StarWind Virtual SAN: Clustering as the Key for High Availability
- September 20, 2018
- 12 min read
- Download as PDF
Introduction
When it comes to starting a business these days, there’s almost no chance to avoid any IT technologies alongside with it. Generally, each company, will it be a bakery, a law agency or a charity organization etc., is in touch with computers. Starting from simple desktops and applications, IT-related stuff goes all the way up to massive datacenters and complicated computing systems.
It is no secret that different technologies must work together in order to create a unified business solution. Besides, running each single application or service on its own computer or server will make the infrastructure massive in terms of size and costs.
Moreover, the question of data availability becomes more and more frequent each year. Many organizations in the world provide 24/7 services for their customers, thus these services must run fast and without any downtime. Slowing down the business may lead to a catastrophic outcome.
Taking into account all the above-mentioned requirements, it becomes clear that the whole production must work as a single unit, gathering all available resources into a ‘hive mind’. In other words, clustering them.
What is Clustering?
Generally, a cluster is a group of independent computers working together as a single system to ensure that all mission-critical applications and resources within the infrastructure are as highly-available as possible. The group of computers is managed as a single system, it shares a common namespace, and it is specifically designed to tolerate component failures. The cluster supports adding or removing components in a way that’s transparent to users.
The common concept in clustering determines several nodes that become members of the cluster and are either active or passive. Active nodes are running applications or services while passive nodes are in a standby state communicating with the active members. In the event of a hardware or software failure, a passive node becomes active then and starts running services or applications.
One of the important steps to understand how the cluster works is to define the terms of reliability and availability.
Reliability. Almost all computer components are rated using the Mean time before failures (MTBF). Things go even hotter speaking about the components with moving parts, such as hard disks and fans. Of course, it is just a matter of time when they fail. Based on the MTBF numbers, it is possible to compute the probability of a failure within a certain time frame.
Availability. Using the example of a hard disk, which has a certain MTBF associated with it, you can also define availability. In most organizations, common users do not pay much attention to hardware devices. The only thing they expect from the infrastructure is accessing the service or application which they need to perform their jobs. Taking into account the fact that the hardware devices will fail at some point of time, administrators need to protect the infrastructure against the loss of services and applications that keep the business running. When it comes to hard drives, administrators can build Redundant Arrays of Independent Disks (RAID) that will tolerate failure of an individual component. Thus, the storage will keep providing the information requested by the client from another drive, which has an identical copy of the data. Availability is often measured using mean time to recovery and uptime percentages.
Clustering, at the most basic, is combining unreliable devices so that a failure does not result in a long outage and availability loss. In case of cluster, redundancy is at the server computer level, however, configured per service or application.
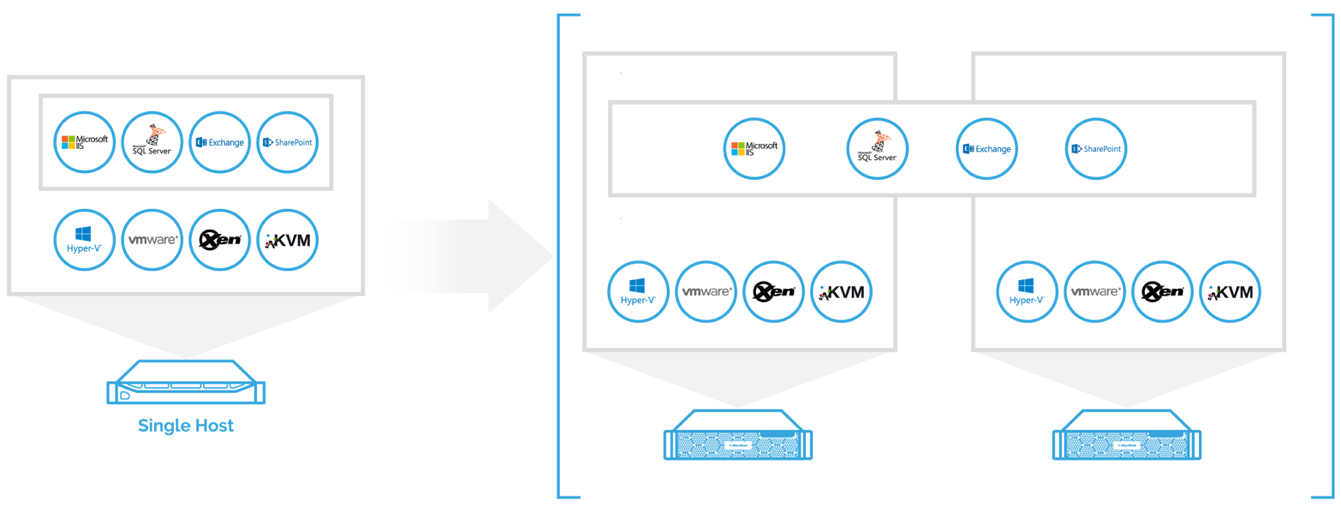 Clustering servers and creating shared storage between cluster nodes
Clustering servers and creating shared storage between cluster nodes
The cluster consists of at least two computers that are also known as nodes. An application or service can run on any node so that multiple applications or services can be spread out among all the nodes of a cluster making multiple nodes active in it. If one of the applications running on a single node fails, it will not affect the workability of other applications on the server. For example, a print server can run on the same node as a DHCP server, and if the DHCP service fails, it may not cause the print service to fail as well, if the problem is isolated to the DHCP server. In the event of a hardware failure, all applications and services will failover to another node.
Each cluster uses a physical storage of the cluster nodes. To be able to transfer the workloads between the nodes and provide access to all files from any server regardless of a physical location of the file, each of the nodes uses several network adapters. One of the network ports is used to connect the node to the network. Another network port is used to connect the nodes to each other via a private network. The private network is used by the cluster service, so the nodes can talk to each other and synchronize the data within the cluster.
There is also a heartbeat network, which helps to determine if the resources in the cluster fail to respond to the resource checks after an appropriate amount of time. Thus, the passive node will assume that the active node has failed and will start up the service or application running on a virtual server.
All nodes are also connected to shared storage media. In fact, the storage is not shared, but it is accessible to each cluster node. In active-active scenarios, all nodes have the same access to the storage, using the node priority for generating I/O. Learn how to create an active-active scenario with StarWInd Virtual SAN following this link.
What is Virtual Server?
The definition of a virtual server goes alongside with a traditional physical server. Generally, the virtual server simulates the physical server functionalities, sharing hardware and software resources with other operating systems. Instead implementing multiple dedicated servers within the infrastructure, numerous virtual servers may be gathered on a single physical server.
The virtual server is almost the same as the physical server. It has the same hardware resources the physical server does, such as CPU, RAM, storage and networks. The only difference is that these hardware resources are rather virtual, assigned to the virtual server by the physical server it is running on. In case of cluster, the virtual server uses cluster resources as well and can be moved across the physical nodes. An ability to migrate between different physical servers will come in handy in case of any server maintenance or hardware malfunctions appear.
From the user perspective, the virtual server works in the same way the physical server does supporting applications and services.
Why Use Clustering?
There are several major benefits of running services and applications on a cluster, such as increasing availability of a service and reducing the downtime caused by maintenance.
Increasing uptime and availability of a service, application or role should always be a goal of an information technology department. By having the cluster service monitoring the production workload, any failures can be quickly identified, and the service or application can be moved to another node in the cluster within moments. In many cases, a failing service or application can be restarted on a surviving node in the cluster so quickly that nobody will even notice that it has failed. Users can continue accessing the service or application and will not have to call the help desk to notify the information technology department that it has failed. Moreover, they will be able to do their jobs without having to wait for the service or application to be reviewed by the system administrator and then wait for it to be fixed. In other words, it leads to increased productivity.
Software and hardware maintenance time can be reduced considerably in the cluster. Patching and upgrading services and applications on the cluster are much easier in most cases. In the cluster, software and hardware maintenance can be done after being tested in a test environment. Maintenance can be done on a passive node without impacting the services and applications running on the cluster. The active node will just continue running during the maintenance of the passive node.
If maintenance is also required on the active node, it is a simple matter to move the service or application to the passive node, thus making it the active node. If, for some reason, the service or application fails, it always will be an option to move it back to its original node, and then troubleshoot any problems that may come up without having the clustered service or application unavailable.
If there are no problems with the maintenance work, then the other node can be upgraded/fixed as well. This process also works with installing simple operating system patches and service packs. The downtime associated with maintenance is reduced considerably and the risk associated with such changes is also reduced.
Conclusion
Since the IT industry crossed paths with the world of business, the use of different applications and services has become a standard even within the smallest companies. Continuous production growth requires more and more compute and storage resources, thus clustering all available IT infrastructure components is a must.
Running applications and services in a cluster will not only make the configuration solid and more comfortable to use. Clustering will allow administrators to add another security level to the system by sharing the data between all cluster nodes. In case of any component failure, the infrastructure will move all services to another node, thus minimizing the production downtime and guaranteeing continuous data availability.
