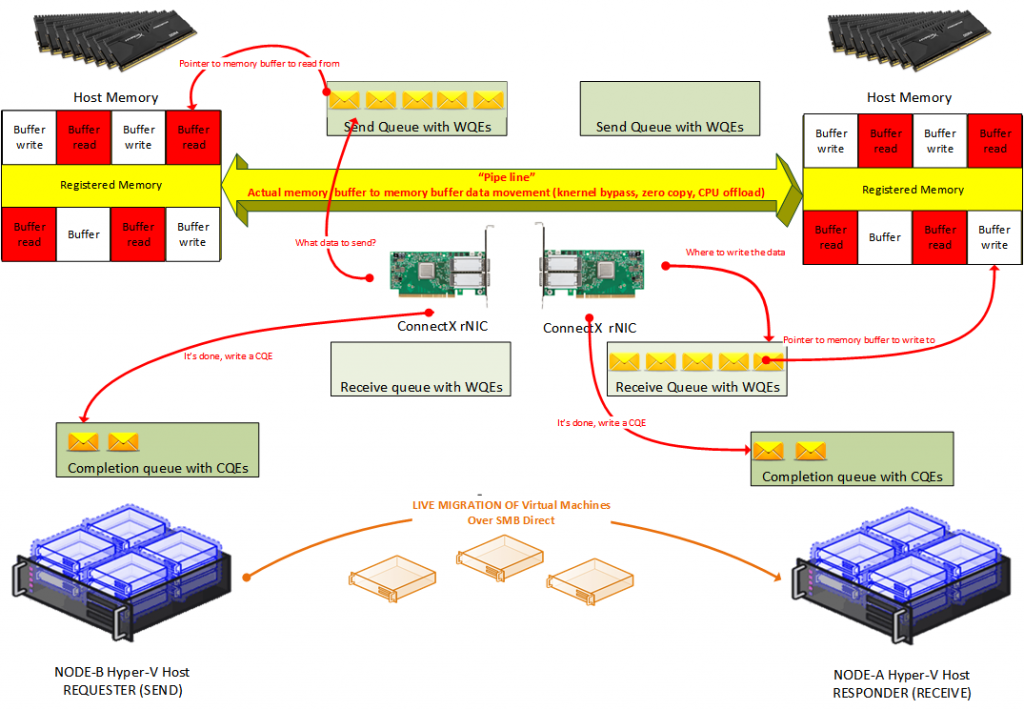
What causes the “Responder CQE Errors”?
When an instruction is completed successfully this doesn’t cause an error. That only happens when something goes wrong (you reboot a node, a cable fails, something isn’t configured correctly). But hey, we see the errors counter go up anyway when nothing goes wrong. So, what ‘s up? Well, the Responder CQE Error counter may very well go up after finishing an SMB session. The RDMA receivers (responder) needs to put receive WQEs into the receive queue to handle incoming messages. When the application does not know how many messages it will receive, it gives a large enough number of “message credits” to the sender side. Hyper-V live migrations, which are a bit of a moving target due to the VM activity between starting live migration and finishing one, are a prime example of this. This means the application might post more receive WQEs on the receive queue than will ever be used. If the live migration did not use up all of its receive WQEs the rNIC will generate a completion with the error for these WQEs which signals that the rNIC won’t use them and they are flushed with the error. However, that does not mean RoCE RDMA is not configured properly or failing.
Hey, we got there in the end! I hope this helps you understand it a bit better.

{kind=link}
{kind=link}